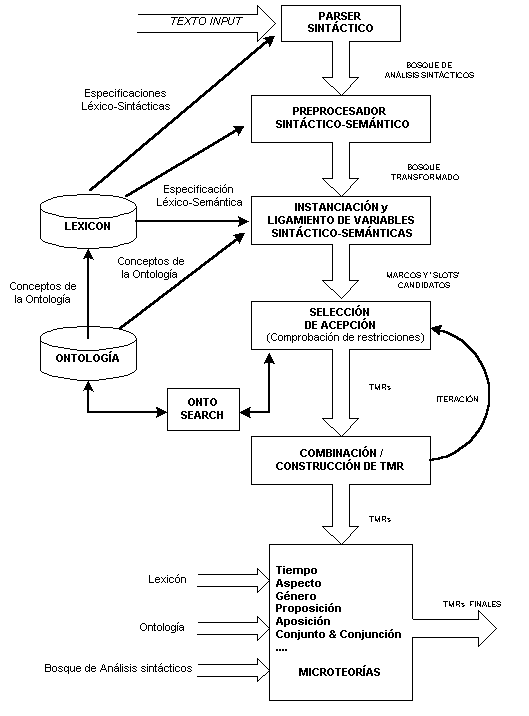
Figura 3.21 Arquitectura NLP de Mikrokosmos
Mikrokosmos es un sistema de KBMT interlingüe desarrollado por el Computing Research Laboratory (CRL) de la New Mexico State University (NMSU) de EE.UU. y financiado por el Ministerio de Defensa de este país (Beale, Nirenburg & Mahesh, 1995; Mahesh & Nirenburg 1995a,b; Onyshkevych & Nirenburg 1994). A diferencia de otros proyectos basados de KBMT anteriores (p. ej. Pangloss), Mikrokosmos es un sistema práctico a gran escala, enfocado en principio a traducir entre los idiomas inglés y español y que actualmente está siendo expandido para dar cabida a otros idiomas (tailandés).
Mikrokosmos comenzó siendo un proyecto derivado de Pangloss, que se inició con el objetivo de superar las deficiencias mostradas por el motor de KBMT de este sistema (Nirenburg, Attardo & Brown 1995). En la actualidad, este sistema traduce artículos periodísticos españoles sobre adquisiciones y fusiones empresariales sin restricciones de input. Para ello utiliza una serie de lexicones específicos para cada lengua y una ontología de conceptos independiente de cualquiera de las lenguas. Estos dos recursos son utilizados para generar las denominadas TMRs (Text Meaning Representations) que constituyen las representaciones interlingües propiamente. Además del parser sintáctico, que es el mismo que el utilizado en el proyecto Pangloss, en Mikrokosmos se están desarrollando una serie de algoritmos específicos para problemas concretos que son denominadas "microteorías". Por ejemplo se contemplan teorías específicas para el aspecto, el tiempo, el género, etc.
La Figura 3.21 (Beale, Nirenburg & Mahesh 1995), ilustra la arquitectura de Mikrokosmos para el análisis de textos.
Como se puede observar, existen cuatro componentes clave en el sistema:
Figura 3.21 Arquitectura NLP de Mikrokosmos
A continuación trataremos de mostrar la forma en que estos componentes interactúan entre sí para conseguir un proceso de traducción basado en el conocimiento. Nos detendremos especialmente en la descripción de la estructura del lexicón y de la ontología, pues son especialmente relevantes para nuestro trabajo. No menos interesantes son los otros dos elementos. El desarrollo de las microteorías, en particular, resulta enormemente atractivo porque proporciona un buen método para aportar soluciones puntuales a problemas lingüísticos concretos. También describiremos brevemente las TMRs y daremos algún ejemplo con el objeto de mostrar el tipo de interlingua que Mikrokosmos propone.
En el modelo de NLP adoptado en Mikrokosmos, y de hecho en el paradigma de la KBMT, el lexicón se convierte en el principal elemento alrededor del cual giran todos los demás recursos y procesos. La mayor parte de la información está contenida en el lexicón o bien es referenciada a través de éste.
Los lexicones de Mikrokosmos constituyen la fuente de información léxica básica específica para cada lengua. El lexicón está estructurado en "superentradas" identificadas por el lema: la forma base, normalmente utilizada como referencia de búsqueda en un diccionario tradicional30. Dentro de cada superentrada, los lexemas individuales están representados mediante un formalismo basado en marcos31, que es el mismo utilizado para representar los conceptos que conforman la ontología.
La decisión de usar el mismo esquema de representación estuvo motivada por el deseo mantener un formato de datos homogéneo, pero también por razones históricas, para poder aprovechar los datos de proyectos anteriores. En el capítulo siguiente expondremos argumentos que rechazan esta disposición, inclinándonos a favor de otros formatos más estándar y por tanto susceptibles de una mejor reutilización.
La Figura 3.22 (Beale, Nirenburg & Mahesh 1995) muestra dos acepciones para el verbo español "adquirir". Las ventanas corresponden al interfaz gráfico OSF/Motif que forma parte del conjunto de herramientas para la manipulación tanto de los lexicones como de la ontología.
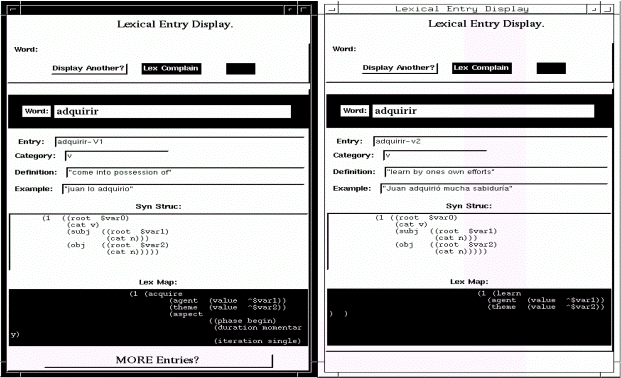
Figura 3.22 Entradas del lexicón de Mikrokosmos para
"adquirir"
Como vemos existen dos acepciones para la palabra "adquirir":
Cada una de estas acepciones requiere una proyección a un concepto distinto en la ontología (acquire y learn), de modo que entre ambos repositorios de información el desambiguador semántico pueda llevar a cabo su labor.
Cada una de las entradas de un lexicón se compone de una serie de zonas descriptivas, cada una de las cuales puede contener varios campos, que se corresponden con varios niveles de descripción lingüística. Las zonas que se contemplan son:
Las zonas CAT, MORPH, SYN y SYN-STRUC se usan durante la fase de análisis sintáctico (incluyendo segmentación oracional, tokenización y análisis morfológico), que precede al análisis semántico. Este parser sigue estando basado en el ya mencionado Universal Parser de Tomita (ver sección 3.3.5).
El formalismo gramatical utilizado para la representación y proceso de información sintáctica está por tanto basado en la Lexical-Functional Grammar. La estructura-f postulada por este formalismo ha sido modificado en algunos aspectos para acomodarlo al sistema. Los análisis sintácticos añaden un identificador ROOT a la estructura-f tradicional de la LFG. En cada uno de los niveles de la estructura, este identificador precede al identificador del sentido de los lexemas en el contexto del análisis. La representación es una lista, posiblemente recursiva, de estructuras de rasgos (FS: Feature Structures32) donde cada uno de los nombres de atributo es o bien un valor (esto es, un símbolo, ya que son listas anidadas LISP), o bien otra estructura de rasgos anidada. Por ejemplo, la siguiente estructura-f es el análisis preferido para la oración
The old man ate a doughnut in the shop
((ROOT +EAT-V1)
(MOOD DECL) (VOICE ACTIVE) (NUMBER S3)
(CAT V) (TENSE PAST) (FORM FINITE)
(SUBJ ((ROOT +MAN-N1)
(NUMBER S3) (CAT N)
(PROPER -) (COUNT +) (CASE NOM)
(DET ((ROOT +THE-DET1) (CAT DET)))
(MODS ((ROOT +OLD-ADJ1) (CAT ADJ)
(ATTRIBUTIVE +
-))))
(OBJ ((ROOT +DOUGHNUT-N1)
(NUMBER S3) (CAT N) (PROPER -) (COUNT +)
(DET ((ROOT +A-DET1) (CAT DET)))))
(PP-ADJUNCT ((ROOT +IN-PREP1)
(CAT PREP)
(OBJ ((ROOT `SHOP-N1)
(NUMBER S3) (CAT N)
(PROPER -) (COUNT +)
(DET ((ROOT +THE-DET1)
(CAT DET))))))))
En este ejemplo podemos observar otras particularidades del
lexicón de Mikrokosmos. Por ejemplo, los lexemas están precedidos del carácter
"+", seguido de la forma base (entrada en el lexicón), seguido de
"-", seguido de la indicación de la parte de la oración y un número indicando
la acepción ("+DOUGHNUT-N1")
La especificación SYN-STRUC es una interesante respuesta a la representación de las estructuras sintácticas que los distintos lexemas toman (marcos predicativos en el contexto de la FG o, de forma más genérica, patrones de complementación). Además de ofrecer una especificación sintáctico-semántica muy parecida a la de ésta, su estructuración jerárquica permite la herencia y por tanto una gran economía representativa. Además, dan cabida a la especificación de frases idiomáticas.
Al igual que el marco predicativo, esta zona es una especificación de la posición del lexema en la estructura sintáctica (estructura-f en este caso). Consta por tanto de un segmento de estructura-f de una oración típica con ese lexema. En el parser de Mikrokosmos esta representación es denominada patrón-fs (fs-pattern), contiene el lexema en cuestión y un número indeterminado (normalmente no más de dos) de niveles anidados por encima o por debajo del mismo. Por tanto la información incluida en un patrón-fs contiene aquellos niveles y elementos de la estructura-f que el lexema selecciona sintáctica y semánticamente. En el modelo actual los verbos seleccionan sus argumentos, los modificadores seleccionan sus núcleos, las preposiciones seleccionan sus objetos preposicionales, etc. La subcategorización queda así reflejada. La opcionalidad (de un argumento, por ejemplo) se marca, de otro modo se considera obligatorio.
En los patrones-fs se colocan variables en las posiciones
ROOT que el lexema selecciona, que se identifica por la variable $var0. De
este modo es posible la herencia de las estructuras, ya que no se adscribe a un lexema
determinado, sino a una clase (de ahí el uso de variables). Las variables consecutivas ($var1,$var2,...)
identifican otros nodos en la estructura-f con los que el lexema mantiene dependencias
sintácticas o semánticas. Por ejemplo, el siguiente patrón-fs es apropiado para
cualquier verbo monotransitivo:
((root &var0)
(subj ((root $var1) (cat n)))
(obj ((root $var2) (cat n))))
En los casos de entradas para frases idiomáticas, verbos con
partícula, colocaciones no composicionales, etc., el atributo ROOT de un patrón-fs puede
estar seguido de un lexema específico en lugar de una variable. Por ejemplo la acepción
de kick que define el modismo kick the bucket seleccionará un OBJ con ROOT +bucket-1,
donde +bucket-1 es un identificador de lexema para la acepción normal de bucket.
Además, en el patrón-fs, el par atributo:valor estará seguido de un símbolo null-sem,
para indicar que este sentido de bucket no contribuye a la semántica del modismo.
Por tanto, además de especificar la estructura sintáctica, la zona SYN-STRUC conforma el interfaz con el significado, ya que el patrón-fs indica una interacción con el patrón de significado de la zona SEM, dando cuenta así del hecho de que ciertas porciones del patrón de significado de una frase o cláusula están determinadas composicionalmente por la semántica de los componentes (Principio de Composicionalidad). La estructura del patrón de significado resultante está determinada no sólo por los patrones semánticos de cada uno de los componentes, sino también por su relación sintáctica en la estructura-f.
La zona SEM proporciona la proyección para la representación semántica resultante (TMR). Cada una de estas zonas es en realidad un fragmento TMR subespecificado, es decir una estructura semántica con variables, del mismo modo que en la zona SYN-STRUC.
Antes de mostrar cómo funciona el analizador semántico deberíamos describir los otros dos elementos relevantes: la ontología y las TMRs.
Como hemos mencionado, la ontología de Mikrokosmos comenzó a gestarse con el sistema KBMT-89 (ver sección 3.3.3). El concepto de ontología necesita ser introducido para demarcar lo que por él entendemos en este trabajo. Una definición de diccionario típica de este término es "la rama de la metafísica que estudia la naturaleza de la existencia". En la KBMT la ontología es una entidad computacional, y no ha de ser considerada como una entidad natural que se descubre, sino como recurso artificial que se crea (Mahesh 1996). Un elemento clave en los sistemas de KBMT es el conjunto de símbolos utilizados para representar el significado interlingüe así como la estructura de la representación del significado. Este conjunto de símbolos esta fundado en una fuente de conocimiento independiente de la lengua que denominamos ontología. De este modo, deberemos considerar esta fuente como el repositorio de conceptos (más concretamente una especificación de una conceptualización) que establecen conexiones entre los símbolos de una lengua y sus referentes en el mundo o submundo que se contempla.
En la KBMT la ontología establece un nexo de unión entre las distintas lenguas, ya que lo que se representa en ella son conceptos, y por tanto independientes de la lengua. En este sentido cabe contemplarla como un cuerpo de conocimiento sobre el mundo o dominio (submundo) que:
De forma muy elemental, una ontología contiene información sobre33
Las principales razones para usar una ontología son las siguientes (Mahesh 1996:3):
Además, las ontologías tienen otras funcionalidades en KBMT:
El papel concreto que la ontología dentro del sistema Mikrokosmos se muestra gráficamente en la Figura 3.23 (Mahesh 1996:5).
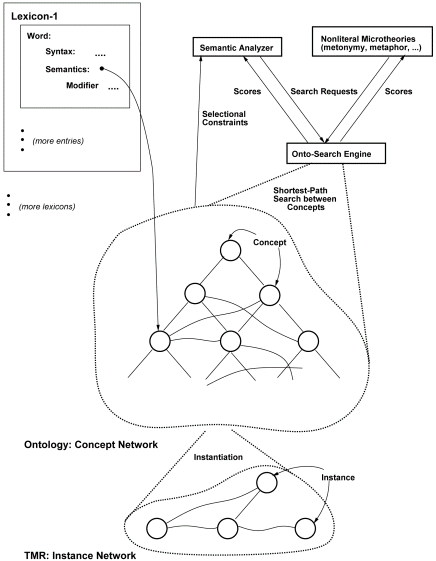
Figura 3.23 El papel de la ontología en el sistema Mikrokosmos
La ilustración muestra un lexicón de análisis donde las palabras están proyectadas sobre la ontología junto con posibles modificadores que aumentan las selecciones de restricción representadas por las relaciones conceptuales en la ontología. Estas modificaciones permiten que el sistema capture los matices de significado en las distintas lenguas. Cada uno de los lexicones, independientemente de su lengua o de si es de análisis o de generación, se proyecta sobre el mismo conjunto de conceptos en la ontología.
Como vemos, los conceptos de la ontología son los ladrillos que el lexicón (estáticamente) y el analizador (dinámicamente) usan para construir la interlingua (TMR).
El principal problema con la construcción de ontologías es obviamente la enorme dificultad y esfuerzo que conlleva. Los intentos de generar ontologías de forma automática o semi-automática han dado siempre escasos frutos, imponiéndose la realización manual de la misma. En Mikrokosmos se optó por desarrollar una serie de herramientas que facilitasen la construcción manual de la ontología. Estas herramientas se encargan de comprobar la consistencia de la información introducida y de generar el código (LISP) necesario a partir de la información que el operador introduce mediante el interfaz gráfico. La Figura 3.24 (Mahesh & Nirenburg 1995a:8) muestra este interfaz para el concepto acquire.
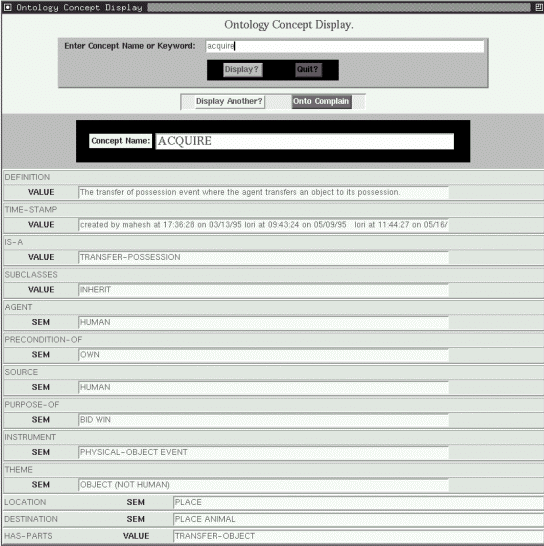
Figura 3.24 Representación en marco del concepto acquire
De todos modos, se trata de una ardua labor, porque conlleva la estructuración del conocimiento humano partiendo no desde un dominio determinado sino desde el nivel más alto. En el Capítulo 5 expondremos la estructura y contenido de la ontología de Mikrokosmos, así como la adaptación que de ella hemos realizado para poder utilizarla en nuestro trabajo. Para dar una idea de su construcción en este apartado, la Figura 3.25 muestra los niveles superiores de la jerarquía.
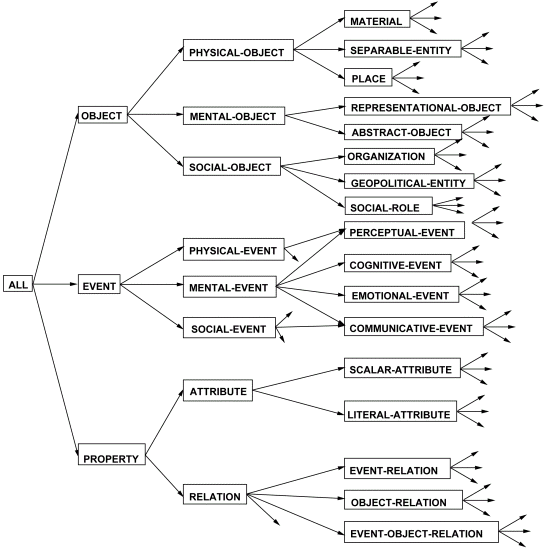
Figura 3.25 Niveles superiores de la ontología de Mikrokosmos
Como se puede observar existen tres entidades superiores, OBJECT, EVENT y PROPERTY34 a partir de las cuales se desarrollan todas las demás. La jerarquía es una red semántica de marcos, cuya definición formal será expuesta en el capítulo siguiente.
Cada uno de estos marcos posee una rica estructura interna que le permite una gran expresividad. La ontología puede ser considerada como una entidad autónoma en el sentido de que se define a sí misma. Por ejemplo, todas las propiedades adscritas a los objetos o eventos (excepto algunas de significado especial y otras de seguimiento, como la definición en lenguaje natural) se hayan definidas en algún punto de la rama property.
Por otra parte, las propiedades de los objetos y eventos se heredan a lo largo de los sucesivos niveles de la jerarquía. Por ejemplo, todos los events heredan por omisión la propiedad de requerir un agent. Si especificamos esta característica al nivel event, todos los conceptos hijos de éste heredarán esta propiedad. Además, la herencia puede ser no monotónica, también llamada herencia negativa, es decir, ha de ser posible especificar que algún elemento no herede alguna propiedad. Por ejemplo, los passive-cognitive-events y los involuntary-perceptual-events no requieren un agente.
Las entradas del lexicón son referidas a uno o más de los marcos contenidos en la ontología con lo que se consigue acceder a toda la información contenida en ésta, simplificando enormemente la cantidad de información requerida en el lexicón propiamente y eliminando la redundancia.
La creación de una ontología de estas características resulta enormemente interesante pero también tropieza con una serie de problemas que no existen en la lexicografía y que requieren plantearse algunas normas a seguir. Los diseñadores de Mikrokosmos establecieron esta normativa para la creación de su ontología además de establecer una serie de restricciones en el interfaz del lexicógrafo. Volveremos sobre este tema en el Capítulo 5 y discutiremos algunas de las decisiones adoptadas cuando describamos la adaptación que nosotros hemos hecho de esta ontología para utilizarla en nuestro sistema, así como de las repercusiones que esta adopción tiene sobre nuestro lexicón.
Como vimos en la Figura 3.26, el principal papel de la ontología en el sistema Mikrokosmos es la generación de las TMRs. La idea de una representación abstracta del significado del texto estaba ya presente en el origen de este sistema, es decir, en KBMT-89. Por ejemplo (Brown & Nirenburg 1990:42) ya hablan de un "set of knowledge structures that we call the text meaning representation."
Como ya hemos mencionado una TMR es una descripción independiente de la lengua (interlingua) del significado contenido en un texto en una lengua natural. Una TMR se puede considerar también como una instanciación de un fragmento de la ontología. Es decir, los conceptos contenidos en la ontología se pueden considerar como variables que son instanciadas mediante las palabras y frases de un texto.
Puesto que ha de ser independiente de cualquier lengua natural, esta especificación debe ser también independiente de la sintaxis (Beale, Nirenburg & Mahesh 1995). Por ejemplo, se evita el uso de términos como "clause", "phrase", "tense", etc. que se asocian con las estructuras sintácticas particulares de una determinada lengua. El analizador sintáctico y el analizador semántico procesan el texto input y generan TMRs parciales. La Figura 3.26 (Beale, Nirenburg & Mahesh 1995) muestra una TMR parcial para la frase input:
"El grupo Roche, a través de su compañía en España, adquirió Doctor Andreu, se informó hoy aquí"
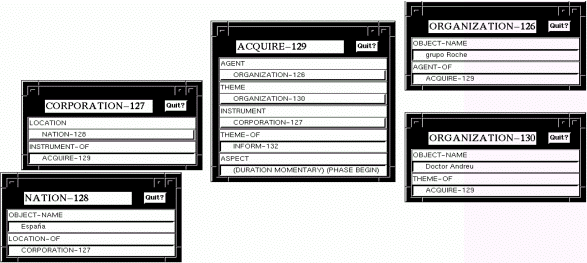
Figura 3.26 TMR parcial de una oración de ejemplo
Las TMRs parciales usan el mismo esquema de representación (basado en marcos) que el lexicón y la ontología. Como podemos ver, los marcos incluyen información que determina las relaciones entre ellos. Cada uno de los elementos que los analizadores han determinado que contienen significado léxico son asignados a un concepto en la ontología y representado en forma de marco. Con el input mencionado, se obtiene el output de la Figura 3.26. El significado de esta oración está compuesto de un evento INFORM-13235 ejecutado por un agente HUMAN-131. El tema del evento INFORM-132 es un evento ACQUIRE-129 donde el agente ORGANIZATION-126, denominado "grupo Roche" adquirió el tema, ORGANIZACION-130, llamado "Doctor Andreu". Esta adquisición se llevó a cabo mediante el instrumento, CORPORATION-127, que está emplazado en el objeto NATION-128 llamado "España". En otras palabras, el significado de la oración tal y como aparece en esta TMR parcial es:
"Alguien informó que la organización llamada "grupo Roche" adquirió la organización llamada "Doctor Andreu" a través de la corporación situada en la nación llamada España."
En la generación de esta estructura el analizador semántico juega un papel determinante. Nos detendremos a analizar el funcionamiento de éste porque nos puede dar una idea del uso más evidente que se le puede dar a una ontología y porque pensamos que es uno de las mejores metodologías que se han propuesto para esta difícil tarea. El analizador es el encargado de combinar la información procedente del lexicón y la ontología y aplicarla al input para generar la TMR parcial correspondiente. Este analizador toma la salida del analizador sintáctico. Éste es el mismo que el ya descrito Panglyzer, desarrollado para Pangloss. El analizador semántico se limita a decidir cuál de las distintas acepciones es la adecuada en el contexto. Los pasos que sigue para ello son los siguientes (Beale, Nirenburg & Mahesh 1995):
Sigamos estos pasos con la oración de ejemplo anterior. Las posibles proyecciones de la frase sobre los conceptos de la ontología son las siguientes:
| Grupo Roche ORGANIZATION |
a-través-de LOCATION INSTRUMENT |
su OWNER |
compañía CORPORATION SOCIAL-EVENT |
en LOCATION TEMPORAL |
España NATION |
adquirir ACQUIRE LEARN |
Dr. Andrew HUMAN ORGANIZATION |
La labor del analizador semántico es decidir cuál de los conceptos es el aplicable en el contexto, es decir, desambiguar aquellas palabras que se puedan proyectar sobre más de un concepto de la ontología.
En primer lugar se recogerían las dos acepciones posibles para "adquirir" mencionadas anteriormente, con las dos proyecciones a los conceptos de la ontología acquire y learn. Para cada una de ellas se examina la zona SYN-STRUC para ver si encaja con la estructura de la frase. Si esto es así, las variables deben ser ligadas a las instancias (palabras de la oración) correspondientes. En el caso de "adquirir" ambas acepciones tienen una zona SYN-STRUC idéntica, así que el ligamiento36 de variables (Figura 3.27) se aplica a ambas y el proceso de desambiguación no concluye.
| SYN-STRUC de "adquirir | Sintaxis del input | |
((root $VAR0) (cat v) (subj ((root $VAR1) (cat n))) (obj ((root $VAR2) (cat n))) ) |
 |
((root ADQUIRIR-1) (cat v) (subj ((root GRUPO-ROCHE-2) (cat n))) (obj ((root DR-ANDREW-3) (cat n))) (pp-adjunct ((root A-TRAVES-DE-4) (obj ((root COMPAÑIA-5) (mod ((root SU-6))) (pp-adjunct ((root EN-7) (obj ((root ESPAÑA-8)))))))))) |
Figura 3.27 Ligamiento de variables para "adquirir"
A continuación el analizador semántico examina la zona SEM de cada una de las acepciones para construir una lista de restricciones que deben ser satisfechas para cada uno de ellos. Estas restricciones se generan a partir de varias fuentes: las selecciones de restricción y roles semánticos que el predicado requiere y las posibilidades de las palabras en la oración para funcionar como sus argumentos.
Para comprobar las restricciones, Mikrokosmos utiliza un algoritmo de búsqueda ontológico. Este algoritmo determina las distancias entre conceptos (en la ontología) y devuelve un índice según su cercanía. Esta función permite adivinar usos metafóricos o metonímicos de algunas palabras. Por ejemplo, si se pregunta al sistema si acquire es un event, el índice devuelto será 1.0, puesto que la relación es directa (acquire is-a event), pero si se le pregunta si organization is-a human, el índice devuelto es 0.9, basado en la propiedad organization has-member human. Esto indica que organization puede funcionar en lugares donde human sería el valor por omisión (agente de acquire, por ejemplo).
A continuación se determinan las mejores combinaciones de acepciones, también mediante un índice. Este paso es determinante en muchas ocasiones. En el ejemplo que estamos utilizando se realizarían las siguientes decisiones:
Éste es el proceso de desambiguación básico, pero además, en Mikrokosmos se están experimentando otras muchas técnicas computacionales avanzadas para la resolución de la ambigüedad enfocadas a problemas específicos de cada lengua. Se trata de técnicas como el análisis de dependencias, técnicas de recuperación ante fallos, uso de información estadística y colocacional, etc. (Beale, Nirenburg & Mahesh 1995).
El proceso de análisis para la generación de las TMRs no concluye con el análisis semántico. Estas representaciones no son suficientes para capturar el significado del texto. También se necesita información pragmática y discursiva, así como las relaciones entre los componentes de significado. Para facilitar esta labor, la especificación TMR de Mikrokosmos contiene una notación especial para representar actitudes, relaciones, actos de habla, tiempo, cantidades, proporciones y conjuntos (Beale, Nirenburg & Mahesh 1995).
Si examinamos de nuevo la Figura 3.21 observaremos que esto precisamente se consigue mediante las ya mencionadas microteorías. Éstas constituyen quizá la principal novedad a nivel teórico del proyecto Mikrokosmos. Su desarrollo se vio motivado por la idea de que no se puede aspirar a conseguir una única teoría que solucione todos los problemas que plantea la lingüística computacional en general (Levin & Nirenburg 1994; Nirenburg, Attardo & Brown 1994; Mahesh & Nirenburg 1995a,b), por lo que es preciso recurrir a técnicas específicas para problemas concretos.
La microteoría más desarrollada hasta ahora es la de dependencia léxico-semántica, que es la microteoría subyacente a todo el proceso de análisis del significado de los textos y en la que se especifica la estructura básica de los eventos o estados y sus propiedades (Beale, Nirenburg & Mahesh 1995). Así, se obtiene la TMR final, es decir, la interlingua, que servirá de input para el proceso de generación37.
Para finalizar este apartado mostramos la plantilla que sirve de base para la creación de las TMRs. Las palabras entre corchetes son explicaciones que no aparecerían en una TMR real. En ella podemos apreciar una división en ocho secciones:
Los valores de muchas de las propiedades definidas se dan en forma de puntuación en un ámbito de 0 a 1, donde el valor por omisión es 0.5, con lo que se permite el uso técnicas de cálculo difuso38.
En suma, las TMRs suponen un formato altamente estructurado a partir del cual generar el texto correspondiente sin tener en cuenta la lengua de origen o la lengua meta, es decir, el objetivo último de la TA interlingüe.
Filename: [filename]
Last-modified: [date of most recent modification to the file]
JJV####.tmr [filename] [or EJV####.tmr for English JV document]
DD YYMMDD [document date]
["table of contents"]
speech-acts(1) %statement_1
propositions(2) [list all propositions in the TMR]
heads(3) [list all heads in the TMR]
stylistic-factors(4) %style_1 (5)
attitudes(6) [list all attitudes in the TMR]
modalities(7) [list all modalities in the TMR]
temporal-relations(8) [list all temporal relations in the TMR]
focus(9) [list all focuses in the TMR]
coreferences(10) [list all coreferences in the TMR]
domain-relations(11) [list all domain relations in the TMR]
textual-relations(12) [list all textual relations in the TMR]
----
["speech act section"]
%statement_1
scope [list all the heads in the TMR]
speaker *author*
hearer *reader*
time(13) %time_0 [%time_0 represents the document date from
the text header]
focus %focus_1
modality %modality_1
style %style_1
%time_0
at YYMMDD [publication date (e.g. 940614)]
%focus_1
scope [head (or heads) representing the primary focus of the
article]
value 0.6 [decimal value ranging from 0-1]
%modality_1
type epistemic
value 1
attributed-to *author*
scope [list all the heads in the TMR]
time %time_0
%style_1
scope %statement_1
formality 0.5 [0.5 is the default value for neutral text as in
newswires]
respect 0.5
politeness 0.5
simplicity 0.5
color 0.5
force 0.5
directness 0.5
----
["TMR body"]
[type first sentence of the translation here]
----
;;"[type main clause of the first sentence here]..."
%proposition_1
head %[head (event) in the main clause]_#
attitude
modality
time %time_1
aspect(14) %aspect_1
polarity(15) positive [or 'negative']
%head_# [head (event) in the main clause]
agent(16) [the typical slots for an event are often described as
case roles or circumstantial roles]
theme
cotheme(17)
accompanier
beneficiary
experiencer
source
destination
instrument
location
path
degree
purpose
use
means
manner
focus
%aspect_1
phase [possible fillers: begin, end, continue]
iteration [possible fillers: single, multiple]
duration [possible fillers: momentary, prolonged]
telicity [possible fillers:yes,no]
----
;;"[type next clause here]"
[repeat as above.]
...
[The attitudes, modalities, temporal relations, and domain relations
are filled in once all the sentences in the text have been represented
in the TMR; these are followed by coreferences. The following shows
the format for this final section of the TMR.]
------
["attitude section"]
;;"[Provide a gloss of the portion of text in which the first attitude
;; occurred.]..."
%attitude_1
type [possible fillers: evaluative, salient]
value [decimal value between 0 and 1]
attributed-to [default is *author* for newswires]
scope [any part of TMR]
time
;;"[Gloss.]"
%attitude_2
type
value
attributed-to
scope
time
...
------
["modality section"]
;;"[Provide a gloss of the portion of text in which the modality occurred.]..."
%modality_2
type [possible fillers: deontic, epistemic, expectative,
potential, volative]
value [decimal value between 0 and 1]
attributed-to [default is *author* for newswires]
scope [any part of TMR]
time
;;"[Gloss]
%modality_3
type [possible fillers: deontic, epistemic, expectative,
potential, volative]
value [decimal value between 0 and 1]
attributed-to [default is *author* for newswires]
scope [any part of TMR]
time
...
------
["temporal relation section"]
;;[Gloss the first temporal relation.]
%temp-rel_1
type [possible fillers: at, after, during]
arg_1
arg_2
;;[Gloss the second temporal relation.]
%temp-rel_2
type
arg_1
arg_2
...
------
["domain relation section"]
;;[Gloss the first domain relation.]
%domain-rel_1
type [possible fillers: causal, volitional, non-volitional, reason,
enablement, purpose, condition, result, conjunction, addition,
enumeration, contrast, adversative, concessive, comparison,
particular, representative, reformulation, inclusive-or,
exclusive-or, definition, equivalence]
arg_1
arg_2
value [(optional) decimal value between 0 and 1]
scope [(optional)]
;;[Gloss the second domain relation.]
%domain-rel_2
type
arg_1
arg_2
value [(optional) decimal value between 0 and 1]
scope [(optional)]
...
------
["coreference section"]
%coreference_1 [e.g. %company_1 %company_4 (where both refer to the same
company)]
%coreference_2
...
NOTAS
Anterior I Siguiente I Índice capítulo 3 I Índice General