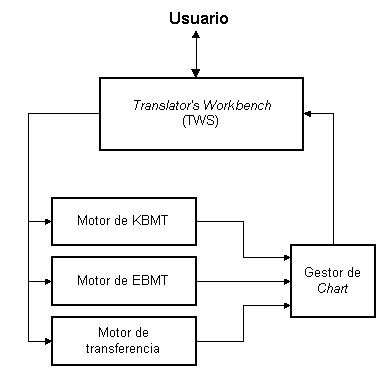
Figura 3.18 Arquitectura Multi-motor de Pangloss Mark III
Este gran proyecto de TA se llevó a cabo conjuntamente entre el CMU/CMT, la New Mexico State University (NMSU) y el Information Sciences Institute de la University of Southern California (USC/ISI). Las lenguas para las que se creó fueron el español y el inglés, centrándose en textos de economía y más concretamente sobre fusiones y adquisiciones de empresas.
En principio, este sistema de TA comenzó como un sistema de KBMT puro, sin embargo, en la evaluación de la primera configuración, el sistema Pangloss Mark I no dio los resultados esperados. Por ello se decidió adoptar una postura más ecléctica aprovechando la experiencia de los investigadores del CMU/CMT con el sistema KANT. En la segunda etapa, el sistema Pangloss Mark II, se optó por incluir un motor de traducción basado en transferencia con extensos glosarios frasales. Los resultados de la evaluación de este sistema (White & O’Connell 1994) fueron considerablemente más optimistas que los anteriores.
El motor de KBMT no fue abandonado, sino que se mantuvo como la versión "mainline", mientras que el motor de transferencia fue considerado como solución intermedia para conseguir resultados a corto plazo (Nirenburg 1995). Debido a los buenos resultados obtenidos se decidió integrar definitivamente el motor de transferencia y usarlo conjuntamente con el motor de KBMT. Además se decidió incluir y mejorar las técnicas de EBMT usadas en el sistema KANT, de modo que el sistema definitivo, Pangloss Mark III, consta de tres motores de traducción distintos integrados en un solo sistema:
Figura 3.18 Arquitectura Multi-motor de Pangloss Mark III
La integración de estos tres motores de traducción implica la evaluación automatizada del mejor resultado. El texto se traduce con los tres motores, los resultados se recogen en una estructura de datos y se selecciona la mejor traducción mediante una serie de reglas heurísticas. Esta estructura de datos es denominada chart. Los resultados obtenidos en el chart son evaluados por un algoritmo denominado chart-walk (Nirenburg 1995)29 y el resultado de éste se envía a la estación de trabajo del traductor (TWS: Translator’s Workstation).
En este entorno gráfico el usuario puede descartar la traducción elegida por el algoritmo, así como editar el texto traducido, para lo que cuenta con diversas herramientas que pueden acceder a diversas fuentes de información léxica. Este entorno de post-edición para TA, que en el fondo no deja de ser un editor aumentado, es denominado CMAT (Component Machine-Aided Translation) (Frederking et al. 1993).
El motor de KBMT es por tanto el principal en Pangloss. Básicamente consiste en dos módulos: un analizador, denominado Panglyzer y un generador, denominado Penman. Además existe un mapper que se encarga de convertir el output de Panglyzer a un formato aceptable como entrada para Penman. Esto es debido a que estas dos herramientas fueron desarrolladas independientemente por dos equipos de investigación diferentes; su utilización conjunta fue una decisión a posteriori.
La función básica del analizador Panglyzer es generar, para cada una de las frases del texto de entrada, un conjunto de representaciones semánticas clasificadas en base a un índice de probabilidad. Estas representaciones son después procesadas por un "aumentador" que, ya sea automáticamente o de forma interactiva, selecciona una de ellas. La Figura 3.19 (Farwell & Helmreich 1995) muestra la arquitectura del sistema, que consta de ocho componentes.
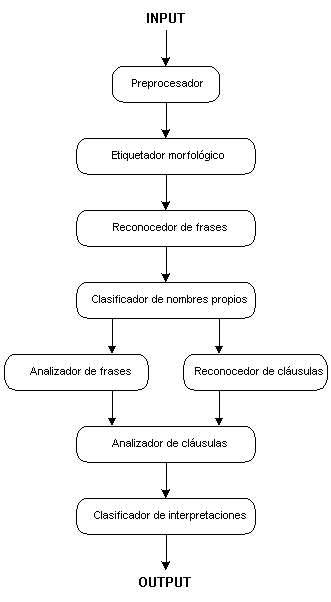
Figura 3.19 Arquitectura de Panglyzer
Las funciones que realizan los distintos componentes son las siguientes:
Los detalles concretos del proceso y los distintos algoritmos pueden encontrarse en Farwell & Helmreich (1995).
Como ya hemos mencionado la salida de Panglyzer (listas anidadas Prolog) es convertida por un mapper (Hovy 1995a) a una entrada aceptable para el generador Penman (listas anidadas Lisp).
El sistema de generación de inglés Penman (Matthiessen & Bateman 1991) era un desarrollo llevado a cabo de forma independiente en la USC/ISI desde 1978. Penman comprende varios componentes. La gramática, llamada Nigel, está basada en la teoría sistémico-funcional de Halliday (Halliday 1985), que ya había servido de base al famoso programa de IA SHRDLU (Winograd 1972). Nigel es una red de más de 700 nodos llamados "sistemas" en donde cada nodo representa una alternación gramatical mínima. Para generar una oración Penman atraviesa la red guiado por el input y por reglas preestablecidas. En cada uno de los nodos Penman selecciona un atributo hasta que acumula los suficientes para especificar una oración completa. Después de construir un árbol sintáctico y elegir las palabras que satisfagan los atributos seleccionados, Penman finalmente genera la oración.
Además de la red, el sistema también contiene otras fuentes de información, concretamente un lexicón de más de 90.000 palabras inglesas (con definiciones, información morfológica, etc.), cuyo proceso de adquisición semiautomático describimos más adelante y el llamado Penman Upper Model (Bateman et al. 1989; Bateman 1990), una pequeña taxonomía de generalizaciones (unas 250 abstracciones muy generales de objetos, procesos y relaciones) jerárquicamente organizada específicamente para el proceso lingüístico. Esta taxonomía sirve de enlace entre los términos utilizados en el dominio de la aplicación del usuario y los términos utilizados en Penman.
En Pangloss, este "Upper Model" fue incrustado en la ontología (que describimos a continuación) y se asegura de que cualquier término de ésta utilizado como input para Penman será manipulado correctamente para generar la frase u oración inglesa apropiada.
La ontología de Pangloss se puede contemplar como la conjunción de varias fuentes unificadas en un único formato. Creemos que su característica fundamental es el modo en que fue elaborada. El punto de partida fueron dos pequeñas ontologías realizadas de forma manual, la ya mencionada contenida en el Penman Upper Model desarrollada en el USC/ISI, por un lado y otra desarrollada en el CMU/CMT para KBMT-89, llamada ONTOS (ver el apartado 3.3.3) (Kaufmann 1991; Carlson & Nirenburg 1990). La populación masiva consiguiente se realizó usando las técnicas descritas en el capítulo anterior respecto a la adquisición de información léxica desde MRDs. Concretamente se utilizó el LDOCE, el Collins español-inglés y WordNet (Miller 1990, 1993) (ver apartado 2.4.2). El proceso de fusión de la información procedente de todas estas fuentes y su recopilación se muestra en la Figura 3.20 (Knight & Luk 1994).
La ontología, junto con su interfaz, recibió el nombre de SENSUS (Knight 1993), siendo considerado el conjunto como una base de conocimiento.
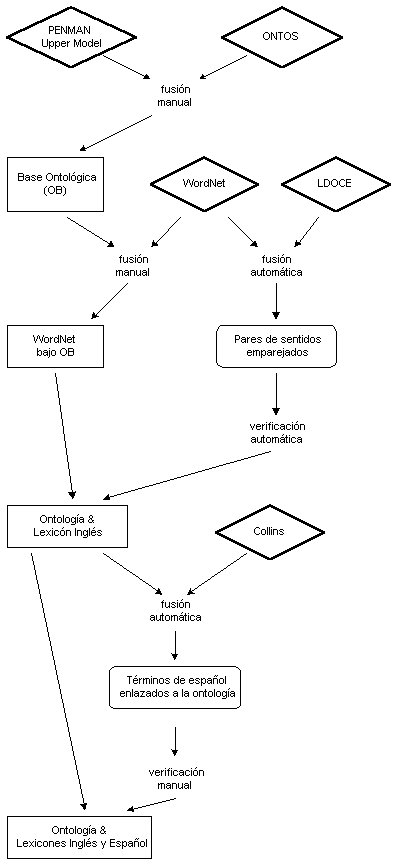
Figura 3.20 Proceso de fusión de información en la ontología de
Pangloss
En realidad tenemos dos ontologías reales que actúan como "filtro de conocimiento" para las entradas léxicas de los distintos lexicones. Como veremos en el siguiente apartado, esta disposición es muy mejorable, la principal razón de haber optado por ella se debe simplemente a que permite la utilización de procesos semiautomáticos.
El rendimiento que ofrece es sin embargo inferior al obtenido cuando la ontología de conceptos es realizada de forma manual y adquiere proporciones a gran escala. No debemos olvidar que la ontología real de la que se parte consta únicamente de unos 700 conceptos. Las posibilidades de la ontología de ONTOS (unos 2000 conceptos) no pueden ser explotadas ya que en realidad es la ontología de Penman la que actúa como filtro en todo momento. Por supuesto, se consigue mayor riqueza descriptiva cuanto mayor es el número de conceptos contenidos en la ontología.
De hecho, ya mencionamos al principio de este apartado que la decisión de recurrir a la utilización de los otros dos motores de traducción en el sistema Pangloss obedece a la necesidad de mejorar los pobres resultados obtenidos con el motor de KBMT únicamente y pensamos que esta ontología fue en gran parte responsable de estos resultados. No nos extenderemos ahora en el concepto de ontología ni en las características que una ontología orientada al procesamiento del lenguaje natural debe presentar, ya que introduciremos estos aspectos en el siguiente apartado.
En cuanto al motor de transferencia (Nirenburg, Attardo & Brown 1995), Pangloss utiliza un sistema de transferencia tradicional simple. La transferencia se lleva a cabo mediante los lexicones elaborados para el motor de KBMT, especialmente el diccionario de Collins más un conjunto de glosarios creados de forma manual.
NOTAS
Anterior I Siguiente I Índice capítulo 3 I Índice General