Los responsables de los primeros esquemas de representación formalizados fueron Quillian (1968) y Shapiro & Woddmansee (1971). Los esquemas de redes semánticas tienen una fundamentación psicológica muy sólida, tal y como apuntábamos en el Capítulo 2, por lo que se han realizado numerosos esfuerzos por llevar a cabo implementaciones importantes basadas en ellas.
Las redes semánticas han sido muy utilizadas en IA para representar el conocimiento y por tanto ha existido una gran diversificación de técnicas. Los elementos básicos que encontramos en todos los esquemas de redes son:
Básicamente, podemos distinguir tres categorías de redes semánticas:
En general, cuando se habla de "redes semánticas"
se suele hacer referencia a uno de estos esquemas, normalmente a las redes IS-A o a los
esquemas basados en marcos, que comparten ciertas características fundamentales. De entre
estas características compartidas destacamos la herencia por defecto (default
inheritance). En una red semántica, los conceptos (o estructuras, clases, marcos,
dependiendo del esquema concreto) están organizados en una red en la que existe un nodo
superior (top: T) al que se le asigna uno o varios nodos hijos, que a su vez tienen
otros conceptos hijos y así sucesivamente hasta que se alcanza el final (bottom: ![]() ),
cuyos nodos ya no son conceptos sino instancias.
),
cuyos nodos ya no son conceptos sino instancias.
A continuación estudiamos los tres tipos de esquemas de redes semánticas que han tenido una mayor repercusión. De los tres, el esquema basado en marcos es el que permite una mayor flexibilidad, y el que ha recibido mayor atención por parte de los investigadores de ciencia cognitiva y lingüística.
Sin duda el tipo de red semántica por excelencia es el de redes IS-A. De hecho muchas veces se menciona este tipo como sinónimo de "red semántica", y los restantes tipos también incorporan este tipo de enlaces o arcos (links). Esto ha dado lugar a que existan casi tantos significados para un enlace IS-A como los hay para sistemas de KR (Brachman, 1983).
Una red IS-A es una jerarquía taxonómica cuya espina dorsal está constituida por un sistema de enlaces de herencia entre los objetos o conceptos de representación, conocidos como nodos. Estos enlaces o arcos pueden estar etiquetados "IS-A", también "SUPERC", "AKO", "SUBSET", etc. Los restantes tipos de redes semánticas son en realidad especializaciones de redes IS-A, por lo que siguen y amplían los conceptos fundamentales que exponemos en este apartado.
Las redes IS-A son el resultado de la observación de que gran parte del conocimiento humano se basa en la adscripción de un subconjunto de elementos como parte de otro más general. Las taxonomías clásicas naturales son un buen ejemplo: un perro es un cánido, un cánido es un mamífero, un mamífero es un animal. Obteniendo un número de proposiciones:
![]() x (perro (x))
x (perro (x)) ![]() cánido (x);
cánido (x);
![]() x
(cánido (x))
x
(cánido (x)) ![]() mamífero (x);
mamífero (x);
![]() x
(mamífero (x))
x
(mamífero (x)) ![]() animal (x);
animal (x);
La estructuración jerárquica facilita que la adscripción de propiedades a una determinada categoría se reduzca a aquellas que son específicas a la misma, heredando aquellas propiedades de las categorías superiores de la jerarquía, tradicionalmente de una forma monotónica. El siguiente ejemplo de red IS-A (Figura 4.11), tomado de (Brachman 1983:31) ejemplifica una red semántica típica con herencia de propiedades.
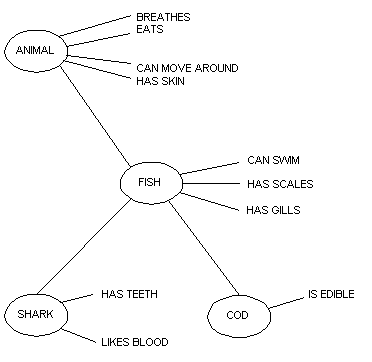
Figura 4.11 Ejemplo de red IS-A
El concepto de herencia es fundamental para entender el funcionamiento de las redes semánticas, así como el del modelo de datos orientado al objeto, que toma prestados estos mecanismos desarrollados en el ámbito de la IA. Siguiendo a Shastri (1988), definimos la herencia como el sistema de razonamiento que lleva a un agente a deducir propiedades de un concepto basándose en las propiedades de conceptos más altos en la jerarquía.22
Así, en el ejemplo jerárquico de la Figura 411, el agente23 sería capaz de atribuir las propiedades "breathes" o "has gills" al concepto "shark" sin que éstas se encuentren específicamente mencionadas. La herencia, por tanto, puede ser definida como el proceso mediante el cual se determinan unas propiedades de un concepto C, buscando las propiedades atribuidas localmente a C, si esta información no se encuentra a nivel local, buscando las propiedades atribuidas a conceptos que se encuentran en los niveles superiores a C en la jerarquía conceptual.
Como Brachman (1983) recuerda, las nodos de las estructuras IS-A se han usado para representar muchas cosas, pero la división más importante es la interpretación genérica o específica de los nodos, es decir, si éstos representan un sólo individuo o varios. Los nodos situados en lo más bajo de la jerarquía y que denotan individuos son llamados tokens, mientras que los nodos superiores, que denotan clases de individuos son considerados types. Puesto que en una misma jerarquía podemos obtener nodos de ambos tipos, se debe hacer explícita una distinción de los tipos de enlaces. Por un lado existen enlaces que conectan categorías (genéricas) con otras categorías, y por otro, enlaces entre categorías e individuos. Las primeras pueden expresar las siguientes relaciones:
Las relaciones genérico/individuales también son de varios tipos:
Como recuerda Hodgson (1991), las jerarquías IS-A presentan un número impresionante de posibilidades, pero también una desventaja: al aumentar el número de enlaces, aumenta progresivamente la complejidad computacional para seguirlos. Este problema bien conocido ha dado lugar a que se haya propuesto que, en lugar de establecer esta y otras posibles taxonomías de enlaces IS-A, se use el enlace IS-A de propósito general, que al ser programable, permite establecer el tipo de enlace adecuado a cada situación particular, lo que dota de una gran flexibilidad al esquema de representación. De este modo se puede representar una semántica compleja, específicamente mediante el uso de prototipos, en los que una determinada situación se representa mediante nodos y arcos específicos. Por ejemplo, la aserción "The book rests on the table" se puede representar así:
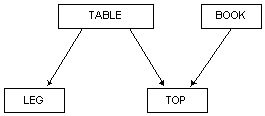
Figura 4.12 Ejemplo de Prototipos
Estos prototipos o esquemas forman la base de los scripts de Schank y Abelson (1977), que mencionaremos en el siguiente apartado.
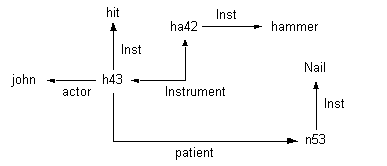
Figura 4.13 Ejemplo de red semántica para lenguaje natural
En la Figura 4.13 exponemos el tipo de diagrama para representar una oración de lenguaje natural con una notación de redes semánticas, tomando como ejemplo la oración "John hit a nail with a hammer"
En esta red los nodos son identificadores de las instancias determinadas (tanto verbos como sustantivos). "Inst" representa una instancia de una clase de entidades (hit, nail, hammer): "h43" es una instancia de la acción hit, existiendo un paciente, "n53", instancia de la clase nail, que es el que recibe la acción, mediante un instrumento "ha42", que es una instancia de la clase hammer (el hecho de que "john" es una instancia de la clase person, no ha sido representado).
Este tipo de representación de conocimiento es directo y fácil de seguir, pero el establecimiento de los primitivos adecuados es muy dificultoso y a veces es imposible representar un sistema de este modo. Además, exige una gran cantidad de trabajo de inferencia: es relativamente fácil determinar si dos frases significan lo mismo pero no es tan fácil determinar si una frase es la consecuencia lógica de otra.
Otro problema estriba en la diversidad de tipos de arcos establecidos. Esto provoca que de red semántica a red semántica el significado de los arcos y los nodos varíe, provocando ambigüedad en la notación. Por ejemplo, la red semántica de la Figura 4.14 puede tener tres significados distintos:
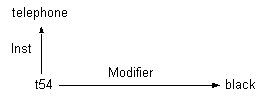
Figura 4.14 Ambigüedad en redes semánticas
Para concluir este apartado, resumimos los tres problemas más reconocidos de los esquemas de representación basados en redes semánticas:
Esto llevó a idear otros esquemas de representación con una estructura más compleja que simples nodos y arcos, que fuesen capaces de dar cabida a éstas y otras situaciones. Concretamente, John Sowa propuso los grafos conceptuales, aunque el esquema de representación basado en marcos (frames) es el que ha tenido mayor aceptación.
Los grafos conceptuales (conceptual graphs), propuestos por Sowa (1984), se diferencian de las redes IS-A en que los arcos no están etiquetados, y los nodos son de dos tipos:
Por tanto, son los nodos de relación los que hacen el papel de enlaces entre las entidades.
Existen dos notaciones para los grafos conceptuales, la forma lineal (textual) y los diagramas o display form, que presentan tres tipos de elementos notacionales:
La Figura 4.15 muestra estos tipos de notaciones.
[CONCEPT1] ![]() (REL.)
(REL.) ![]() [CONCEPT2
[CONCEPT2
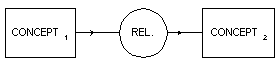
Figura 4.15 Notaciones de grafos conceptuales
Como mostraremos en el siguiente capítulo, este tipo de modelado conceptual debe mucho al modelo de Entidad/Relación de Chen (Chen 1976).
La intención del uso de los grafos conceptuales para la representación del lenguaje natural es mencionada por el propio Sowa, quien dedica un capítulo completo de su obra a la aplicación de su esquema al análisis del lenguaje. La representación semántica de la frase "man biting dog" que nos muestra en el capítulo introductorio es indicativo del uso que se le puede dar (Figura 4.16) (Sowa 1984:8). Sowa apunta que sus grafos conceptuales ponen el énfasis en la representación semántica (en el sentido lingüístico de la palabra).

Figura 4.16 Ejemplo de grafo conceptual para NL
Una gran ventaja del esquema de Sowa es que permite restringir la generación de representaciones sin sentido por medio de lo que él denomina grafos canónicos. Tomando como base la conocida frase de Chomsky
"Colorless green ideas sleep furiously" (Chomsky 1957),
representada por el grafo [SLEEP] ![]() (AGNT)
(AGNT) ![]() [IDEA]
[IDEA] ![]() (COLOR)
(COLOR) ![]() [GREEN], establece la idea de canon, que está basada en la noción de jerarquía
de tipos, según la cual existe una función tipo que proyecta conceptos sobre
un conjunto C cuyos elementos son etiquetas de tipo. Esta función corresponde a
los arcos IS-A que vimos anteriormente. El canon contiene la información necesaria para
derivar otros grafos canónicos y tiene cuatro componentes:
[GREEN], establece la idea de canon, que está basada en la noción de jerarquía
de tipos, según la cual existe una función tipo que proyecta conceptos sobre
un conjunto C cuyos elementos son etiquetas de tipo. Esta función corresponde a
los arcos IS-A que vimos anteriormente. El canon contiene la información necesaria para
derivar otros grafos canónicos y tiene cuatro componentes:
Las reglas de formación que permiten que un grafo canónico se derive de otro son las de copia, unión, restricción y simplificación. Además un grafo puede convertirse en canónico mediante otros dos procesos:
La relación de conformidad es también relevante, porque se refiere al concepto type/token, que Sowa representa mediante la notación t::i, donde el indicador individual i está relacionado con el tipo t.
La frase de Chomsky sería bloqueada por los cánones:
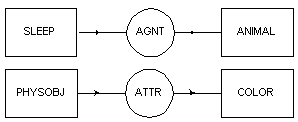
Figura 4.17
De este modo se pueden generar grafos bastante complejos para representar conceptos. Como ejemplo, exponemos el grafo de transacción (Sowa 1984:110) (Figura 4.17).
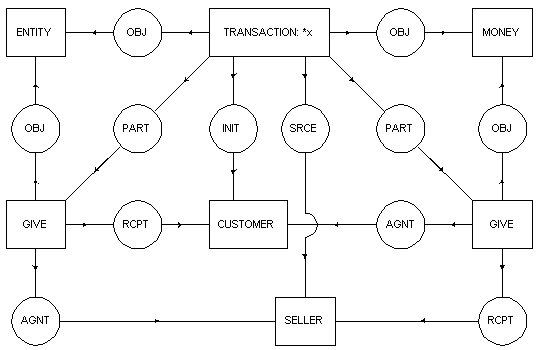
Figura 4.18 Grafo conceptual para TRANSACTION
El que inicia la transacción es un customer, que es el receptor de un acto de give y el agente de otro give. El objeto de la transacción es una entity, que es el objeto del primer give. El instrumento de la transacción es money, que es también el objeto del segundo give. La fuente de la transacción es un seller que es el agente de un give y el receptor del otro.
Sowa advierte que las reglas canónicas de formación no son reglas de inferencia. La formación de reglas únicamente asegura las restricciones de selección semánticas, que Sowa basa en las teorías de Katz y Fodor (1963), pero no garantiza la verdad o falsedad de las aserciones. Para incorporar la lógica a la teoría de grafos conceptuales, se usa un operador que proyecta los grafos conceptuales sobre fórmulas de cálculo de predicados de primer orden (Hodgson 1991).
El canon es por tanto un sistema extremadamente flexible para representar el conocimiento y, específicamente, el conocimiento lingüístico. De hecho, el sistema de representación léxica que más éxito ha tenido hasta el presente, las estructuras de rasgos24, comúnmente usadas en los formalismos gramaticales modernos, pueden ser consideradas como una especialización de los grafos canónicos de Sowa específicamente aplicadas a la representación del lenguaje. Su implementación, normalmente en Lisp, también guarda muchas similitudes.
No deberíamos finalizar la exposición de este apartado sin mencionar un esquema de representación anterior, que si bien no ha tenido la misma repercusión que los grafos conceptuales, contiene la base que, junto con las ideas de las redes semánticas, usó Sowa para su esquema. Estamos hablando de las redes de dependencia conceptual (CD: Conceptual Dependency).
Esta notación fue desarrollada por Schank (Schank 1975) desde finales de los años 60. Al igual que en los grafos conceptuales, la idea central detrás de la CD es crear una representación canónica de una frase, en este caso basándose en ciertos primitivos semánticos. En la teoría original tan sólo se contemplaban siete primitivos, que incluían cinco acciones físicas: move, propel, ingest, expel y grasp y dos cambios de estado: ptrans (transferencia física en el espacio) y mtrans (transferencia mental de información). La frase "John threw a ball to Mary" es representada del modo siguiente (Schank 1975:51):
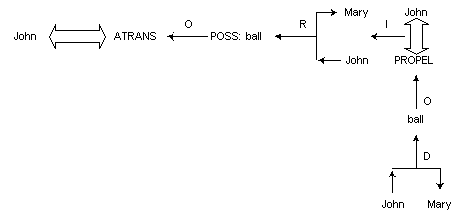
Figura 4.19 Ejemplo de dependencia conceptual
Esta teoría está enteramente basada en los primitivos semánticos, que son las entidades básicas usadas para describir el mundo. Las dificultades, por tanto, son las mismas que presentan todas las teorías lingüísticas basadas en primitivos: la naturaleza totalmente arbitraria de los primitivos escogidos y la falta de sistematicidad en su uso y adopción. Al igual que en otras teorías lingüísticas basadas en primitivos semánticos, el número de éstos tendió a crecer, en el caso de Schank hasta 40. Tampoco él se salva de la sospechosa similitud entre algunos primitivos y lexemas concretos, como por ejemplo want.
La teoría original de Schank evolucionó para incluir unidades de memoria más desarrolladas, llamadas scripts (Schank & Abelson 1977). Un script es una secuencia de esquemas que "cuenta una historia", el ejemplo tradicional es el del restaurante: entrar, pedir la comida, pagar al camarero, etc., serían los esquemas que conforman el script. Los scripts, sin embargo, tienen mucho en común con la notación que estudiamos a continuación, los esquemas de marcos.
El primer proponente de la noción de marco25 (frame) fue el psicólogo cognitivo Marvin Minsky, en cuyas palabras podemos resumir la esencia de los marcos.
Here is the essence of frame theory: When one encounters a new situation (or makes a substantial change in one’s view of a problem), one selects from memory a structure called a frame. This is a remembered framework to be adapted to fit reality by changing details as necessary.
(Minsky 1975: 211)
La fundamentación psicológica de los marcos es parecida a la de los scripts de Schank: cuando nos enfrentamos con una situación determinada, intentamos ajustarla a otra parecida de la que ya tenemos experiencia previa y esperamos que aparezcan un número de elementos comunes y se sucedan algunas situaciones. Por ejemplo, si entramos en una habitación de hotel, esperamos encontrar una cama, un armario, un baño, etc. Nuestra mente reconocerá las instancias específicas de la nueva habitación y los acomodará al estereotipo que ya poseemos. La base de la teoría la conforman, por tanto, las situaciones estereotipadas.
Dejando a un lado esta fundamentación psicológica, la representación basada en marcos constituye en gran medida la base del modelo orientado al objeto actual, ya que contiene casi todos los conceptos que éste presenta, aunque estas ideas fueron aplicadas en principio a los lenguajes de programación más que a lenguajes de representación y consulta. Por esto y por la enorme importancia que la representación del conocimiento basada en marcos ha tenido y sigue teniendo, nos detendremos a exponer las características y esquemas propuestos más relevantes.
Adelantamos ya que, al igual que ocurre en la ontología que nos ha servido de base para nuestra implementación, la de Mikrokosmos, utilizaremos precisamente un esquema basado en marcos para nuestra ontología, utilizando para su implementación un lenguaje basado en marcos moderno, con prestaciones muy superiores a las que aquí expondremos para las implementaciones clásicas. Los detalles particulares de este lenguaje, KSL, los mostraremos en el siguiente capítulo.
Informalmente, un marco es una estructura de datos compleja que representa una situación estereotipada, por ejemplo hacer una visita a un enfermo o acudir a una fiesta de cumpleaños. Cada marco posee un número de casillas (slots) donde se almacena la información respecto a su uso y a lo que se espera que ocurra a continuación. Al igual que las redes semánticas, podemos concebir un marco como una red de nodos y relaciones entre nodos (arcos). Una base de conocimiento basada en marcos es una colección de marcos organizados jerárquicamente, según un número de criterios estrictos y otros principios más o menos imprecisos tales como el de similitud entre marcos. A nivel práctico, podemos considerar los marcos como una red semántica con un número de posibilidades mucho mayor, entre las que destacan especialmente, la capacidad de activación de procesos (triggering) y de herencia no-monotónica mediante sobrecontrol (overriding).
Formalmente, un marco M es una lista de atributos (slots) y valores (S, V). El valor V de un slot S puede ser:
Como es evidente, la representación de conocimiento basada en marcos debe mucho a las redes semánticas. Sin embargo, los esquemas de representación basados en marcos insisten en una organización jerárquica de éstos, mientras que las redes semánticas no requieren tal organización. La estructura de nodos de los marcos es también mucho más rica que la de las redes semánticas, conteniendo sistemas de triggering de procedimientos. Esto ocurre cuando en lugar de llenar un slot con un valor determinado, se indica un procedimiento que será el encargado de devolver un determinado valor. En el entorno de los marcos, a este tipo de procedimientos se les denomina attached procedures, servants, demons o methods, utilizándose a veces el término disparador en el discurso en lengua española. Estos procedimientos son especialmente útiles cuando el cálculo de un valor determinado requiere un tiempo alto de computación, cuando el valor es susceptible de cambiar con el tiempo o cuando el valor tiene un bajo nivel de acceso: en lugar de computar el valor siempre que el sistema esté en funcionamiento, se computa sólo cuando es requerido. El término método, se ha tomado del entorno de los marcos para usarlo en el modelo orientado al objeto para designar las funciones componentes de una clase, aunque en algunos de los lenguajes de programación orientados al objeto más importantes, como C++, los métodos son llamados funciones miembro.
La organización jerárquica de los marcos es una de sus características más destacables. Los marcos se organizan en jerarquías que presentan los mismos sistemas de herencia que encontrábamos en las redes IS-A. De hecho, una estructura de marcos no es más que una ampliación de una estructura de redes IS-A básica (de redes semánticas tradicionales), donde los nodos han sido reemplazados por grupos estructurados de información (los marcos).
Una jerarquía de marcos es un árbol en el que cada uno de los nodos es un marco. Para cada nodo hijo, el enlace con el nodo padre es un enlace de herencia. El nodo hijo hereda todos los slots de su padre a menos que se especifique lo contrario (sobrecontrol). Esta es una gran diferencia con las redes IS-A, donde la herencia es siempre monotónica, es decir no hay posibilidad de negar la herencia de propiedades en un contexto o situación determinada (que puede ser especificada por el resultado de una operación de triggering). Los nodos pueden ser de dos tipos: nodos de clase y nodos de instancia. Todos los nodos internos (no terminales) han de ser nodos de clase.
La característica que la herencia trae consigo es el concepto de valores por defecto (defaults). En un marco se puede especificar un valor determinado o bien un valor por omisión (también llamados valores locales y valores heredados), en cuyo caso heredará sin más el valor de su antecesor. Por ejemplo, la clase (nodo de clase) ave, tendrá el valor por omisión vuela como "cierto", aunque algunos nodos de instancia hijos, por ejemplo avestruz, no posean esta propiedad. Esta instancia concreta puede ser obligada a no heredar esta propiedad asignándole el valor "falso", mientras que otras propiedades, como tiene_alas, sí serían heredadas por defecto (aunque en otras instancias, como en el caso de kiwi, ésta habría de ser negada).
Esta misma disposición es la que presentan los sistemas orientados al objeto actuales, aunque en éstos, los nodos de instancia no son considerados nodos, sino objetos. El término orientación al objeto se comenzó a utilizar con un significado muy parecido al que de él tenemos hoy por los proponentes de esquemas de representación basados en marcos a finales de los años 70. Por ejemplo, Bobrow y Winograd (1979) hablan de "object-oriented data structures".
Podemos resumir las principales características de los marcos en las siguientes (Minsky 1975; Winograd 1975):
De forma apriorística, su aplicación a la representación de la información léxica parece garantizada, ya que los marcos permiten una gran flexibilidad de representación. Su soporte para representar la herencia de propiedades de una forma no monotónica resulta especialmente atractivo. De hecho, hoy en día, esta propiedad, la herencia por defecto no monotónica, se considera indispensable para el procesamiento de lenguaje natural (p. ej. Gazdar & Pullum 1987; Ritchie et al. 1987; Flickinger 1987; Carpenter 1992; Zajac 1992; Bouma 1992).
El razonamiento en un esquema basado en marcos se lleva a cabo mediante dos mecanismos básicos: el reconocimiento (recognition o pattern-matching) y la herencia. En el entorno de los marcos el proceso de reconocimiento de patrones se centra en encontrar el lugar más apropiado para un nuevo marco dentro de la jerarquía de marcos. Esto requiere que el mecanismo de reconocimiento sea capaz de recibir información sobre la situación existente (en forma de marco) y lleve a cabo una búsqueda del marco más adecuado de entre todos los contenidos en la base de conocimiento. Shastri (1988:16) define este concepto así: "Given a description consisting of a set of properties, find a concept that best matches this description."
Teniendo en cuenta las características de herencia anteriormente descritas, el conjunto de propiedades no tiene por qué encontrarse a nivel local, sino que pueden estar atribuidas a conceptos (marcos) en posiciones superiores en la jerarquía. Podemos decir que estos dos mecanismos complementarios de razonamiento conforman el núcleo de lo que entendemos por comportamiento inteligente, y actúan como precursores de procesos de razonamiento más especializados.
El modo en que estos dos mecanismos básicos de razonamiento interactúan se muestra en la Figura 4.20 (Shastri 1988:16). En la memoria semántica del agente se encuentran un número de conceptos (Cn) que poseen un número de propiedades (pn). El punto de entrada ß corresponde a consultas de reconocimiento, que se inicia cuando un determinado proceso posee una descripción parcial sobre una entidad X y desea corroborar su identidad o la clase a la que pertenece. El punto de entrada corresponde a consultas sobre herencia. En este caso el agente conoce la identidad de X, pero quiere conocer el valor de una o varias de sus propiedades. Los dos mecanismos interactúan cuando se trata de llevar a cabo procesos cognitivos más complejos, que implican un número de consultas sucesivas de uno y otro tipo para llegar a una determinada conclusión.
Los problemas en el proceso de reconocimiento surgen cuando los valores por omisión no son cumplidos. Por ejemplo, un gato tiene normalmente cuatro patas y una cola, pero a un gato determinado le puede faltar la cola y una de sus patas; en este caso el algoritmo reconocedor (matcher) debe ser lo suficientemente inteligente para ser capaz de averiguar que el mejor marco de los posibles (best fit) es el del gato, aunque dos de sus principales características no se cumplan.
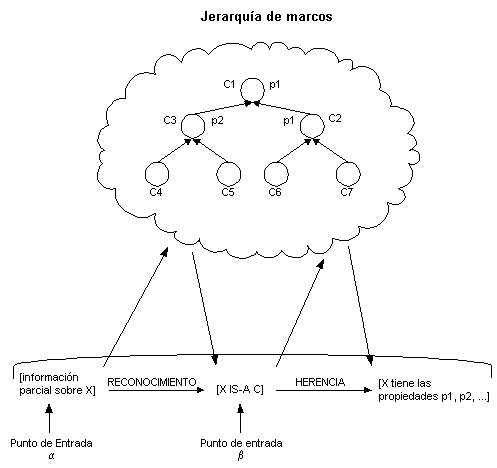
Figura 4.20 Herencia y reconocimiento de patrones en marcos
Ésta es la situación conflictiva típica en la que algún proceso interno posee una descripción parcial de una entidad desconocida y además necesita determinar el valor de una o varias propiedades de esta entidad. Primero llevaría a cabo el reconocimiento parcial hasta determinar al menos la clase a la que la entidad pertenece, a continuación atribuiría las propiedades de sus clases predecesoras en la jerarquía y volvería a intentar el reconocimiento individual hasta llegar a su ubicación y determinación de propiedades heredadas y locales completa.
En nuestra exposición del sistema de KBMT Mikrokosmos (ver apartado 3.3.6), vimos cómo existía un algoritmo que calculaba la "distancia" entre dos conceptos o instancias y devolvía un índice. Este tipo de operaciones abstractas es otra de las características que dan a los esquemas basados en marcos su gran potencia y expresividad.
Como apunta Shastri (1988:17), en un proceso cognitivo complejo, como la comprensión del lenguaje natural (NLU: Natural Language Understanding), los mecanismos de herencia y de reconocimiento de patrones son absolutamente imprescindibles. Por ejemplo, para la adjudicación de restricciones de selección a un determinado actante con el objeto de reconocer un patrón sintáctico-semántico determinado de un verbo polisémico y eliminar la posible ambigüedad semántica. Una organización del léxico en campos semánticos con dimensiones y subdimensiones jerarquizadas con herencia de propiedades léxicas puede ser representada como una red semántica de conceptos a modo de marcos. Esta representación es válida independientemente del modo de implementación que usemos, siempre y cuando éste se acomode a los requisitos de jerarquización de entidades. En el capítulo siguiente mostraremos cuál es la utilidad que le hemos dado a nuestra representación basada en marcos de forma detallada.
Minsky propuso originalmente un esquema de representación para los marcos que combinaba ideas de las redes semánticas, esquemas procedimentales y la lingüística. Los lenguajes de representación basados en marcos son hoy día considerados como la forma más adecuada de representar conocimiento complejo, y en especial para representar el lenguaje natural.
La similitud entre las teorías lingüísticas de casos y los esquemas de representación basados en marcos no ha pasado inadvertida. El propio Fillmore (1977) afirmaba que los slots y los casos verbales eran una y la misma cosa. En el mismo sentido se manifiestan Winston (1977) y Charniak (1981).
Para finalizar este apartado mostraremos algunas implementaciones de sistemas de marcos consideradas hoy en día clásicas: KRL, OWL y KL-ONE.
El desarrollo de KRL (Knowledge Representation Language) (Bobrow & Winograd 1977) estuvo inicialmente motivado por el procesamiento del lenguaje natural. Las unidades básicas que componen una base de datos KRL son los marcos. La información contenida en los slots contiene detalles sobre cómo instanciar un marco.
En su implementación hacen uso intensivo de los conceptos de prototipo y primitivos, que utilizan de un modo un tanto libre en esta primera exposición, pero definen mejor en otras posteriores (Bobrow & Winograd 1977).
Como su nombre indica, KRL, es a la vez un sistema de KR y un lenguaje de programación. El lenguaje permite la invocación de procedimientos que se encuentran adjuntos a las estructuras de datos orientadas a objetos, conteniendo el germen de lo que hoy en día se conoce por encapsulación, una de las características que hacen de la orientación al objeto tal vez el modelo computacional más potente y versátil hasta la fecha.
Por su parte, OWL basa sus características en la sintaxis y semántica del inglés, tomando como principio la Hipótesis Whorfiana de que el idioma de un hablante juega un papel determinante en su modelo del mundo, y por tanto en la estructuración de su mente.
Una base de conocimiento de OWL puede ser vista como una red semántica cuyos nodos son expresiones que representan el significado de oraciones en lenguaje natural. Cada nodo, denominado "concepto", queda definido por un par (genus, specializer), donde el "genus" especifica el tipo o "superconcepto" y el "specializer" distingue este concepto de todos los demás que comparten el mismo "genus".
Sin embargo, de entre todos los lenguajes de representación clásicos basados en marcos, es sin duda KL-ONE (Brachman & Schmolze 1982, 1985) el más relevante en cuanto que a partir de él han surgido numerosos sistemas de KR que se están desarrollando o usando hoy en día. De hecho, se suele hacer referencia a los lenguajes de programación/representación basados en marcos mediante el calificativo "al estilo de KL-ONE". KL-ONE es el producto de muchos años de investigación de algunos de los que se pueden considerar como padres de la representación del conocimiento, entre los que destacan Ronald Brachman, Rusty Bobrow, Hector Levesque, Jim Schmolze o William Woods.
Como viene siendo habitual, una taxonomía de KL-ONE comprende conceptos, con un número de propiedades atribuidas y una serie de relaciones entre conceptos. Más concretamente, un nodo (concepto) de KL-ONE consiste en un conjunto de roles (generalizaciones de las nociones de atributo, parte, constituyente, rasgo, etc.) y un conjunto de condiciones estructurales que expresan relaciones entre esos roles. Los conceptos están enlazados a conceptos más generales en una relación especial llamada SUPERC. El concepto más general en la taxonomía es denominado superconcepto, y subsume (es más general que) todos los demás.26
Los conceptos y roles de KL-ONE tienen una estructura parecida a las clásicas nociones de registro y campo para las bases de datos, o de marco y slot en el ámbito en la terminología de la IA.
La adecuación expresiva fue un objetivo primordial en el desarrollo de KL-ONE, enfatizando la semántica de la representación y su adecuación para poder hacer distinciones sutiles al conceptualizar ideas complejas. Tanto es así que Woods (1983) afirma que el proyecto KL-ONE se llevó a cabo más con el espíritu de una investigación de filosofía aplicada que con el de investigación en representación del conocimiento y estructuras de datos.
En cualquier caso, la herencia de KL-ONE se ha dejado sentir en todas las implementaciones posteriores de lenguajes basados en marcos, intentando seguir fiel en espíritu a esta clásica implementación, al mismo tiempo que se han mejorado los aspectos técnicos respecto a velocidad de ejecución, optimización de código (hasta muy recientemente no ha existido ninguna implementación de un lenguaje de marcos que produjese código compilado) o interfaz a otros lenguajes procedimentales.
Una de estas implementaciones, FLEX, será la que usaremos en nuestra implementación de la ontología de conceptos. Describiremos este sistema junto con el lenguaje de programación que le da soporte en el siguiente capítulo.
Como ya hemos visto, los marcos, en su forma más pura han sido utilizados en algunas de las implementaciones de TA que ya hemos mostrado (Mikrokosmos). Su atractivo como soporte computacional para diversos sistemas de procesamiento del lenguaje natural en general ha quedado reflejado en obras tan relevantes como Metzing (1980), Evens (1988) o Lehrer & Kittay (1992). A continuación mostraremos una serie de esfuerzos destinados a la consecución de un entorno de representación puramente léxica. Como ya hemos adelantado, éstos presentan muchos puntos en común con los sistemas de redes semánticas que acabamos de describir, incorporando además un fuerte componente lógico.
NOTAS
Anterior I Siguiente I Índice capítulo 4 I Índice General