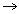
De todos los niveles de análisis expuestos, la sintaxis ha sido durante mucho tiempo y aún sigue siendo el nivel al que la lingüística le ha prestado mayor atención. Está casi exclusiva atención se justifica por dos razones principales en cuanto al tratamiento automático del lenguaje natural (Rich & Knight 1994):
Por esto es evidente que la disponibilidad de un buen parser es determinante para conseguir buenos resultados en los niveles superiores de análisis. Aunque el objetivo del presente trabajo no es éste, nos detendremos a analizar el funcionamiento de los parsers típicos porque es importante para entender las necesidades de información que este tipo de aplicaciones requiere, así como los beneficios que tales aplicaciones pueden obtener de una correcta y exhaustiva estructuración de la información lingüística.
La sintaxis contempla dos modos diferentes, pero no por ello opuestos, de análisis. El primero es el análisis de constituyentes o análisis de estructura de frase: la estructuración de las oraciones en sus partes constituyentes y la categorización de estas partes como nominales, verbales, adjetivales, etc. El segundo es el análisis de las relaciones o funciones gramaticales: la asignación de relacionales gramaticales tales como Sujeto, Objeto, etc.
Desde el punto de vista del parser, una gramática es un conjunto de reglas que describen cómo los distintos constituyentes se pueden combinar. Las combinaciones permitidas por la gramática son consideradas gramaticales, mientras que el resto son agramaticales. Formalmente, una lengua es un conjunto de oraciones; cada oración es una cadena de uno o más símbolos pertenecientes al vocabulario de la lengua. Desde esta perspectiva, una gramática no es más que una especificación formal y finita de este conjunto de oraciones (Grishman 1986). Esta especificación puede ser llevada a cabo por enumeración si el conjunto de oraciones es finito. Si el conjunto de oraciones es infinito o el número de posibles oraciones es demasiado elevado, resulta imposible o poco económico describirlas por enumeración. La otra manera es idear un mecanismo, es decir una gramática, capaz de decidir, mediante la aplicación de un determinado número de reglas, si determinada oración es o no es gramatical.
Tal tipo de gramática suele ser una gramática de estructura de frase o gramática sintagmática (PSG: Phrase Structure Grammar) (Hopcroft & Ullmann 1979). Las gramáticas de estructura de frase han sido y son ampliamente utilizadas en las aplicaciones de análisis del lenguaje natural, ya que se caracterizan por aportar una especificación formal de una lengua, lo cual las hace susceptibles de ser implementadas mediante algoritmos computacionales. Esta implementación, es decir, el conjunto de reglas, junto con el algoritmo que ha de desarrollarlas, es lo que se denomina parser. Una PSG tiene cuatro componentes (Grishman 1986:25):
La operación básica de una PSG es la de reescritura,
es decir, la conversión de una secuencia de símbolos LHS (Left Hand Side) en otra
diferente (RHS: Right Hand Side). Por ejemplo, si a ![]()
nav
nbv donde el símbolo "" denota esta operación de reescritura.
Una lengua definida por una PSG es el conjunto de cadenas terminales (es decir, secuencias compuestas totalmente por símbolos terminales) que pueden derivarse del símbolo inicial S.
La gran mayoría de las gramáticas formales para la descripción formal del lenguaje natural que se han propuesto hasta ahora están basadas en la gramática de estructura de frase, lo cual determina el hecho de que casi todos los parsers estén basados también en ella.
Una sencilla PSG para un subconjunto del inglés podría quedar determinado por el siguiente conjunto de reglas:
Esta gramática, por ejemplo, puede ser directamente
implementada en un sistema prolog, que contenga un intérprete standard DCG (Definite
Clause Grammar) (Pereira & Warren 1980), y podría generar las siguientes oraciones
bien formadas según nuestra gramática:
John cleaned
John cleaned the printer
John cleaned the document
John printed
John printed the printer
John printed the document
? the printer cleaned
? the printer cleaned John
? the printer cleaned the document
the printer printed
? the printer printed John
the printer printed the document
? the document cleaned
? the document cleaned John
? the document cleaned the printer
? the document printed
? the document printed John
? the document printed the printer
Esta pequeña gramática es una gramática independiente del contexto, porque satisface la condición
A
x
donde A es un símbolo no-terminal y x es una secuencia de cero o más símbolos terminales y no-terminales. La principal característica de este tipo de gramáticas (CF-PSG: Context-Free Phrase Structure Grammar) es que emplea un conjunto finito de reglas para especificar la forma en que las categorías LHS se pueden reescribir en la RHS. Cuando una regla determinada especifica una realización determinada, esta realización es siempre posible, independientemente del contexto en la que la categoría LHS aparece, de ahí el nombre.
El problema con este tipo de gramáticas es que, como podemos comprobar en el ejemplo, tienden a generar más oraciones de las necesarias5. Si una gramática puede generar un determinado número de oraciones, significa que el parser también puede reconocerlas como gramaticales para esa gramática.
Como ya hemos mencionado, para poder analizar una frase es necesario encontrar una manera de generar a partir del símbolo inicial S. Básicamente, esto puede hacerse de dos formas diferentes (Grishman 1986; Rich & Knight 1991):
La consideración esencial para la elección de uno de estos dos métodos es la de ramificación, normalmente se usará el método que permita una menor ramificación a partir de los nodos. Además, estos dos enfoques pueden combinarse, y de hecho es usual, en un solo parser. Este método se denomina "análisis ascendente con filtraje descendente" (Rich & Knight 1991) o también "análisis descendente con retrotrazado"; en él el análisis sintáctico discurre esencialmente de forma descendente, pero el parser tiene la facultad de eliminar inmediatamente los constituyentes que nunca podrán combinarse en estructuras de alto nivel sin más que hacer uso de unas tablas que han sido precalculadas para una gramática concreta mediante un sistema de reglas heurísticas. Este algoritmo6 opera sobre una derivación de la forma
O
z1 O
Inicialmente la derivación contiene únicamente el símbolo inicial O. Asumimos que las reglas que tienen una A a la izquierda están Ordenadas: RA,1, RA,2..., RA,n.
Éste se puede considerar como el algoritmo de parsing por antonomasia y se encuentra presente con más o menos variaciones en el corazón de muchos sistemas de NLP. Por supuesto no es el único; se han elaborado parsers dependientes del contexto, parsers transformacionales, parsers basados en las redes de transición aumentadas (ATN: Augmented Transition Networks), e incluso algunos parsers (poco afortunados) para gramáticas dependientes del contexto. Además diversas teorías lingüísticas (incluyendo el modelo generativo-transformacional) han tratado de probar sus hipótesis, entre otros medios, creando parsers basados en sus directrices fundamentales, aunque es bien sabido (p. ej. Gazdar & Mellish 1989) que tales modelos no suelen dar resultados prácticos, ya que su objetivo fundamental no es crear un sistema para ser usado, sino simplemente corroborar determinadas hipótesis.
Las necesidades de enriquecer el lexicón con información de índole semántica quedan patentes incluso en esta pequeña gramática que hemos mostrado. Resulta obvio que la información aportada por nuestra gramática (categorías gramaticales y reglas de reescritura) debe ser complementada por información de otros tipos, especialmente semántica, pero también morfológica, fraseológica, pragmática, etc. La inclusión de información léxico-semántica básica, por ejemplo, bloquearía las dudosas oraciones que hemos marcado con "?", en los que a una entidad que típicamente no puede asumir el papel de Agente (la impresora) muestra propiedades agentivas.
Un parser del tipo descrito anteriormente podría generar un análisis de estructura de frase, normalmente con una representación mediante corchetes, aunque algunos existen programas que pueden convertir ésta en una representación gráfica en forma de árbol, como la siguiente:
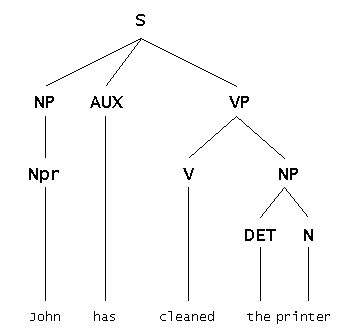
Figura 3.1
Esencialmente, nuestro punto de vista es que para obtener un análisis lingüístico válido para la TA, se necesita un gran nivel de interacción entre los tradicionalmente separados módulos de análisis sintáctico y semántico.
Desde esta perspectiva, la función de un análisis de constituyentes se reduciría a generar la estructura base sobre la que podemos hacer funcionar otros módulos del sistema, aunque por supuesto, como hemos apuntado, en muchas ocasiones el analizador deberá recurrir a otros módulos para poder generar la estructura correcta. Lo más usual, sin embargo, es quedarse en el simple análisis de constituyentes.
Creemos que este modo de actuar obedece a la creencia que durante muchos años imperó en los estudios lingüísticos y de IA de que es posible acometer el análisis lingüístico de una forma modular y aislada según los distintos niveles de análisis.
Como hemos mencionado, durante mucho tiempo todo análisis lingüístico quedó reducido prácticamente a señalar los distintos constituyentes de la oración. Este análisis de constituyentes, sin dejar de ser válido, se debería complementar con un análisis funcional en donde se señalen de forma explícita las funciones o características relacionales de los distintos constituyentes, y que además permita la inserción de otros tipos de información.
La utilidad de este tipo de análisis en la traducción automática es obvia: en algunos idiomas, como el inglés, el orden normal de una oración es sujeto - verbo - objeto, mientras que en otros es diferente. Por ejemplo en japonés el orden normal es sujeto - objeto - verbo. En otros, como el ruso, el orden de los constituyentes que exhiben estas funciones puede ser cualquiera. También se ha de realizar una distinción entre aquellas frases que cumplen las funciones de sujeto, objeto, etc., de aquéllas que sirven como Adjuntos, Modificadores, etc., ya que mientras los primeros suelen ser obligatorios, los segundos no.
La representación de un análisis funcional no es esencialmente diferente de la representación de un análisis de constituyentes. Gráficamente, en lugar de mostrar un árbol donde los nodos son etiquetas que hacen referencia a las distintas categorías, el análisis funcional suele hacerse de forma lineal. Un análisis funcional básico de la oración de ejemplo anterior sería el siguiente:
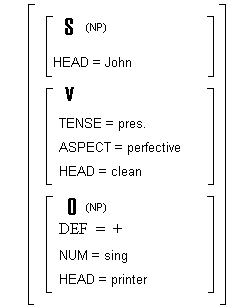
Figura 3.2
Existen algunas diferencias entre estos dos métodos de análisis. En primer lugar los nodos son las relaciones funcionales propiamente y se ha añadido una nueva categoría (head), que es el elemento central en ese sintagma, gramaticalmente hablando: el nombre en un sintagma nominal, el verbo en un sintagma verbal, la preposición en un sintagma preposicional. También se ha perdido el nodo vp (ya que éste no desempeña ninguna función gramatical), consistiendo la representación de las relaciones gramaticales de esta oración en un verbo y dos sintagmas nominales. Además el orden de los distintos elementos es irrelevante puesto que las relaciones gramaticales contienen de forma implícita información sobre el orden de las palabras. Podríamos mostrar los elementos del análisis anterior en cualquier otro orden y la oración resultante seguiría siendo la misma, lo cual no es posible en una estructura arbórea (por tanto, jerárquica) de un análisis de constituyentes.
La diferencia fundamental es sin duda la inclusión de rasgos en forma de pares atributos:valores. En el Capítulo 4 describiremos formalmente este tipo de notación gramatical (estructuras de rasgos) y veremos cómo los formalismos gramaticales modernos combinan reglas de CF-PSG con un sistema de rasgos. Por el momento, baste decir que esta característica permite extender el análisis sintáctico con rasgos semánticos de una forma mucho más natural que si lo hiciéramos con una estructura jerárquica, sobre todo en lo que respecta a la asignación de papeles temáticos, el primer paso para un análisis semántico más profundo.
De este modo, nuestro análisis de ejemplo podría ser fácilmente mejorado con el añadido de los papeles temáticos, o funciones semánticas, que los distintos elementos relacionales tienen:
Figura 3.3
En el presente trabajo abogamos por un análisis de este tipo, que podrá ser sucesivamente enriquecido. Obviamente, la información necesaria que un sistema ha de tener para llevar a cabo tal análisis va más allá de las simples partes de la oración. Éste es precisamente el tema principal de este trabajo: mostrar qué tipo de información es necesaria y cómo esta información ha de estar representada para obtener la máxima funcionalidad y economía de representación, al mismo tiempo que se aboga por una independencia de los datos que garantice su reutilización. La representación, por tanto, deberá ser todo lo independiente que pueda ser con respecto a la teoría lingüística que se encargue del análisis, así como mantener la capacidad de adaptarse a sistemas y entornos computacionales para los que no fue desarrollada en principio.
Por supuesto, el análisis no debe quedarse en las funciones semánticas básicas, en realidad, debería extenderse hasta el conocimiento pragmático y conocimiento del mundo o conocimiento de sentido común.
NOTAS
Anterior I Siguiente I Índice capítulo 3 I Índice General