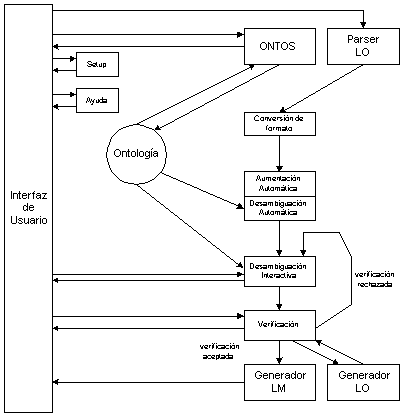
Figura 3.15 Proceso de traducción en KBMT-89
El primer prototipo de KBMT que se construyó en el CMT de la Universidad de Carnegie Mellon tenía como finalidad traducir diálogos entre doctor y paciente para los idiomas inglés y japonés. Combinaba análisis y generación basadas en gramáticas de unificación, con interpretación semántica y proyección de estructuras de interlingua. La primera aplicación funcional de este prototipo para la traducción de documentos fue KBMT-89 (Goodman 1989; Goodman & Nirenburg 1989, 1992).
KBMT-89 traducía bidireccionalmente manuales de instalación del IBM PC, generando traducciones de alta calidad. Es interesante analizar el funcionamiento de este sistema, porque en él encontramos el núcleo principal de sistemas modernos, mucho más complejos. El sistema KBMT-89 comprende un conjunto de componentes distribuidos en distintos procesos Lisp (que se ejecutaban en distintas estaciones de trabajo). Los principales componentes son (ver Figura 3.15):
El interfaz de usuario, junto con el sistema de desambiguación y verificación se denominó augmentor.
El analizador sintáctico de KBMT-89 está construido en torno a un parser desarrollado por Tomita en 1986 (Tomita 1986; Tomita & Carbonell 1986) denominado "Universal Parser". Para reducir el número de ambigüedades se aplican restricciones semánticas desde las primeras fases del análisis. Este analizador genera una representación de listas anidadas Lisp que contienen la información sintáctica y semántica de cada una de las posibles interpretaciones de la oración de entrada. El augmentor extrae la información semántica, elimina análisis duplicados y convierte las listas Lisp en árboles de marcos estructurados jerárquicamente25. La aplicación encargada de procesar estas jerarquías se denomina FRAMEKIT26. Estas jerarquías de marcos producidas tras la conversión de formato forman las representaciones de interlingua (también denominadas "textos de interlingua" (ILT: Interlingua Text).
Figura 3.15 Proceso de traducción en KBMT-89
El "aumentador" automático y desambiguador de KBMT-89 consiste en un reconocedor de patrones (pattern matcher) y un algoritmo de resolución de anáfora pronominal llamado MARS (Multiple Anaphora Resolution Strategies). El reconocedor realiza algunos cambios estructurales sobre los marcos enlazados de FRAMEKIT y añade información directamente derivable de la que produce el parser.
A continuación se llevan a cabo los procesos de desambiguación automática, de los cuales el de resolución de anáfora mediante MARS fue el único implementado en KBMT-89, dejando procesos de desambiguación automática más complejos para sistemas posteriores. MARS funciona mediante restricciones semánticas (basadas en papeles temáticos), y sintácticas (topicalización) y otras estrategias preferenciales. Primero se aplican las restricciones a los referentes candidatos y luego las preferencias. MARS intenta encontrar un referente para cada uno de los pronombres y frases nominales determinadas en los ILTs y añade enlaces a los referentes si los encuentra. Si después de este proceso de desambiguación automática aún quedan múltiples ILTs, éstos se usan como input para el proceso de desambiguación interactiva. Mediante un interfaz gráfico basado en menús, el usuario puede decidir cuál de las lecturas es la más apropiada en el contexto. Una descripción detallada del funcionamiento de este proceso interactivo de desambiguación puede encontrarse en Brown & Nirenburg (1990).
Como podemos comprobar nos encontramos ya con un sistema complejo de TA basada en el conocimiento. Este primer sistema funcional desarrollado en el CMT es el precursor de otros aun más complejos, aunque la esencia de su funcionamiento (parsers, etc.) la encontramos ya aquí.
La teoría lingüística de la que se parte en KBMT-89, y en los consiguientes desarrollos del sistema (KANT, Pangloss, Mikrokosmos) está basada en el concepto general de linking, concretamente en el trabajo de Beth Levin (Levin 1993, 199527; Levin & Tenny 1988), que se refiere al establecimiento de asociaciones entre argumentos semánticos y relaciones gramaticales.
Este concepto se basa en la correspondencia entre la sintaxis y la semántica y el establecimiento de regularidades (linking regularities28) que son las que permiten explicitar generalizaciones para ser usadas en una jerarquía con herencia múltiple.
El concepto de linking ha sido uno de los más relevantes de los desarrollados en cuanto a la formalización de la semántica léxica en los últimos tiempos, estando en la base los formalismos gramaticales lexicalistas más extendidos hoy día (LFG, HPSG), ya que permite la formalización de las correspondencias entre realizaciones sintácticas particulares y papeles semánticos determinados. Por ejemplo, en el uso causativo de break, la función de sujeto está enlazada (linked) al papel temático de agente, mientras que el objeto está enlazado al de meta (o tema). Lo interesante es observar que este mismo patrón se da en otros muchos verbos que también denotan un cambio de estado. Esta regularidad observada puede ser formalizada en una clase de verbos de cambio-de-estado que comparten las mismas peculiaridades. Mediante un sistema de representación basado en marcos y con herencia múltiple como el que se propone en KBMT-89, o como el que propondremos nosotros, es posible representar de forma económica estas regularidades.
El sistema de representación basado en marcos es además un soporte excelente para la representación de conocimiento del mundo / dominio. De hecho, como veremos en el siguiente capítulo, éste fue el objetivo para el que se diseñó en principio. El hecho de usar el mismo sistema de representación para la información léxica y la de conocimiento del mundo tiene la ventaja de que el sistema resulta más homogéneo al usar un solo entorno. No obstante, la utilización de tal tipo de sistemas para el almacenamiento de grandes cantidades de información léxica detallada (de hecho, cualquier tipo de información que implique un gran volumen con un gran nivel de detalle) también tiene sus desventajas. Volveremos sobre este tema en el siguiente capítulo, cuando tratemos las formas en que nuestro sistema podría ser optimizado y formalizado.
A pesar del relativo éxito de KBMT-89, existían dos consideraciones que limitaban el potencial práctico del sistema (Lonsdale, Mitamura & Nyberg 1995):
NOTAS
Anterior I Siguiente I Índice capítulo 3 I Índice General