En este apartado mostraremos la implementación de la ontología de conceptos que hemos venido mencionando y cuyo punto de enlace con la información léxica contenida en la base de datos acabamos de mostrar. Ya apuntábamos en el apartado 3.3.6 que esta ontología no ha sido creada por nosotros, sino que, tomando la ontología del proyecto de KBMT Mikrokosmos, la hemos adaptado para utilizarla en conjunción con nuestra base de datos.
En primer lugar hemos de mencionar el hecho de que la idea original de incluir una base de conocimiento en el sistema global de representación de lenguaje natural ideado para el proyecto en el que el presente trabajo se ha desarrollado no es nuestra, sino que, desde un principio, el investigador principal del proyecto contemplaba la necesidad de este tipo de repositorio (Martín Mingorance 1993, 1995). Nuestra aportación en este sentido ha consistido en concretar el modo la integración de esta base de conocimiento con el lexicón multilingüe que hemos descrito.
Sin embargo, la base de conocimiento que proponemos es de una naturaleza diferente a la propuesta por Martín Mingorance. En la idea original, esta base de conocimiento se contemplaba como un repositorio de conocimiento netamente enciclopédico (Martín Mingorance 1993). En este sentido, se considera una división tajante entre conocimiento léxico y conocimiento del mundo. Nuestra concepción es un tanto diferente, en cuanto que contemplamos la ontología como un recurso de apoyo a la información contenida en la LDB, enfocado sobre todo a utilizar dicha información en un sistema de traducción automática basado en el conocimiento. Esto quiere decir que nuestra base de conocimiento contiene información mediante la cual los lexemas contenidos en la base de datos, donde ya poseen una descripción precisa en cuanto que objetos lingüísticos, son localizados en una intrincada jerarquía conceptual, la ontología. Ésta, por tanto, no habrá de ser considerada como un repositorio de conocimiento del mundo o conocimiento enciclopédico, sino como un recurso que permite estructurar una conceptualización del mundo determinada y cuyo objetivo fundamental es el de servir de intermediario entre distintas lenguas en un sistema de KBMT.
Éste es el principio fundamental de la semántica basada en ontología: basar los significados de las unidades léxicas en un sistema de símbolos estructurado que contiene una interpretación determinada y con una motivación independiente (Nirenburg, Raskin & Onyshkevych 1995). Esto no quiere decir que no exista la posibilidad de convertir nuestra ontología de conceptos en una base de conocimiento enciclopédico.
Esto es más que posible utilizando un esquema de representación basado en marcos. Este esquema de representación ha sido propuesto por los principales investigadores en el campo de la construcción de ontologías para convertirse en estándar de representación del conocimiento con el fin de asegurar su reutilización (Gruber 1993a, 1993b). Aunque todavía no existan estándares generalmente aceptados, los esfuerzos en este sentido son muchos, comprendiendo desde el formato (KIF: Knowledge Interchange Format) (Genesereth & Fikes 1992), (GFP: General Frame Protocol) (Fikes et al. 1991; Allen 1993) hasta el lenguaje de consulta y manipulación (KQML: Knowledge Query and Manipulation Language) (Finin et al. 1992).
Sin embargo, es ésta una labor que queda más allá de las miras del presente trabajo, donde únicamente tratamos de esbozar un posible camino a seguir en lo que respecta a la conexión de los objetos lingüísticos con los conceptos que éstos pretenden designar, pero no con los entes del mundo real denotados8.
Creemos necesaria una aclaración de lo que entendemos por "ontología", en el sentido general, no únicamente en el campo de la KBMT. El desarrollo de ontologías es un amplísimo campo de investigación en sí mismo, donde se combinan esfuerzos provenientes de campos tan dispares como la lingüística, la informática, la IA y la filosofía. No es el objetivo de este trabajo realizar una aportación en este campo, sino tan sólo sacar provecho de los esfuerzos realizados en el mismo.
Como recuerda Gruber (1993b) la palabra "ontología" ha generado mucha controversia en las discusiones sobre Inteligencia Artificial y tiene una larga tradición en la filosofía, donde se usa para hacer referencia a temas relacionados con la existencia. También se ha confundido a menudo con la epistemología, que tiene que ver con la esencia del conocimiento. En el contexto de la KBMT y de la representación del conocimiento en general, la ontología supone el enlace entre los símbolos del lenguaje natural y las entidades del mundo real que éstos representan. En este sentido se puede considerar como "una especificación de una conceptualización" (Gruber 1993b). Como vimos en el capítulo anterior, esta especificación ha sido objeto de un gran esfuerzo por parte de los investigadores de IA, que desde hace varias décadas se vienen esforzando por conseguir una que ofrezca la suficiente flexibilidad para poder representar el conocimiento complejo que la mente humana emplea. Casi la totalidad de las propuestas para una estandarización de la representación del conocimiento coinciden en utilizar los marcos como mecanismo básico.
La palabra "conceptualización" es especialmente relevante en este contexto, ya que se refiere a los objetos, conceptos y otras entidades que existen en un área de interés determinado y las relaciones que mantienen entre ellos (Genesereth & Nilsson 1987). Por lo tanto, cabe hablar, por ejemplo, de una ontología para conceptos matemáticos (Gruber & Olsen 1994), donde los conceptos representados son cantidades vectoriales, unidades de medida, funciones, etc. Hemos de tener en cuenta que una "conceptualización" es en cierta medida una "simplificación de un mundo que se desea representar para algún propósito" (Gruber & Olsen 1994). Este propósito puede ser las matemáticas, la traducción o cualquier otro. Existen ontologías en formato KIF (Knowledge Interchange Format, Genesereth & Fikes 1992) con conceptualizaciones sobre submundos tan variados como vehículos, compuestos químicos, documentos, información bibliográfica, etc.
De hecho, una de las más importantes iniciativas para la creación de ontologías, el Knowledge Systems Laboratory de la Universidad de Stanford, permite la creación de ontologías de forma interactiva a través de la red mediante el KSL Ontolingua Server y pone a disposición de cualquier usuario las ontologías generadas mediante su sistema9.
Nuestro submundo, la "conceptualización" de nuestra ontología, es el de los conceptos generales (es decir, no específicos de un campo conceptual especializado) en cuyos términos comprendemos el lenguaje y está enfocado a servir de complemento a una base de datos léxica y de conexión conceptual entre distintas lenguas. Por tanto, a diferencia de estas ontologías específicas, la ontología de Mikrokosmos es, como ya hemos mencionado, un repositorio a gran escala, contando con casi 5.000 conceptos y partiendo de tres categorías conceptuales básicas: evento, objeto y propiedad.
En el apartado 3.3.6, ofrecimos una descripción general de esta ontología y definimos sus implicaciones en un sistema de KBMT, así como el papel concreto que juega en el sistema Mikrokosmos. El aprovechamiento que nosotros proponemos de este recurso es similar, sólo que adaptado al tipo de lexicón computacional multilingüe que hemos presentado.
Al igual que otros muchos investigadores en el campo del procesamiento del lenguaje natural10, creemos que en la traducción automática, un recurso computacional de estas características puede aportar grandes ventajas con respecto a sistemas basados exclusivamente en un lexicón. Nirenburg, Raskin & Onyshkevych (1995), sin duda los investigadores en el ámbito de la Traducción Automática que más abiertamente abogan por la semántica basada en ontología, destacan las siguientes:
También mencionábamos que no existe una metodología definida para la creación de ontologías, es decir, no existe un algoritmo que permita la adquisición de conceptos. Lo que sí existen son un número de "líneas maestras" desarrolladas a partir de la experiencia acumulada por los investigadores en el campo. Una ontología de este tipo se adquiere de forma incremental, a través de una interacción continua con otras fuentes de conocimiento, lo que da lugar a un desarrollo en paralelo de ontología y lexicón. El método ideal de desarrollo de ontologías para su uso en KBMT contempla el desarrollo en paralelo de una ontología y dos o más lexicones (Mahesh 1996); esto facilita la independencia de la lengua de los conceptos contenidos en la ontología, y garantiza que las necesidades de representación de las lenguas descritas en los lexicones son cubiertas.
Un concepto interesante que defienden los creadores de la ontología de Mikrokosmos es el de "ontología situada". Con ello se refieren al hecho de que la creación de una ontología debe estar enfocada a la realización de una tarea concreta, dentro de un ámbito bien definido y diseñada para trabajar de forma conjunta con unas herramientas determinadas. Pensemos en la ontología de Cyc, anteriormente mencionada, como ejemplo opuesto de ontología de propósito general. Una ontología situada, implica que sólo se añadirán aquellos conceptos que sean necesarios para la tarea que se pretende llevar a cabo. Esto implica la existencia en la ontología de Mikrokosmos de algunos conceptos muy específicos y la ausencia de otros, como se puede ver en el Apéndice III.
En este orden de cosas, los investigadores de Mikrokosmos han propuesto una serie de recomendaciones a seguir para la inclusión de nuevos conceptos en la ontología (Mahesh & Nirenburg 1995a, 1995b, Mahesh 1996). Como estos autores afirman, esta lista no está cerrada, sino que sigue aumentando y refinándose con la experiencia acumulada. Las más importantes son las siguientes:
En general, hemos intentado respetar estas recomendaciones en los conceptos que hemos añadido a la ontología para nuestra implementación, aunque la motivación de su introducción se ha debido a un estudio lingüístico de un campo léxico concreto, más que a su aplicación directa a la traducción automática.
En este sentido, resulta muy interesante comprobar cómo un estudio previo de un conjunto de lexemas que mantienen ciertas relaciones de significado entre sí (es decir, un campo léxico) siguiendo el método de análisis del FLM puede arrojar muchas pistas sobre qué conceptos incluir en una ontología. Volveremos a mencionar esta interesante característica en el siguiente apartado.
Para mostrar el modo en que una ontología puede ser utilizada en conjunción con un lexicón altamente estructurado como nuestra LDB, en este trabajo hemos investigado la repercusión de la introducción de la ontología en tres aspectos muy concretos en lo que se refiere al análisis automático del lenguaje natural en general y a la traducción automática en particular, aspectos que ya hemos dejado entrever durante la descripción de la base de datos. Nos referimos a los siguientes:
Para demostrar la validez de estas afirmaciones hemos tomado el campo léxico de los verbos de sonido en inglés y español, analizado por los miembros del grupo de investigación en el que el presente trabajo se ha desarrollado, según la metodología del FLM y hemos introducido la información en la base de datos según el esquema que presentamos en el apartado 5.2. A continuación hemos establecido los enlaces con la ontología en los tres aspectos que acabamos de mencionar.
Pudiera parecer un contrasentido el hecho de que, puesto que pretendemos sustituir la representación basada en campos léxicos entendidos según los supuestos de la semántica estructural y de la descomposición léxica gradual, hayamos utilizado, precisamente, un campo léxico estructurado según estas metodologías para mostrar la superioridad de la representación mediante conceptos ontológicos. Sin embargo, es precisamente de este modo como se evidenciará la validez de nuestras tesis. Además, tenemos que incidir en el hecho de que nuestras propuestas están enfocadas exclusivamente al ámbito de la representación léxica con fines de NLP. Es decir, defendemos la inclusión de la ontología como solución a los problemas de representación formal que hemos detectado en el FLM como sistema de representación, y que impiden la aplicación de la información léxica adquirida mediante este modelo a tareas computacionales, sobre todo a la traducción automática. Pero de ningún modo pretendemos negar la enorme validez del modelo en conjunto como metodología de análisis léxico.
De hecho, no hubiésemos podido obtener información léxica alguna que modelar de no ser por este modelo de análisis. No sólo esto, sino que, además, trataremos de demostrar cómo esta metodología puede servir para la determinación de los conceptos ontológicos mismos, ya que impone en el lexicógrafo una profunda reflexión sobre el significado de los lexemas, así como de las relaciones entre éstos, lo que lleva a un conocimiento muy certero de los conceptos últimos que subyacen a las unidades léxicas analizadas. Puesto que, como ya hemos mencionado, no existe ninguna metodología para la adquisición de conceptos ontológicos, pensamos que esta posibilidad debería ser estudiada en profundidad en futuros trabajos de investigación.
La asignación de conceptos ontológicos, tanto a predicados verbales como a argumentos, se ha realizado de forma manual. En el ámbito de la KBMT han existido iniciativas para llevar a cabo este tipo de tarea de forma automática (Okumura & Hovy 1994), pero, como estos mismos autores afirman, sus esfuerzos no han producido los resultados esperados. Además, puesto que la realización del proyecto en el que este trabajo se enmarca se ha realizado de forma manual, incluyendo la populación del lexicón, pensamos que ésta es la forma más coherente de establecer la conexión ontológica.
Antes de describir los resultados obtenidos, describiremos la herramienta que nos ha permitido la implementación de la ontología, así como la forma de conexión con la base de datos.
La herramienta que hemos utilizado para implementar nuestra base de conocimiento es un toolkit para la gestión de sistemas expertos, denominado Flex, de Logic Programming Associates, que funciona sobre un Prolog de la misma compañía, LPA Prolog 3.5. El lenguaje de programación utilizado por Flex no es Prolog, sino un lenguaje especialmente desarrollado, denominado KSL (Knowledge Specification Language), en la línea de los lenguajes de representación del conocimiento clásicos como KRL o KL-ONE (ver apartado 4.3.2.3).
Flex ofrece la flexibilidad de los lenguajes basados en marcos, así como la potencia derivada de funcionar sobre un Prolog compilado (WAM) (ver apartado 4.4.5). Además de estos requisitos fundamentales, la elección de esta herramienta obedece a diversas razones, especialmente las siguientes:
La compatibilidad con Quintus Prolog, es sin duda la más interesante, porque nos garantiza la posibilidad de cambiar de plataforma de hardware en caso de que esto se haga necesario.
KSL es el lenguaje que Flex utiliza para definir los marcos,
reglas y procedimientos. El lenguaje es muy expresivo, al mismo tiempo que ofrece grandes
facilidades para su aprendizaje y lectura de código, al utilizar un conjunto de comandos
y una sintaxis parecida al inglés. De este modo, es fácil para el programador establecer
el sistema básico, mientras que el mantenimiento y actualización de la base de
conocimiento puede ser realizada por usuarios no expertos en programación. Añadir hechos
a una base de conocimiento KSL es tan fácil como expresar un nuevo marco, mediante la
palabra reservada "frame", señalar el o los padres en la
jerarquía de marcos (pues soporta herencia múltiple no-monotónica) y establecer los
valores locales por omisión, según el siguiente patrón.
frame FRAME is a PARENT1, PARENT2. PARENTn ;
default ATTR1 is ‘value’ and
default ATTR2 is {set, of, values} and
default ATTR2 is ANOTHER_FRAME and
default ATTRn is ... .
El compilador convierte la base de conocimiento Flex en
sentencias Prolog y compila el código resultante. En este ejemplo de patrón hemos
mostrado tres formas distintas de asignar valores a un determinado atributo. Vemos que al
igual que en las estructuras de rasgos (que no son más que una especialización, con
menos funcionalidades, de este tipo de esquema de representación), se pueden asignar
tanto valores simples (ATTR1), como valores complejos, no sólo como listas
de valores (ATTR2), sino con herencia de propiedades explícitas para un
determinado atributo (>ATTR3 tiene como valor un marco determinado
completo).
Además de la herencia para valores concretos, la herencia
múltiple para un marco completo está determinada por los marcos explicitados en PARENT1,
PARENT2, PARENTn. Los valores de estos padres serán heredados por este marco a no
ser que se explicite lo contrario (herencia no-monotónica), mediante los predicados
especiales "inherit ATTRx from FRAMEx" (herencia especializada) y
"do not inherit ATTRx" (herencia negativa y sobrecontrol).
Además de estas técnicas básicas para la especificación
de marcos, KSL posee la mayoría de las funcionalidades deseables en un lenguaje de
programación: expresiones condicionales, matemáticas y booleanas, estructuras de control
(if...then, repeat...until, while...do, for...do), etc. También se pueden imponer
restricciones sobre los valores de un determinado atributo, mediante la palabra clave
"constraint". Por supuesto, Flex implementa todas las
funcionalidades de los lenguajes de marcos clásicos que mencionamos en el apartado 4.3.2.3, es decir, los "demons" y
"watchdogs", además de reglas de activación de procesos (triggering),
fórmulas y comparaciones.
Como ya mencionamos en el apartado 3.3.6, el código original en el que la ontología de Mikrokosmos se encuentra disponible es Lisp11, por lo tanto, el primer paso en la adaptación de esta ontología a nuestro sistema ha sido convertir las cláusulas Lisp a cláusulas KSL. Esta adaptación ha sido realizada de forma semi-automática sobre un fichero de aproximadamente 1 megabyte en formato ASCII. Hemos querido mantener todos los marcos de la ontología original, incluso cuando muchos de ellos (los pertenecientes a los niveles más bajos en la jerarquía) son específicos del tipo de documentos que el sistema Mikrokosmos ha sido destinado a traducir (textos empresariales sobre fusiones y adquisiciones de compañías). Del mismo modo, hemos decidido mantener una auditoría estricta sobre los cambios realizados, no sólo para control interno, sino también para respetar la fuente original.
El código completo no será incluido en este trabajo, por razones obvias de tamaño. En el Apéndice III, incluimos únicamente los nombres asignados a los casi 5.000 marcos que conforman la ontología, utilizando la tipografía para mostrar las relaciones de herencia. La parte correspondiente a la emisión de sonido (la relevante a los predicados verbales que hemos introducido en la LDB), la mostramos en el apartado 5.5.
La facilidad de este lenguaje hace superflua la necesidad de un interfaz gráfico para la inclusión de nuevos marcos, aunque la creación de éste es un proyecto factible mediante las facilidades que LPA Prolog aporta. Lo que sí es deseable en este tipo de entornos es una herramienta que permita consultar la jerarquía en modo gráfico, ya que las jerarquías resultantes pueden llegar a contener miles de marcos, como es el caso de nuestra ontología. Flex aporta tal tipo de herramienta. Una vez compilado en memoria el fichero fuente con la colección de marcos, es posible "navegar" a través de la jerarquía mediante la herramienta que Flex incorpora. En primer lugar se selecciona un marco a partir del cual se mostrará la jerarquía, como se muestra en la Figura 5.25.
Figura 5.25 Selección de marco en el interfaz gráfico de Flex
Tras seleccionar el marco de partida podemos elegir ver el gráfico de marcos y se nos muestra una ventana como la de la Figura 5.26, donde podemos observar los marcos superiores en la jerarquía de conceptos.
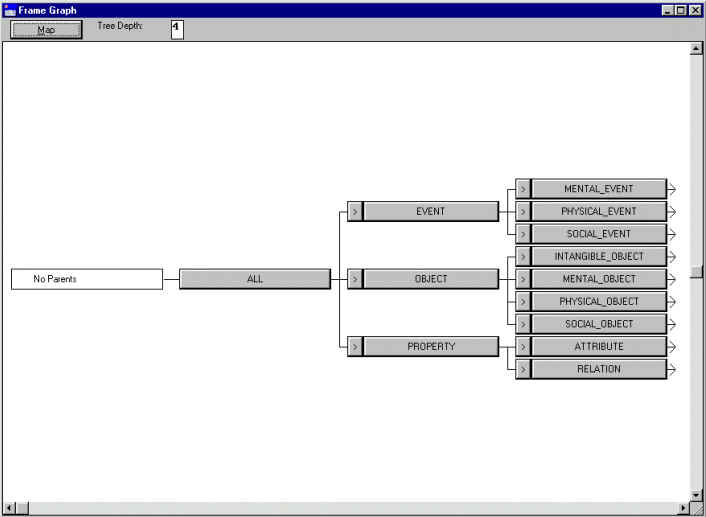
Figura 5.26 Gráfico Flex con los niveles superiores de la ontología
Como se puede ver en esta ilustración, se puede elegir la profundidad de ramificación de niveles (hasta un máximo de nueve), aunque para una jerarquía de estas características resulta imposible trabajar con una profundidad de más de cuatro niveles, debido al gran número de marcos existentes. Otra característica interesante es poder consultar en esta representación gráfica las propiedades de un marco determinado. De hecho, las "cajas" donde se muestran los nombres de los distintos marcos son botones de comando, de modo que pulsando sobre ellos obtenemos una descripción del marco en cuestión, incluyendo los valores locales y los heredados, así como la relación de padres e hijos en la jerarquía. La Figura 5.27 muestra este tipo de consulta.
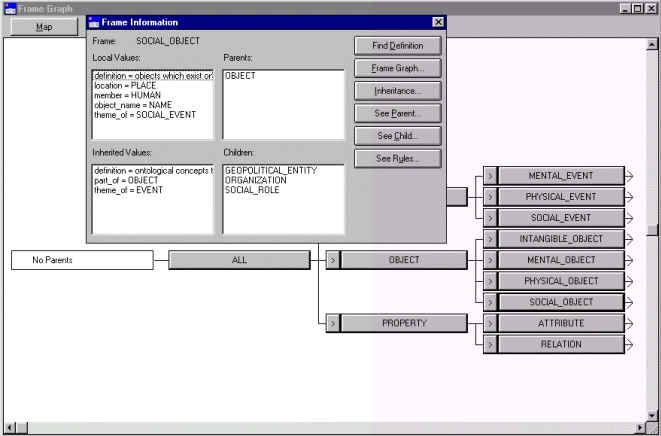
Figura 5.27 Información sobre un marco en modo gráfico
En el siguiente apartado mostraremos la forma en que la información léxica contenida en la LDB puede ser complementada de forma eficiente por la información contenida en la ontología. Antes de concluir este apartado, describiremos la forma en que estos dos repositorios pueden ser utilizados de forma conjunta.
Los investigadores sobre la teoría de la información han propuesto numerosas fórmulas para integrar DBMSs y bases de conocimiento. La descripción teórica de la interacción entre estos dos tipos de bases de información la encontramos, por ejemplo en las palabras de Brodie & Manola (1989:226), refiriéndose a las características de un KBMS ideal:
KBMS technology will require a deep integration of database and AI technologies. DBMS technology will provide the core technology at the computational level. Key features will include traditional database management functions for large shared databases such as (semantic) data models; languages (...); semantic integrity definition and maintenance; storage/search structures; search and update optimization; concurrency; security; error recovery; and distribution of data and processes. AI technology will provide the base for the knowledge level which will provide the means with which to represent and reason about the knowledge base represented at the computational level.
La adopción de técnicas provenientes del ámbito de los DBMS por parte de la IA, se centra en las propiedades de las bases de datos de gestionar grandes cantidades de datos, y por tanto permitir sistemas a gran escala. Este integración es por tanto conceptualmente simple y puede quedar resumida, de forma genérica, en la Figura 5.28 adaptada de Smith (1989).
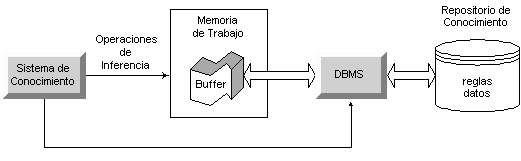
Figura 5.28 Integración DB/KB
La memoria de trabajo que aparece en esta figura puede ser
recreada por un lenguaje de programación estándar, que permita la utilización de
librerías dinámicas (DLL: Dynamic Link Library). En realidad, existen varios
modos de integrar la información proveniente de los dos repositorios. En primer lugar, se
puede utilizar Prolog como memoria de trabajo. LPA Prolog ofrece DLLs de 32 bits que
permiten la conexión con bases de datos Win32, entre ellas MS Access. La utilización de
Flex como servidor desde LPA Prolog es directa, mediante la utilización de predicados de
nivel Prolog tales como isa_frame/2, isa_instance/2, isa_value/2, isa_slot/3,
lookup/[3,4], some_instance/2, etc. La Figura 5.29 muestra esta posible
disposición, con la que tenemos a nuestro alcance las dos fuentes de información más
todas las funcionalidades de un Prolog compilado, incluyendo un parser DCG estándar.
De forma alternativa, es posible utilizar un lenguaje de programación de propósito general, por ejemplo, Visual Basic, C, etc. como gestor de la memoria de trabajo, mediante el denominado "Intelligence Server", otro producto de LPA diseñado para actuar de servidor de bases de conocimiento Flex para este tipo de lenguajes. Esta disposición es la que muestra la Figura 5.30.
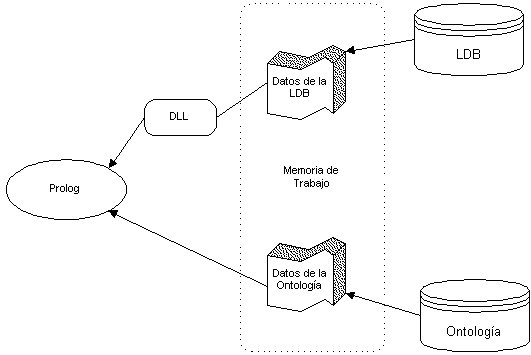
Figura 5.29 Integración de LDB y ontología en una memoria de trabajo Prolog
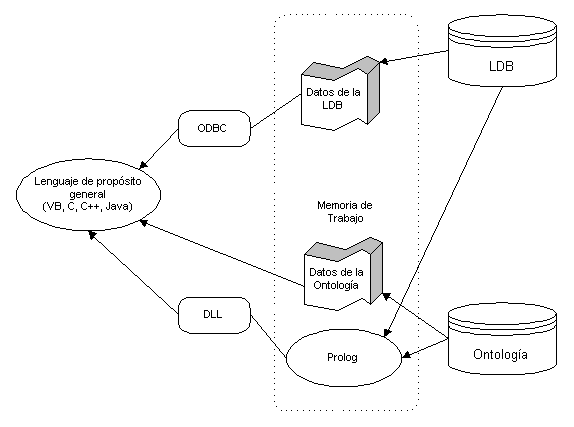
Figura 5.30 Integración de LDB y ontología mediante un lenguaje externo
Como podemos observar, este segundo modo de integrar las dos fuentes de información es más flexible porque tenemos a nuestro alcance, además de todo lo anterior, (incluyendo las posibilidades de Prolog), la potencia de un lenguaje compilado de propósito general, lo que permite la creación de aplicaciones estándar para plataforma Win32.
Queremos dejar constancia de que, aunque hayamos elegido esta plataforma para la implementación de nuestro sistema, el modelo de representación que presentamos puede ser recreado en cualquier otra plataforma, siempre que se hallen disponibles las herramientas que hemos mostrado u otras similares. El énfasis lo ponemos en la utilización de un RDBMS para la representación masiva de información léxica conectado a una ontología representada mediante un sistema basado en marcos, cualquiera que sean las herramientas que implementen estos sistemas de información.
NOTAS
Anterior I Siguiente I Índice capítulo 5 I Índice General