En este apartado mostraremos la implementación que bajo el modelo relacional de datos hemos llevado a cabo para nuestro lexicón multilingüe, mostrando los diagramas conceptuales y explicando las circunstancias que nos han llevado a adoptar determinadas decisiones. Pasaremos por alto la descripción detallada de la base de datos (tipos de datos, restricciones, código SQL de consultas, etc.). Lo realmente interesante de una base de datos y lo que determina en gran medida su funcionalidad es su esquema conceptual.
El modelado que vamos a mostrar aquí es el resultado de la experimentación con otros posibles esquemas que, por una razón un otra, fueron descartados en su momento. De todos los diseños probados, el que ahora presentamos es sin duda el más compacto y el que mejor se adapta al tipo de aplicación que le queremos dar, manteniendo al mismo tiempo una gran independencia de los datos y de la teoría gramatical. Respecto a esta característica, hemos de reconocer que la influencia del modelo para el que la base de datos se diseñó en principio, en 1992, bajo la dirección del profesor Martín Mingorance, es aún patente. Lo que hemos pretendido es aprovechar los grandes beneficios que de esta circunstancia se derivan al mismo tiempo que hemos construido sobre ello.
Un esquema alternativo considerado durante algún tiempo es descrito en (Moreno Ortiz 1995). Compararemos algunas de las características de este esquema con las del nuevo que proponemos en este trabajo.
Comenzaremos revisando algunas premisas importantes que han determinado en gran medida una implementación concreta. Como mencionamos en el Capítulo 1, nuestro análisis se ha centrado en las unidades verbales, bajo la suposición de que son éstas las que en buena medida determinan muchas características de una lengua, siendo consideradas en la mayoría de los análisis gramaticales el centro gravitacional de la oración.
Por lo que respecta a la FG, esto es así sin duda (Dik 1989), ya que el verbo es considerado como un predicado que toma una serie de argumentos (su valencia). También los sustantivos y adjetivos son considerados como predicados, pero el predicado verbal es el que determina la estructura general de la oración. En cualquier caso, esto no condiciona ningún diseño determinado para la expansión de la descripción de sustantivos o adjetivos, que también han sido incluidos en la base de datos, pero sin aportar por el momento una descripción léxico-semántica u ontológica de los mismos3.
En primer lugar, la base de datos ha de almacenar información léxica correspondiente a tres lenguas: inglés, español y alemán. Es de suponer que estas lenguas compartan algunas características básicas y difieran en otros muchos aspectos.
Nuestro objetivo es hallar todas las similitudes posibles en términos de necesidades de representación con el objeto de eliminar al máximo la redundancia y poder ofrecer un tratamiento lo más homogéneo posible. El modelo de representación no aspira a ser universal en ningún sentido, sino tan sólo a dar soporte a las necesidades representacionales de estos tres idiomas.
Por ejemplo, la morfología de los verbos de estas tres lenguas muestra grandes diferencias. En español no existe paralelo al verbo con partícula inglés, mientras que en alemán los verbos con partícula separable merecen un tratamiento especial. Por ello, cada lengua deberá contar con descripciones distintas para su morfología. Sin embargo, la descripción de los patrones sintácticos (en términos funcionales o de relaciones gramaticales) son las mismas para los tres (objeto directo, indirecto, etc.), por lo que esta información es susceptible de ser compartida en su mayor parte. Ésta es una diferencia clara con la mayoría de las bases de datos léxicas que hemos expuesto en apartados anteriores, ya que en éstas se suelen confeccionar los lexicones monolingües de forma aislada, de modo que es muy difícil recoger este tipo de generalizaciones que reducen considerablemente la redundancia de la base de datos y facilitan la tarea del administrador.
En este sentido hemos adoptado la convención de prefijar los nombres de las distintas relaciones ya sea con ALL (para aquéllas que contengan información compartida), ya sea con ENG, SPA o GER para las que contengan información específica del inglés, español o alemán, respectivamente.
Una ventaja importante sería mantener en lo posible la misma estructura general para las tres lenguas, porque esto facilitaría enormemente las tareas de mantenimiento y modificación de la base de datos. Esto no significa que las propiedades hayan de ser las mismas, pero sí las entidades y relaciones. Por ejemplo, las tres lenguas tienen verbos, sustantivos, adjetivos, adverbios y un conjunto cerrado de unidades léxicas, aunque las propiedades de cada una de ellas puedan ser diferentes.
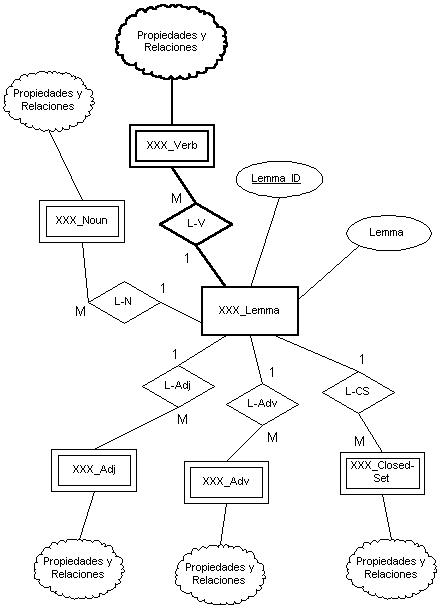
En nuestro diseño hemos tratado de aprovechar estas características isomórficas de modo que la estructura básica de entidades y relaciones es la misma para las tres lenguas. La Figura 5.3 muestra un diagrama E/R donde las "XXX" pueden ser sustituidas por las iniciales de cualquiera de las tres lenguas (ENG, SPA, GER).
Este diseño implica que en la base de datos existe una tabla
ENG_Lemma, una tabla SPA_LemmaGER_Lemma,
así como las tablas ENG_Verb, SPA_Verb, GER_Verb,
etc., manteniendo una estructura isomórfica.
Las "nubes" de este diagrama son otra convención que indican que el esquema no acaba ahí sino que continúan las relaciones y entidades. Hemos marcado con línea más gruesa la sección del diagrama que hemos desarrollado completamente, es decir, la información correspondiente a los predicados verbales, que describimos a continuación.
Figura 5.3 Esquema general de cada lengua
Como se puede observar, hemos adoptado el inglés como "lingua franca" para nombrar los elementos de nuestra base de datos. La única razón para esto es que esta lengua fue la primera para la que se introdujo información. Así las descripciones de entidades y sus propiedades compartidas estarán explicitadas en inglés. Como veremos, esto no condiciona absolutamente nada, ya que en realidad podríamos omitir las descripciones sin problema, pues todas ellas funcionan mediante códigos numéricos aleatorios. En lo sucesivo nos concentraremos en el modelado de las unidades léxicas verbales. El resto de las categorías contienen en este momento únicamente la identificación de lema y la cadena de caracteres que los representa. Por lo tanto, cualitativamente hablando, no existe mucha información respecto a estas categorías. Cuantitativamente, sin embargo, las listas son muy exhaustivas. La Tabla 5.1 muestra el número de entradas que las distintas tablas contienen actualmente junto con las fuentes de las que se ha extraído la información para cada una de las tres lenguas.
Idioma |
Nº de Lemas |
Fuentes |
INGLÉS |
62.418 |
|
ESPAÑOL |
77.569 |
Diccionario de la Real Academia de la Lengua (Ed. CD-ROM) |
ALEMÁN |
111.260 |
Corpus de referencia Arbeitsbereich Linguistik (Universidad de Münster)4 |
Tabla 5.1 Número de lemas contenidos en la base de datos
Por supuesto estas cifras no incluyen nombre propios, que han sido separados en espera de conseguir un tratamiento adecuado en cuanto a modelado en un entorno multilingüe. Trasladamos la discusión sobre el correcto tratamiento de los nombre propios al apartado 5.4.
La utilización de las fuentes que señalamos en el cuadro se debe únicamente a que son las que hemos tenido a nuestro alcance. En especial, la elección del DRAE como fuente para la lista de lemas españoles dista mucho de nuestras preferencias en cuanto a metodología lexicográfica. Idealmente, habríamos optado por una populación basada en fuentes textuales reales, es decir, córpora, tal y como ocurre con la lista de palabras para el alemán. En este sentido, el más reducido número de lemas para el inglés (que incluye unos 18.000 nombres propios) se justifica porque las fuentes empleadas realizan una selección de las entradas mucho más adecuada que la del DRAE. El alto número de lemas para el alemán también se debe a esta razón, al estar extraídos a partir de un gran número de textos periodísticos.
El término "lema" merece una aclaración. Este término se ha venido utilizando en diversos campos para designar nociones no siempre idénticas. Lo que entendemos por "lema" viene a coincidir en términos lexicográficos, con el concepto de "entrada" en un diccionario tradicional. El término "entrada" (entry), sin embargo, tampoco es clarificador, ya que mientras que en algunos casos ésta se entiende como la "forma canónica" mediante la cual las distintas unidades léxicas son identificadas (por ejemplo, la forma de infinitivo de un verbo) y en otras ocasiones también incluye cualquier otra palabra o frase explícita o implícitamente definida en el diccionario (cf. Landau 1984). La noción de "forma canónica" es tal vez la más acercada a lo que nosotros entendemos por el término "lema".
La adopción de este término se debe sin duda a la influencia de las técnicas de lexicografía computacional y lingüística de corpus, donde un "lematizador" es un programa que refiere un "token" determinado (cadena de caracteres), por ejemplo, "acabaría", a una forma canónica determinada, "acabar", que es denominada lema.
Al centrar la descripción de los distintos lexemas en torno a un lema determinado nos aseguramos de que todos los lexemas que han de ser definidos bajo una entrada determinada del diccionario queden correctamente enlazados. Más adelante mostraremos el mecanismo relacional concreto que permite esto.
En términos de procesamiento automático del lenguaje, el lema es el objeto léxico abstracto al que una cadena de caracteres determinada ha de ser asignada para recuperar la información (sintáctica, semántica, etc.) necesaria para un tratamiento correcto. De este modo nuestra disposición es válida para los dos tipos de tareas a las que la base de datos pretende dar soporte.
Además, el lema está relacionado con los distintos lexemas (p. ej. verbos) con exigencia de integridad relacional, con actualización y eliminación en cascada. Esta cualidad, impide, por ejemplo, que un verbo se asigne a un lema inexistente o fuerza la eliminación de todos los lexemas asignados a un determinado lema si éste es eliminado.
Puesto que las tres lenguas mantienen la misma estructura básica, un solo diagrama nos servirá para mostrar la forma en que hemos modelado la información respectiva a los predicados verbales en la base de datos. La Figura 5.4 muestra el diseño.
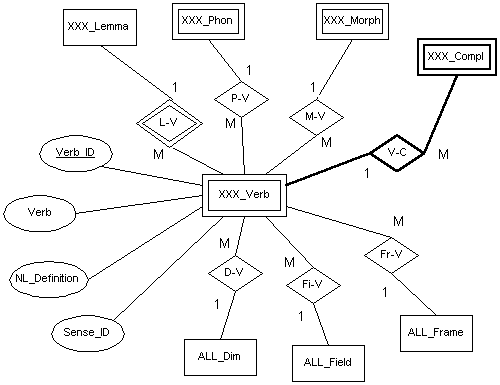
Figura 5.4 Modelado básico de predicados verbales
Como se puede observar existe muy poca información asignada
directamente al verbo, tan sólo la definición en lenguaje natural, el indicador de
acepción y el verbo, propiamente. En la mayoría de los casos el verbo se corresponderá
con el lema, pero no siempre. Por ejemplo, los verbos "take on", "take
over", "take up" etc. mostrarán esta forma en el campo Verb,
mientras que todas ellas estarán referidas al mismo lema, "take".
El tratamiento que hemos dado a la morfología del
inglés puede servirnos para mostrar de una forma sencilla la manera en que un buen
diseño relacional puede suplir la deficiencia de la herencia de dicho modelo. La Figura
5.5 muestra las propiedades concretas de la relación ENG_Morph.
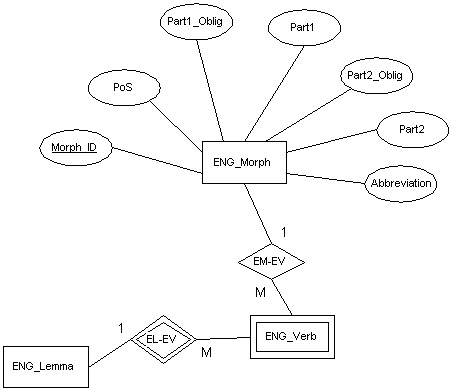
Figura 5.5 Modelado de información morfológica para el inglés
Este diagrama muestra, en primer lugar, que una definición
morfológica cualquiera puede ser asignada a un número indeterminado de verbos. Las
propiedades mediante las que se describe un patrón morfológico han sido escogidas para
eliminar la redundancia en lo posible. Existe un código arbitrario (Morph_ID)
que es la clave primaria de la tabla ENG_Morph que, mediante una clave
externa en la tabla ENG_Verb, servirá para establecer la relación. La
propiedad PoS describe de forma sucinta el tipo de entidad morfológica (por
ejemplo, "phrasal-prepositional verb"), mientras que el campo Abbreviation
nos servirá para el volcado lexicográfico en diccionario impreso. Los cuatro campos
restantes son utilizados para todas aquellas construcciones verbales multi-palabra que
incorporen uno o dos elementos más además del lema. Además de la multitud de verbos con
partícula ingleses, esta disposición da cabida a otros muchos lexemas verbales
muti-palabra del tipo "take care of", "take place", "look
like", "be born", "tear apart" y tantos otros. Finalmente, las
dos propiedades –Oblig son campos booleanos que marcan la obligatoriedad
o no de la partícula a la que se refieren, información necesaria tanto para el
diccionario impreso como para el procesamiento automático.
La representación final consistirá en el lema, al que se le
asignarán las características morfológicas propias según su realización como lexema,
la construcción global, determinada por el campo Verb en la tabla ENG_Verb,
más la descripción de las posibles partículas acompañantes y la definición concreta
del tipo de objeto morfológico en la tabla ENG_Morph.
Como ya hemos mencionado, las necesidades de cada idioma respecto a la morfología son distintas. La Figura 5.6 muestra la representación necesaria para las características morfológicas del alemán.
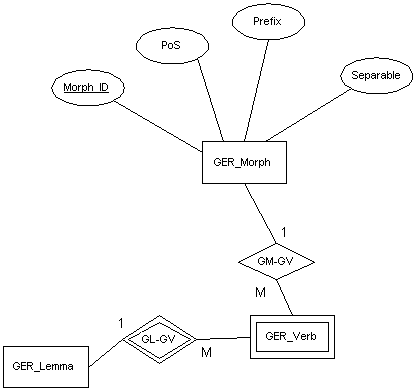
Figura 5.6 Modelado de información morfológica para el alemán
Además de esta representación morfológica, el sistema también contiene dos módulos morfológicos, uno para el español y otro para el inglés, totalmente integrados en la base de datos que, tomando la información contenida en ésta, son capaces de generar todas las formas verbales para cualquier verbo de estos idiomas. Mostramos algunas de sus características en el apartado 5.4.
Este enfoque "personalizado" a la morfología (es decir, la consideración de distintos esquemas para distintas lenguas) se diferencia de las especificaciones de MLEXd, que considera un único marco descriptivo para todas lenguas de la Comunidad Europea. Obviamente, esto implica redundancia, ya que muchos descriptores son sólo aplicables a lenguas concretas.
Por lo que respecta a la información fonológica, la base de datos es capaz de almacenar información relativa a la transcripción fonética de los distintos lexemas siguiendo el alfabeto fonético internacional. La fonética nos ha planteado algunas dudas de implementación. En inglés está claro que es necesario asignar este tipo de información a nivel de lexema, no de lema, ya que, por ejemplo existen un buen número de alternancias verbo/sustantivo con cambio de acento. Sin embargo, en español esto no ocurre así, sino que el grafema determina totalmente la pronunciación independientemente de su realización como lexema. Hemos querido mantener el mismo esquema para los dos idiomas por razones que se harán aparentes más adelante y que tienen que ver con la facilidad que esto supone para la creación de consultas, formularios e informes. Otra ventaja de este diseño es poder aprovechar las características homofónicas de muchos lexemas (p. ej. /ro:/ para "roar" y "raw"). La Figura 5.7 muestra el diseño de las propiedades morfológicas para una lengua cualquiera.
Este esquema es prácticamente el mismo que el utilizado en MLEXd con los cambios necesarios para la adaptación a nuestro esquema general. El descriptor "Transcription" es la transcripción fonética considerada como standard, mediante el juego de caracteres IPA. "Syllabification" contiene lo mismo que el anterior, pero con marcas separadoras de sílabas. Finalmente, "Accent" contiene información sobre la sílaba que lleva la carga prosódica principal. Esta información es utilizada, por ejemplo, por el módulo morfológico inglés para determinar si un verbo ha de doblar la consonante final de la forma base para generar las formas "-ing" y "-ed".
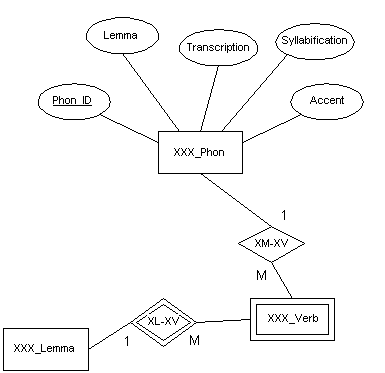
Figura 5.7 Modelado de información fonológica para un alengua
Con esto hemos mostrado todas aquellas entidades que en la Figura 5.4 señalábamos como dependientes de la lengua, excepto la sección que en esta figura marcábamos con línea más gruesa, la complementación verbal, que, por su complejidad, será descrita al final.
Por lo que respecta al resto de los grupos de descripción
compartidos (ALL_Dim, ALL_Field y ALL_Frame), la Figura
5.8 muestra cómo se modela esta situación. Este modelado es característico de
nuestra implementación y refleja los supuestos metodológicos que hemos adoptado en este
trabajo. No debemos dejar de tener en cuenta que todos estos diagramas son parciales. Por
ejemplo, en esta figura no se han incluido las respectivas entidades "Lema" o
las que definen las propiedades fonológicas o morfológicas que acabamos de describir. En
este sentido, las entidades ENG_Verb, SPA_Verb y GER_Verb
siguen siendo dependientes (por lo que se marcan con un rectángulo doble) aunque en esta
representación parcial no aparezcan las entidades de las que dependen (XXX_Lema).
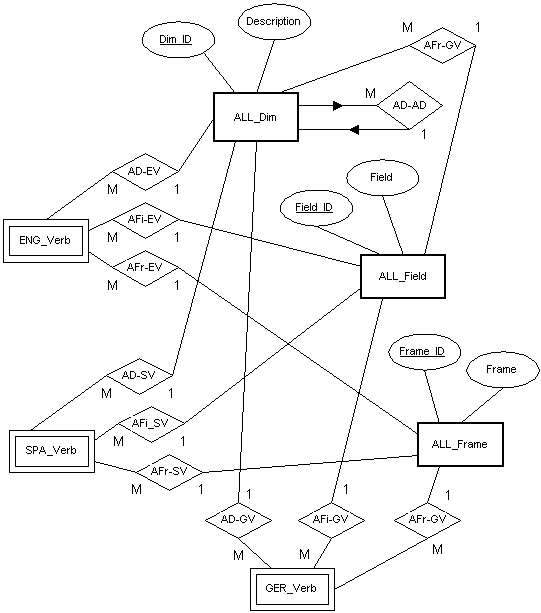
Figura 5.8 Modelado de las entidades compartidas
Aunque el diagrama muestre una situación en apariencia
compleja, de hecho no hemos representado en él todas las relaciones que las entidades ALL-
guardan en el esquema general de la base de datos. Cuando describamos el modelado que
hemos realizado de la complementación verbal, veremos cómo estas mismas entidades, junto
con otras, son utilizadas para la descripción de los argumentos que toman los predicados
verbales, por lo que en realidad la situación es algo más complicada de lo que aquí se
muestra.
La entidad ALL_Dim contiene información sobre
las dimensiones que sirven de "esqueleto" al eje paradigmático, según se
especifica en el FLM. Las distintas dimensiones son almacenadas con un código arbitrario
(Dim_ID), la descripción de la dimensión (Description) y dos propiedades
adicionales que son las que en realidad aportan información relevante, ya que las
localiza en una jerarquía. La relación AD-AD señala una relación especial
que ya hemos comentado: la de tipo/subtipo, o en términos relacionales una autocombinación
(self-joint). Éste es el único modo que una base de datos relacional ofrece para
recrear jerarquías, aunque en ningún caso debemos entender éstas en términos de redes
semánticas como las que mostraremos en el apartado 5.4 para la
implementación de la ontología. El mecanismo es muy fácil: a una entidad se le asigna
una propiedad, por ejemplo Subtype_of, que hace referencia al identificador
único (en este caso, Dim_ID) de la entidad que es considerada como
"madre". La "herencia" de propiedades se consigue mediante consultas
anidadas que generan conjuntos dinámicos de datos (ver apartado
4.2.3.1), con una profundidad de niveles indeterminada (o en todo caso determinada por
los niveles de anidación de las consultas). Finalmente, la relación con la entidad ALL_Field
enmarca la dimensión en un campo léxico determinado.
De este modo, la base de datos es capaz de mostrar, para un lexema verbal cualquiera, no sólo la dimensión a la que pertenece, sino también todas las dimensiones "madre" hasta llegar a la última. Con la información que ha sido introducida hasta ahora en la base de datos no se ha necesitado una profundidad superior a nueve, con lo que éste es el número de consultas anidadas que han de realizarse para recuperar esta información. En el siguiente apartado mostraremos una captura de pantalla que de forma gráfica muestra este tipo de jerarquía.
La información referente a las dimensiones verbales es obviamente algo específico de un modelo lexicológico determinado, el FLM, para el que la base de datos se diseñó en primer lugar. Creemos que nuestras pretensiones respecto a la validez de la base de datos para otros modelos, la característica mencionada de independencia de la teoría, queda salvaguardada con el modelado de datos que proponemos, ya que esta información no condiciona la estructura general de la base de datos.
La estructuración de un campo en dimensiones y subdimensiones ofrece una forma adecuada y de probada fiabilidad para estructurar el eje paradigmático de una lengua. Por lo que se refiere a la utilidad de esta información en el procesamiento del lenguaje natural, y más concretamente en la Traducción Automática, pensamos que no es, en sí misma, suficiente. La razón básica es que estamos hablando de un método de análisis lexicológico, no de un método de descripción formal, que además no fue originalmente ideado para este tipo de tareas, no contando con una formalización adecuada y por tanto de dudosa aplicación a las mismas. Nuestra aportación en este sentido ha sido proponer una jerarquía de conceptos (la ontología) que sí puede ser utilizada como un soporte formal más fiable, como de hecho se lleva a cabo en los proyectos de KBMT que hemos mencionado. Continuaremos esta discusión en el apartado 5.4.
La conexión entre la base de datos y la base de conocimiento
la hallamos ya aquí. Como se muestra en la Figura 5.8, cada uno de los predicados
verbales de las tres lenguas mantienen una relación con la entidad ALL_Frame.
Esta tabla contiene todos los marcos (conceptos) contenidos en la ontología (unos 4.800
hasta el momento), cuya organización jerárquica en red semántica localiza de forma muy
concreta el contenido léxico-semántico de los lexemas verbales. En realidad, como
veremos a continuación, los distintos argumentos de los predicados verbales también son
localizados de forma precisa mediante su adscripción a un marco determinado.
Mediante estos tres grupos de descripción: dimensión, campo y marco, más la descripción del patrón de complementación sintáctico-semántico que mostramos a continuación dotamos a las entradas léxicas de una descripción semántica suficiente para individualizarlas, de forma que se obtiene una caracterización lo suficientemente precisa como para ofrecer un perfil semántico que nos permitirá establecer correspondencias interlingües sin que éstas se hallen señaladas de forma explícita. La dimensión determina las propiedades de sinonimia básicas, ya que lexemas contenidos en una dimensión determinada mantienen un índice sinonímico alto. La adscripción a un marco determinado de la ontología aporta su localización y caracterización formal, dentro de un submundo perfectamente estructurado y sobre el que se pueden efectuar operaciones concretas.
Finalmente llegamos a la descripción del patrón de complementación sintáctico-semántico. Éste habrá de incorporar información sobre la valencia cuantitativa y cualitativa de los predicados verbales. No cabe duda de que se trata de un conjunto de información complejo y muy susceptible de contener altos índices de redundancia. Volvemos a tratar el problema de la subcategorización, para el que la mayoría de los formalismos gramaticales modernos ofrecen como solución basada en herencia múltiple por defecto no monotónica (ver apartado 4.4).
Como ya mencionamos en las conclusiones del capítulo anterior, es posible que ésta sea la mejor solución, pero desde luego no la única. En el resto de este apartado pretendemos demostrar cómo se puede modelar este tipo de información utilizando métodos clásicos de representación, ofreciendo unos niveles de redundancia aceptables. En contrapartida, nos estaremos beneficiando de un modelo de datos de probada efectividad y fiabilidad.
Si volvemos a observar la Figura 5.4, el área del esquema general que pretendemos desarrollar ahora es el que señalábamos con una línea más gruesa. Obviamente, lo mostrado en esta figura es una gran simplificación del esquema real. La Figura 5.9 expande este esquema.
En este diagrama hemos omitido de nuevo todas aquellas
propiedades y relaciones que no tienen que ver con la complementación verbal. Como vemos
existe una caracterización para cada uno de los tres argumentos que se contemplan para el
predicado verbal. Cada argumento queda definido según un número de propiedades
sintácticas y semánticas, así como la o las preposiciones que pueden precederles (esto
último no se aplica al argumento 1; dichas propiedades son las siguientes:
ArgX:
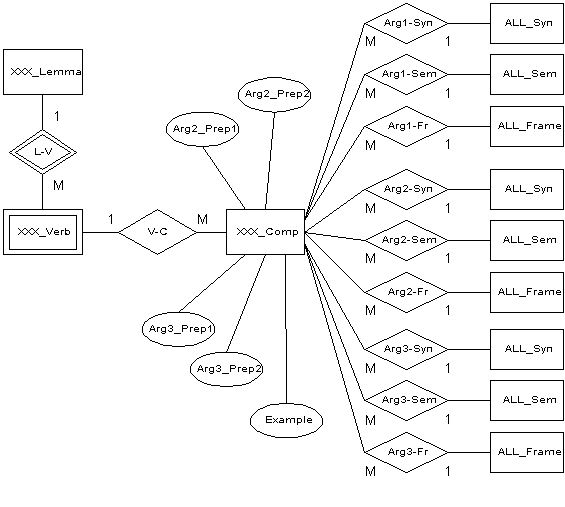
Figura 5.9 Modelado de la complementación
verbal
La Tabla 5.2 contiene todas las descripciones sintácticas consideradas por la base de datos en estos momentos, aunque es posible añadir nuevas.
Syn_ID |
Entry |
Abbrevation |
Subtype of |
1 |
Subject | S | |
2 |
Object | O | |
3 |
Complement | C | |
4 |
Adverbial | A | |
5 |
Adjunct | Ad | |
6 |
Subject Complement | Cs | 3 |
7 |
Object Complement | Co | 3 |
8 |
Prepositional Object | PO | 2 |
9 |
Adverbial of Manner | AM | 4 |
10 |
Adjunct of Manner | AdM | 5 |
11 |
Direct Object-Direct Quote | Od-DQ | 14 |
12 |
Direct Object-That Clause | Od-TC | 14 |
13 |
Direct Object-To Infinitive | Od-TI | 14 |
14 |
Direct Object | Od | 2 |
15 |
Indirect Object | Oi | 2 |
16 |
Adverbial of Place | AP | 4 |
17 |
Adjunct of Place | AdP | 5 |
Tabla 5.2
- ALL_Sem
- Selection Restrictions (2): +Hum, -Anim, +Percep, -Conc, etc
- State of Affairs: Direct Speech Act, Subjective Probable Fact, etc.
- Semantic Functions (2): Agent, Speaker, Goal, Beneficiary, etc.
- ALL_Frame
- Frame (conexión con la ontología)
La Tabla 5.3 contiene todas las combinaciones que hasta el
momento han sido necesarias incluir para describir los argumentos de los predicados
verbales contenidos en la base de datos.
Sem_ID |
SR1 |
SR2 |
SoA |
SF1 |
SF2 |
1 |
+Art | Fo | |||
2 |
Eval | ||||
3 |
+Hum | Ag | |||
4 |
-Conc | Fo | |||
5 |
Man | ||||
6 |
Eff | ||||
7 |
+Art | Aff | |||
8 |
+Hum | Rec | |||
9 |
Rea | ||||
10 |
+Hum | Ag | Sp | ||
11 |
-Conc | Go | Mess | ||
12 |
-Conc | ||||
13 |
-Conc | Man | |||
14 |
Direct Speech Act | Go | Mess | ||
15 |
Subjective Probable Fact | Go | Mess | ||
16 |
-Conc | Rea | |||
17 |
Objective Certain Event | Rea | |||
18 |
Objective Probable Action | Go | Mess | ||
19 |
-Hum | Ag | |||
20 |
-Anim | +Shap | Fo | ||
21 |
+Conc | Direction | |||
22 |
+Nfo | Fo | |||
23 |
-Conc | Go | Area | ||
24 |
+Animal | Ag | |||
25 |
+Percep | Eff | |||
26 |
+Percep | Mess | Eff | ||
27 |
+Hum | Exp | |||
28 |
+Conc | -Anim | Aff | ||
29 |
+/-Hum | Rec | |||
30 |
+Percep | Go | Mess | ||
31 |
+Conc | +/-Art | Processed | ||
32 |
-Conc | Eff | |||
33 |
+Hum | Rea | |||
34 |
Objective Probable Fact | Rea | |||
35 |
+Hum | Aff | |||
36 |
Subjective Probable Fact | Rea | |||
37 |
-Anim | Aff | |||
38 |
+Animal | Rec | |||
39 |
Cause | ||||
40 |
+Conc | Fo | |||
41 |
Objective Probable Event | ||||
42 |
+Conc | Aff | |||
43 |
+Conc | Cause | |||
44 |
+/-Conc | Rea | |||
45 |
+Conc | -Anim | Fo | ||
46 |
+Conc | -Anim | Eff | ||
47 |
+/-Hum | Aff | |||
48 |
Phen | ||||
49 |
-Conc | Objective Probable Fact | |||
50 |
+/-Living | Go | |||
51 |
-Conc | Go | Eff | ||
52 |
|||||
53 |
+Conc | Go | Eff | ||
54 |
+Hum | Sp | |||
55 |
-Conc | Mess | |||
56 |
+/-Conc | Area | |||
57 |
-Conc | Area | |||
58 |
+Conc | Loc | |||
59 |
-Conc | Rec | |||
60 |
Exp | ||||
61 |
+Loc | Fo | |||
62 |
+Percep | Man | |||
63 |
+Hum | ||||
64 |
+Conc | ||||
65 |
-Conc | Aff | |||
66 |
Direct Speech Act | Go | |||
67 |
+Conc | Source | |||
68 |
+Conc | +Loc | Aff | ||
69 |
+Anim | Ag | |||
70 |
+Conc | Means | |||
71 |
Mess | ||||
72 |
+Living | ||||
73 |
+Living | Ads | |||
74 |
+Concrete | Instrum. | |||
75 |
-Conc | Eval |
Tabla 5.3
La Figura 5.10 muestra el esquema conceptual de estas tres entidades.
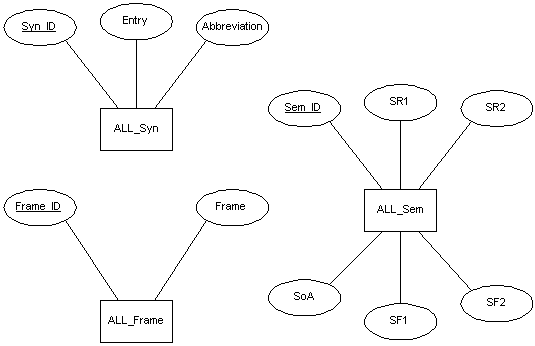
Figura 5.10 Detalle de entidades (complementación verbal)
De nuevo observamos cómo cierta información está enfocada
a determinados tipos de tareas. El campo Ejemplo es de nula utilidad para el
análisis automático, estando enfocado a la lexicografía. Lo mismo ocurre con el campo Abbreviation,
que únicamente será de utilidad en diccionarios impresos.
La información referente a la sintaxis y a la semántica, sin embargo es susceptible de ser utilizada en ambos tipos de aplicaciones. Sería posible, por ejemplo, establecer una serie de reglas que convirtiesen los descriptores en cadenas de caracteres más apropiados para la consulta por un usuario, mientras que esos mismos códigos pueden ser utilizados directamente por una aplicación externa (recordemos que la recuperación de los datos está garantizada, puesto que cumple con el estándar ODBC).
Como ya adelantábamos cuando mostrábamos el modelado de la
información básica de las unidades léxicas, la misma tabla ALL_Frame,
utilizada para describir ontológicamente las unidades verbales de los tres idiomas
(siendo de hecho lo más cercano a un enlace multilingüe que contiene la base de datos),
es utilizada de nuevo para describir los distintos argumentos de los predicados verbales
(por supuesto para las tres lenguas, no olvidemos que el modelado es idéntico).
Los campos de estas tablas que muestran el sufijo _ID
nos recuerdan que seguimos trabajando con claves subrogadas. De hecho, este es el único
tipo de claves primarias que hemos usado en la implementación. Como muestra la Figura 5.9, la caracterización semántica de un argumento
determinado se muestra únicamente mediante un código, que es el que establece la
relación con la tabla ALL_Sem. Esto quiere decir que el lexicógrafo no se
ve forzado a repetir una y otra vez las mismas cadenas de caracteres (+Human, Agent,
Speaker, etc.). Puesto que sólo se almacenan números enteros, el sistema gana
enormemente en velocidad, a la vez que se evitan errores tipográficos, ya que, por
ejemplo, una descripción semántica determinada (+Hum, Agent, Speaker) sólo se teclea
una vez, utilizando el código asignado a la descripción desde ese momento.
La entrada de códigos arbitrarios es, de hecho, lo que ocurre con el resto de la información referente a la complementación, así como con la mayor parte del resto de la información léxica. Se puede pensar que la utilización de códigos puede entorpecer la labor lexicográfica en lugar de facilitarla. Sin embargo, un interfaz gráfico adecuadamente diseñado evitará esta situación. En el siguiente apartado describimos este interfaz. Al mismo tiempo, las reglas de integridad relacional se encargan de bloquear muchos de los errores normales en la tarea de introducción de datos. Por ejemplo, estas reglas impiden que se asigne un código inexistente o que se deje en blanco ciertos datos que necesariamente han de ser especificados. Además, la introducción de un código erróneo es fácilmente detectable, puesto que el resultado, una vez expandida la descripción, será totalmente diferente de lo deseado.
En la versión anterior a este modelado (Moreno Ortiz 1995) se contemplaba un esquema conceptual
distinto para la descripción sintáctico-semántica. En lugar de considerarse un entidad
separada para la complementación (XXX_Comp, ver Figura
5.9), se utilizaba una clave ajena dentro de la entidad XXX_Verb para
describir cada uno de los argumentos en entidades separadas en una relación uno-a-uno.
Estas entidades, denominadas Arg1, Arg2, Arg3, estaban a su vez relacionadas
con otra entidad, Arg_Desc, equivalente a la actual ALL_Sem y
con otra, P_Axis, que describía sus propiedades paradigmáticas. Las Figuras
5.11 y 5.12 muestran este modelado.
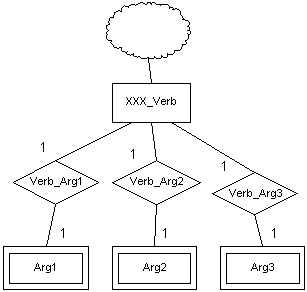
Figura 5.11 Modelado sintáctico-semántico descartado (1)
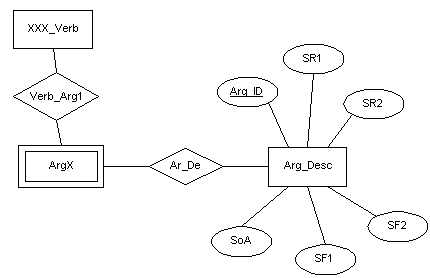
Figura 5.12 Modelado sintáctico-semántico descartado (2)
Este modelado implica que deberán existir tantas entidades ArgX
(x3) como lenguas se consideren en la base de datos. De hecho, es un buen ejemplo de error
conceptual, ya que fue diseñado para almacenar información de una sola lengua, y no se
tuvieron en cuenta las repercusiones que la inclusión de otras tendría sobre el esquema
global de la base de datos. Por tanto el esquema fue descartado en vista de los grandes
niveles de redundancia que se generaban y sobre todo porque resultaba innecesariamente
complejo, entorpeciendo las labores de consulta y actualización.
Finalmente hemos de mencionar que aún no hemos acometido la tarea de modelar la información pragmática que una base de datos de estas características debería contener5. La razón fundamental es que el modelo de representación sintáctico-semántica que proponemos aún ha de ser perfeccionado. El desarrollo del componente pragmático, es indispensable para un sistema de TA basado en el conocimiento como el que proponemos, ya que en tales sistemas se pretende conseguir una representación neutral de los actos de habla (interlingua); esta representación neutral deberá incluir forzosamente una serie de rasgos pragmáticos muy específicos que definan las características diafásicas, diastráticas y diatópicas de lexemas y proposiciones, de tal modo que estos rasgos puedan ser recreados de forma fidedigna en el texto meta.
El modelado de este tipo complejo de información es por tanto una tarea que posponemos para futuros desarrollos de nuestro esquema, dada su enorme complejidad y envergadura. El punto de partida para este desarrollo será sin duda una formalización del trabajo de Jiménez Hurtado (1994a, 1994b), donde se sientan las bases para un tratamiento sistemático de la información pragmática desde una perspectiva del modelo lexemático-funcional.
En cualquier caso, y dando por supuesta la futura existencia de una descripción de los rasgos pragmáticos, pensamos que la caracterización semántica que acabamos de proponer no es en sí misma una caracterización lo suficientemente precisa para servir de soporte a un sistema de traducción automática, que deberá ser capaz de generar descripciones interlingües muy precisas y, sobre todo, independientes de la lengua. Por este motivo proponemos en este trabajo la inclusión de un recurso de información conceptual independiente de la lengua, siguiendo el ejemplo de proyectos de KBMT bien establecidos. Por tanto, la descripción sintáctico-semántica que acabamos de presentar será complementada con la inclusión de una ontología, representada mediante un sistema de redes semánticas, que describiremos en el apartado 5.4. Por lo que respecta a la base de datos léxica, hasta ahora nos hemos centrado en la descripción formal, en términos de modelado conceptual de la base de datos. En el siguiente apartado mostramos el interfaz de usuario, que probablemente ayudará a comprender el funcionamiento y las posibilidades del modelo abstracto que acabamos de presentar.
NOTAS
Anterior I Siguiente I Índice capítulo 5 I Índice General