
En este apartado mostraremos el funcionamiento real, de cara al lexicógrafo, del sistema de base de datos que acabamos de describir. El objetivo fundamental del interfaz es facilitar todas las tareas comunes, no de administración de la base de datos, sino de la labor lexicográfica normal: introducir, modificar y consultar información, generar informes, etc.
El sistema de base de datos que hemos utilizado para la implementación de nuestros esquemas conceptuales, Microsoft Access 976, provee un buen número de herramientas que facilitan la construcción de interfaces con características avanzadas.
Otro objetivo crítico del interfaz es actuar como capa de aislamiento del esquema conceptual (tablas y relaciones) de la base de datos real. El flujo de datos entre el interfaz y el sistema es transparente para el usuario. Además, el DBMS permite establecer restricciones de seguridad a nivel de grupo y usuario. Con estas restricciones nos aseguramos de que determinados usuarios puedan acceder a determinadas partes del sistema con unos privilegios determinados. Por ejemplo, un usuario del grupo "Lexicógrafos" no puede modificar el diseño de consultas, formularios o informes comunes, pero sí está autorizado a crear nuevos formularios o informes personalizados.
Del mismo modo, la modificación de las tablas, consultas, formularios, informes y módulos sólo le está permitida a los usuarios del grupo "Administradores", es decir, los DBAs. El conjunto de restricciones de seguridad puede ser tan complejo como queramos. Por ejemplo, es posible permitir acceder a parte de los datos al grupo de usuarios "Invitados" o es posible establecer usuarios que pueden modificar los datos de un determinado idioma únicamente, aunque puedan consultar los datos del resto.
El uso normal de la base de datos se basa únicamente en el interfaz específico que hemos creado, mediante la cual es posible efectuar las tareas de modificación y consulta cotidianas. La Figura 5.13 muestra una captura de pantalla del panel de control principal.
Figura 5.13 Panel de control principal
Mediante este cuadro de diálogo se puede acceder a los cuadros que ofrecerán opciones más específicas para cada uno de los idiomas (ver Figura 5.14), así como a los datos compartidos (descripciones sintácticas, semánticas, de marcos, etc.) y a los distintos informes.
Los informes lexicográficos son generados automáticamente a partir de la información contenida en la base de datos. Los Apéndices I y II son en realidad dos de estos informes, adaptados al formato de este trabajo (numeración de páginas, encabezados, etc.). Como ya hemos mencionado, hemos incluido algunos informes prediseñados pero el lexicógrafo tiene privilegios para crear nuevos informes personalizados.
Tras elegir uno de los tres idiomas, el siguiente cuadro de diálogo muestra las opciones de la Figura 5.14.

Figura 5.14 Panel de control para una lengua
Algunas opciones no está aún disponibles para todos los idiomas. Las listas de nombres propios que contiene la base de datos están disponibles para ingles (unas 18.000 entradas) y alemán (unas 94.000 entradas)7 no está disponible para el español. La opción "Verb Inflection" está disponible para el inglés y el español y únicamente para los verbos de estos idiomas.
La Figura 5.15 muestra un formulario de consulta de tiempos verbales para el español.
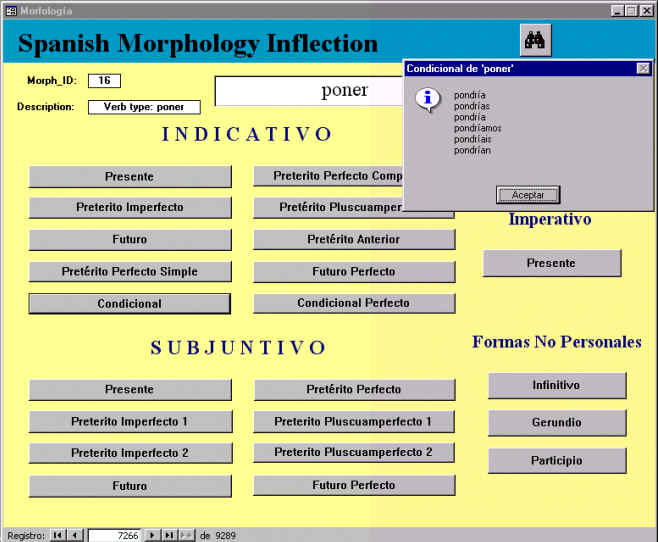
Fogura 5.15 Herramienta de flexión morfológica (español)
Por supuesto, las distintas formas de los tiempos verbales no están almacenadas físicamente en la base de datos, sino que se generan en tiempo de ejecución. La generación de estas formas se consigue mediante dos módulos de código que utilizan la información morfológica contenida en la base de datos. Como se puede observar, existen 9.289 predicados verbales para el español, aunque la mayoría sólo contienen aún la información flexiva que utiliza el módulo morfológico (un código arbitrario para cada uno de los 94 tipos de conjugación contempladas).
La morfología del verbo inglés es considerablemente más simple. La Figura 5.16 muestra una consulta de la inflexión del verbo "get".
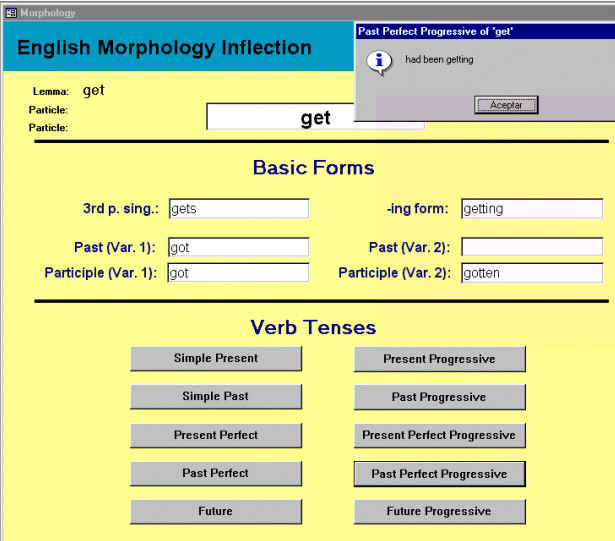
Figura 5.16 Herramienta de flexión morfológica (inglés)
Toda la información se muestra a través de formularios, de forma que las tablas que contienen la información real quedan fuera del alcance del usuario. La Figura 5.17 muestra el listado de nombres propios para inglés mediante un formulario. También en esta figura se puede comprobar la clave primaria de cada uno de las entradas de la tabla, por supuesto ésta no puede ser modificada por el usuario. Es una clave subrogada de tipo autonúmerico. En caso de que usuario quisiera añadir un nombre propio, pulsaría el botón al efecto y una clave sería asignada automáticamente a esta entrada. Este es el modo normal de trabajo con todos los demás formularios (descripciones fonéticas, morfológicas etc.).

Figura 5.17 Ejemplo de listado mediante formulario
Si volvemos a la Figura 5.14, el modo normal de consulta y edición es la primera de las opciones ofrecidas en este cuadro de diálogo. Tras pulsar este botón se muestra un pequeño formulario con el primer lema de la lista para un idioma determinado (ver Figura 5.18).
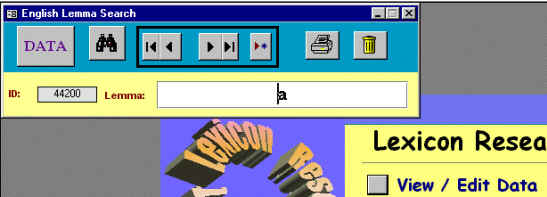
Figura 5.18 Formulario "Lema"
Para seleccionar el lema sobre el que queremos consultar/editar información nos podemos mover con los selectores de registro o buscarlo con la herramienta al efecto. Si el lema en cuestión no existe se puede añadir, aunque esta circunstancia es improbable, debido a las cifras que mostramos en la Figura 67. Tras tener el lema en pantalla pulsamos el botón "DATA" y se muestra la información correspondiente a la primera acepción de éste, tal y como muestra la captura de pantalla de la Figura 83.
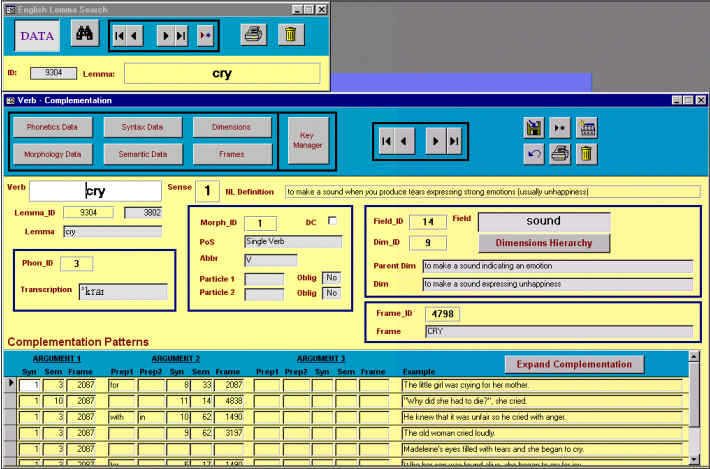
Figura 5.19 Formularios de consulta/edición
En este caso se ha seleccionado el lema "cry" y aparece la información para la primera acepción. El lexicógrafo es libre de cambiar el número de acepción, ya que, al contrario que en diseños anteriores (Moreno Ortiz 1995), este dato no forma parte de ninguna clave semántica. Mediante los selectores de registro se pueden seleccionar las distintas acepciones y añadir nuevas.
Como vemos, la parte superior del formulario corresponde a la
información general sobre el verbo, mientras que en la inferior se muestra la
complementación verbal. En un formulario en blanco (nuevo verbo o nueva acepción para un
determinado lema), lo primero que se introduce es el verbo, que puede contener más de una
palabra (p. ej. verbos con partícula), tras lo cual se introduce el código que lo
relaciona con su lema correspondiente (en el ejemplo, 9304). En el resto de la
información general sobre el verbo se introducirán los códigos que se correspondan con
la descripción morfológica (Morph_ID ), fonológica (Phon_ID),
de campo léxico (Field_ID) y de dimensión (Dim_ID). El usuario
puede consultar estos códigos en cualquier momento pulsando los botones que mostrarán
los formularios adecuados. Por ejemplo, si se pulsa el botón "Morphology Data"
aparecerá el formulario de la Figura 5.20.
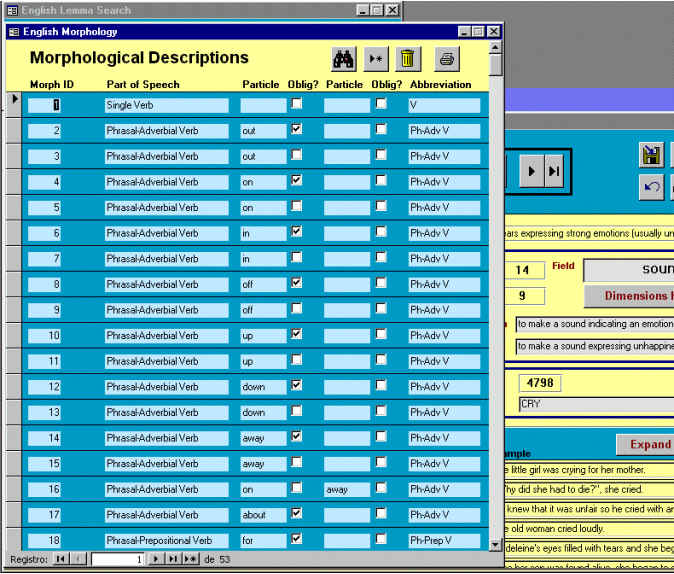
Figura 5.20 Ejemplo de consulta de datos
El proceso es el mismo en todos los casos, de no existir la descripción adecuada el usuario puede añadirla y a continuación insertar el código en la casilla correspondiente. Las descripciones no pueden ser editadas directamente sobre el formulario principal. Las casillas que aparecen en bajo relieve con fondo gris tan sólo muestran información, ya que no admiten el modo edición.
La sección Campo/Dimensión muestra el campo al que pertenece el lexema en cuestión ("sound" en este caso), así como la dimensión a la que pertenece y la dimensión inmediatamente superior en la jerarquía. El botón "Dimension Hierarchy" llama al conjunto de consultas anidadas que antes mencionábamos y muestra en pantalla un formulario con la jerarquía de dimensiones hasta llegar a "Top". La Figura 5.21 muestra el resultado en este caso.
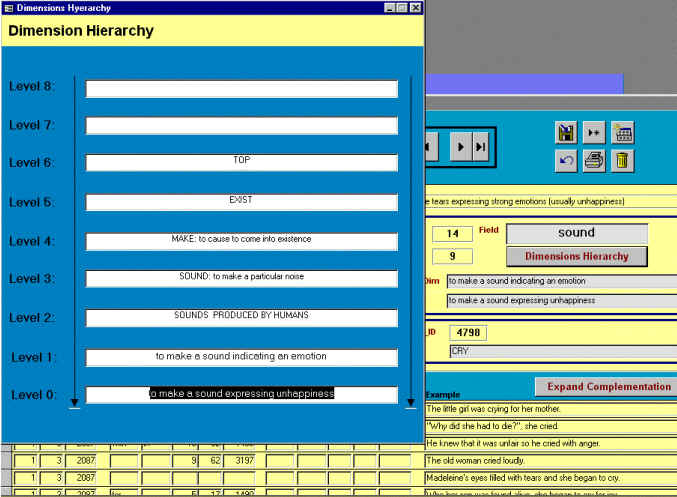
Figura 5.21 Consulta de dimensiones durante la edición
La asignación de los marcos de la ontología a los
lexemas de la base de datos plantea algunos problemas, derivados de la utilización de dos
esquemas de representación diferentes. Todos los marcos contenidos en la ontología se
encuentran en una tabla de la base de datos (ALL_Frame). A la hora de asignar
una marco a un lexema, se pueden consultar los existentes mediante el formulario al
efecto, que se muestra en la Figura 5.22. Sin embargo, la rica estructura interna
de los marcos no se refleja en la tabla, que se nos muestra en forma de lista alfabética.
En el apartado siguiente mostraremos cómo acceder a la taxonomía
de conceptos real, mediante otras herramientas independientes de la base de datos: LPA
Prolog y LPA FLEX.
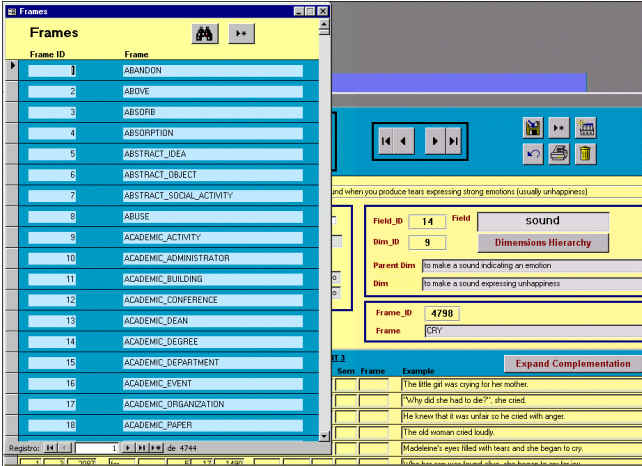
Figura 5.22 Consulta de marcos
La información respectiva a la complementación verbal, tal vez la más compleja en cuanto a modelado se refiere, ha sido incluida en el mismo formulario mediante un subformulario integrado. El modo de entrada de datos es el mismo que ya hemos explicado, basado en la introducción de códigos. En cualquier momento, el usuario puede consultar los códigos a través de otros formularios. Por ejemplo, el lexicógrafo puede consultar las distintas descripciones semánticas existentes mediante el botón "Semantic Data", que expandirá los códigos numéricos y mostrará un formulario como el de la Figura 5.23.
Este modo de proceder es más simple de lo que en principio puede parecer, ya que en realidad se trata de información altamente redundante y los códigos sintácticos y semánticos de los argumentos de los verbos para un determinado campo tienden a repetirse una y otra vez.
Esta característica no es un resultado observado a posteriori. Por el contrario, habiendo constatado este hecho previamente al modelado conceptual, decidimos implementarlo de este modo por la considerable reducción de la redundancia inherente a este tipo de información. Esta repetición de patrones a lo largo de las dimensiones en las que un campo léxico está estructurado es un hecho por otra parte constatado por relevantes estudios (Faber & Mairal Usón 1994a, b; Mairal Usón 1993, 1994a, b).
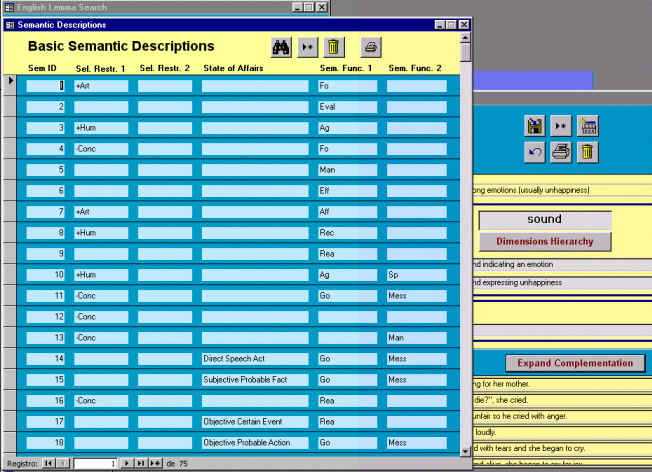
Figura 5.23 Consulta de descripciones semánticas de argumentos
La base de datos, estructurada de este modo, nos confirma con datos objetivos este tipo de afirmaciones: para un campo léxico (el de los verbos de sonido) que contiene un total de 890 patrones de complementación (para inglés y español), tan sólo hemos necesitado 50 descripciones semánticas distintas de argumentos. Éstas son las que el formulario de la Figura 5.23 nos muestra. Como siempre, en caso de no existir una descripción semántica adecuada, el lexicógrafo puede añadirla.
Mediante el botón de comando "Expand Complementation" el usuario puede consultar la información introducida de forma expandida, es decir, la información lexicográfica real para asegurarse de que los códigos introducidos son correctos, tal como se muestra en la Figura 5.24.
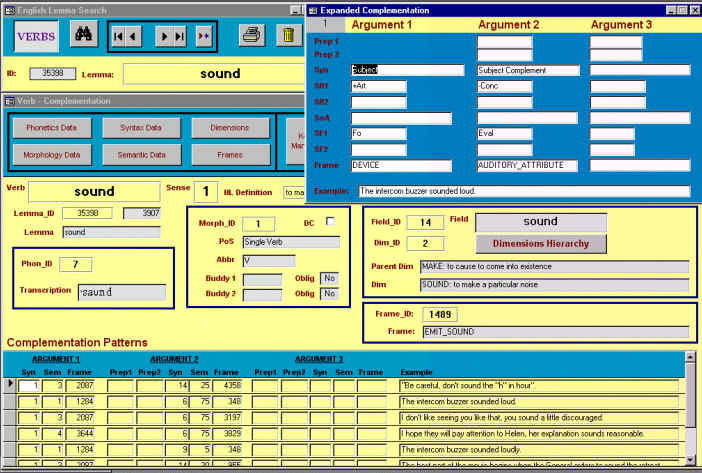
Figura 5.24 Expansión de información sobre complementación verbal
Como podemos comprobar, la información referente al marco, es decir, la conexión con la ontología de conceptos, también es asignada a los distintos argumentos de los predicados verbales. Tal y como apuntábamos durante la descripción del esquema conceptual de la base de datos, estos marcos son los mismos que utilizamos para la localización conceptual de los predicados verbales en sí. En el ejemplo que hemos escogido para mostrar el funcionamiento del interfaz de usuario, el marco de los argumentos no aporta mucha información, ya que los dos argumentos de "cry" son caracterizados conceptualmente como HUMAN, lo cual ya viene dado por las selecciones de restricción básicas. Sin embargo, lo normal es que este campo aporte información mucho más específica. En el siguiente apartado investigamos las implicaciones de este diseño.
NOTAS
Anterior I Siguiente I Índice capítulo 5 I Índice General