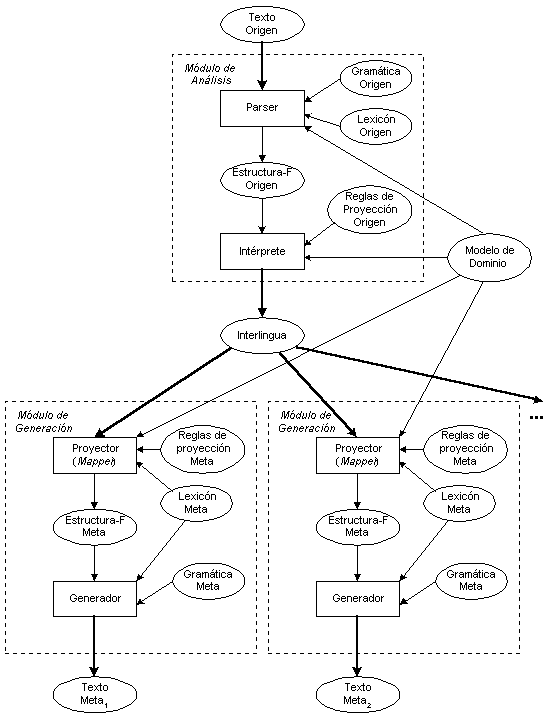
Figura 3.16 Arquitectura en tiempo de ejecución de KANT
El sistema KANT (Knowledge-based Natural Language Translation) (Nyberg & Mitamura 1992), desarrollado también en el CMU/CMT, es un descendiente directo del anterior, incorporando una arquitectura similar. Sin embargo, KANT fue diseñado para trabajar en un ámbito de problemas de traducción mucho más reducido que KBMT-89, resultando en una mayor precisión y mayor velocidad en tiempo de ejecución.
Los objetivos inmediatos de KANT fueron los siguientes (Nyberg & Mitamura 1992):
Para conseguir estos objetivos se utilizaron diversas técnicas que resultaron en un sistema robusto aunque con bastantes limitaciones, sobre todo la imposibilidad de aplicarlo a textos de carácter general. Las principales características de KANT son (Lonsdale, Mitamura & Nyberg 1995):
La Figura 3.16 (Nyberg & Mitamura 1992) muestra esta arquitectura modular.
Figura 3.16 Arquitectura en tiempo de ejecución de KANT
Como se puede ver en este diagrama, KANT hace uso de las siguientes fuentes de conocimiento:
Por lo que respecta a la base lingüística, el "Universal Parser" de Tomita sigue siendo el analizador sintáctico en KANT. Este parser está basado en el formalismo de la Gramática Léxico-Funcional (LFG: Lexical Functional Grammar) (Bresnan 1982). En este formalismo gramatical se postula un único nivel de descripción sintáctica, denominado c-structure, que se corresponde con los árboles sintagmáticos superficiales (ver apartado 3.1.2). Esto es posible porque además se postula un componente léxico enriquecido que da cuenta de las regularidades en las posibles proyecciones de los argumentos (semánticos) sobre las estructuras sintácticas (linking). De este modo, el único nivel de representación sintáctica contemplado (c-structure) coexiste de forma simultánea con una estructura funcional (f-structure) que integra información de la c-structure y del lexicón. Además, mientras que la c-structure difiere de una lengua a otra, la representación de la f-structure, que contiene toda la información necesaria para la interpretación semántica de una oración, es universal, por lo que, en principio, puede ser usada como el componente lingüístico de una interlingua.
En el sistema de KBMT de la CMU/CMT la gramática consiste en un conjunto de reglas independientes del contexto que definen la estructura de constituyentes (c-structure) de las oraciones de la lengua de origen. Las reglas son anotadas con ecuaciones de restricción que definen la estructura funcional del input. El parser compila la gramática en una tabla LR y las ecuaciones de restricción en código Lisp. El parser se ejecuta en tiempo polinómico con bastante rapidez cuando no existen demasiadas ambigüedades, aunque cuando el nivel de ambigüedad es más denso se puede llegar a un tiempo exponencial de O(n3), por tanto, cuanto menos ambigua sea la gramática más rápido será el algoritmo.
En KANT también se mejora el proceso de desambiguación de KBMT-89. En el nuevo sistema existen cuatro estrategias principales para resolver la ambigüedad (Baker et al. 1994):
Obviamente, una de las razones más decisivas en la mejora de la velocidad y la precisión del sistema de desambiguación es la restricción de los dominios y las restricciones semánticas asociadas. En la sublengua de CATALYST (maquinaria pesada), por ejemplo, aproximadamente el 99% de las 9.600 entradas léxicas de palabras simples poseen una única acepción (Baker et al. 1994). Así, la palabra "mat" posee la única acepción de "a layer or blanket of asphalt". De los 100 términos que permanecen ambiguos (siempre dentro de la misma sublengua), el traductor interactúa con el desambiguador léxico mediante el interfaz gráfico. Del mismo modo, las 54.000 frases de nomenclatura de que consta el lexicón frasal son sin excepción no ambiguas.
La adquisición del conocimiento es otro de los aspectos a destacar de KANT. Los lexicones de gran volumen mencionados no fueron creados a mano, sino mediante la utilización de técnicas estadísticas de análisis de córpora textuales. Los textos de la lengua de origen son analizados para obtener unidades léxicas potencialmente relevantes mediante métodos semi-automáticos. A continuación se lleva a cabo un proceso de depuración a mano, pero éste resulta bastante más asequible que la construcción del lexicón desde cero.
La estadística también se usa en KANT para otras tareas (Carbonell, Mitamura & Nyberg 1992):
Como podemos ver, una de las características más sobresalientes de KANT es la integración de técnicas que se adoptó en su implementación. La postura de los creadores de KANT es abandonar posiciones dogmáticas e intentar combinar lo mejor que cada paradigma ofrece (Carbonell, Mitamura & Nyberg 1992). El tipo de técnicas estadísticas utilizadas en KANT provienen del paradigma basado en el ejemplo, que ya mencionábamos en el apartado 3.3.1.
El uso de técnicas provenientes de la EBMT en KANT es bastante limitado. En realidad se reduce al análisis estadístico de los textos para encontrar frases cuyos componentes muestran un índice colocacional estadísticamente significativo. Sin embargo, en el sistema sucesor de este, Pangloss, ya encontramos un uso más extendido de estas técnicas.
Para llevar a cabo estas tareas estadísticas mencionadas, en KANT se implementó el siguiente conjunto de herramientas (Leavitt, Lonsdale, Keck & Nyberg 1994):
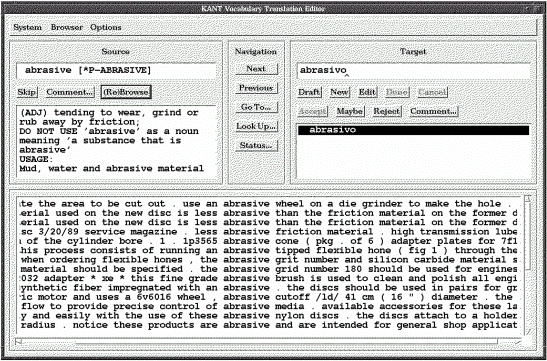
Figura 3.17 El editor de traducción de vocabulario de KANT
Como podemos observar, éstas son técnicas que en principio están fuera del ámbito de la KBMT, sobre todo en lo que respecta a la asignación específica de equivalentes de traducción. El objetivo era por supuesto conseguir resultados a corto plazo. Esto, por otra parte, no significó el abandono de las técnicas de KBMT en el CMU/CMT, sino la integración de todas aquellas metodologías que facilitasen una traducción de alta calidad, ya sean estadísticas (para la obtención de información), o de transferencia.
Anterior I Siguiente I Índice capítulo 3 I Índice General