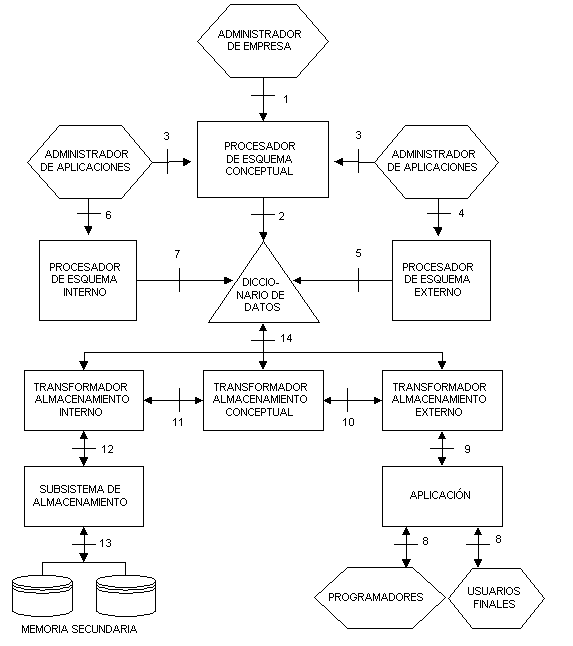
Figura 4.3 Arquitectura funcional ANSI/X3/SPARC
La definición de un sistema de información es la descripción detallada de la arquitectura del sistema. Las arquitecturas de bases de datos han evolucionado mucho desde sus comienzos, aunque la considerada estándar hoy en día es la descrita por el comité ANSI/X3/SPARC (Standard Planning and Requirements Committee of the American National Standards Institute on Computers and Information Processing), que data de finales de los años setenta. Este comité propuso una arquitectura general para DBMSs basada en tres niveles o esquemas: el nivel físico, o de máquina, el nivel externo, o de usuario, y el nivel conceptual. Así mismo describió las interacciones entre estos tres niveles y todos los elementos que conforman cada uno de ellos.
La arquitectura que vamos a describir brevemente corresponde a un sistema centralizado; no consideramos relevante en el marco de este trabajo la descripción de los sistemas distribuidos. Esta arquitectura tiene dos partes fundamentales: la de descripción de datos y la de manipulación de datos, organizadas en torno al diccionario de datos. A su vez, cada una de estas dos partes se organiza en torno a tres niveles: externo, conceptual e interno. En la Figura 4.3 un hexágono representa el papel del DBA y un rectángulo representa un procesador. En realidad, la figura del DBA agrupa los papeles de administrador de sistema, administrador de empresa y administrador de aplicaciones en lo que se refiere a la base de datos. El papel del administrador de empresa es definir el esquema conceptual usando el interfaz 1. El procesador de esquema conceptual compila este esquema y si es correcto se almacena en el diccionario de datos, que contiene todos los esquemas y reglas de proyección. Los administradores de aplicaciones se encargan de definir los esquemas externos, usando lenguajes específicos de descripción de esquemas externos (interfaz 2), según las necesidades de los usuarios y las posibilidades del sistema. Para especificar las reglas de proyección entre un esquema externo y el esquema conceptual, el administrador de aplicaciones puede consultar el esquema conceptual mediante el interfaz 3. Cuando se define correctamente un esquema externo con sus reglas de proyección asociadas, es compilado por el procesador de esquema externo y almacenado en el diccionario de datos. Por último el administrador del sistema, mediante un lenguaje de descripción interno (interfaz 6) completa la descripción de la base de datos definiendo su esquema interno y las reglas que lo proyectan sobre el esquema conceptual. Estos diferentes lenguajes se agrupan en los dos tipos generales que antes mencionamos: lenguajes de descripción de datos (DDL) y lenguajes de manipulación de datos (DML).
Figura 4.3 Arquitectura funcional ANSI/X3/SPARC
El nivel clave en esta arquitectura, como se puede adivinar, es el conceptual. Éste contiene la descripción de las entidades, relaciones y propiedades de interés para la empresa (UoD), y constituye una plataforma estable desde la que proyectar los distintos esquemas externos, que describen los datos según los programadores, sobre el esquema interno, que describe los datos según el sistema físico. Las posibles proyecciones de datos quedan resumidas en la Figura 4.4.
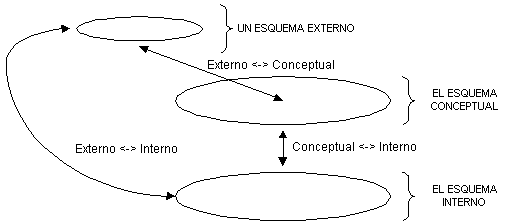
Figura 4.4 Posibles proyecciones de datos
Como cabría esperar, en la práctica cotidiana de implementación de bases de datos, esta arquitectura no es seguida al cien por cien por los DBMSs comerciales. Existen muy pocos productos que contengan aplicaciones para facilitar la fase de análisis. Por lo general, el nivel conceptual se obvia en los productos comerciales, salvo honrosas excepciones. Lo habitual es que el DBA realice el modelado conceptual usando sus propios recursos, o tal vez asistido por alguna aplicación de análisis, ya sea general o específica. El procesador del esquema conceptual, es por tanto el propio DBA. Los DBMSs sí suelen ofrecer facilidades para la creación de esquemas externos, pero sin pasar por el nivel conceptual. Por supuesto, un DBMS comercial no está obligado a seguir las recomendaciones de estandarización de arquitecturas del comité ANSI/X3/SPARC. Por lo que respecta al modelo relacional de bases de datos11, que ya existía antes del informe de este comité, los fabricantes de RDBMSs se ajustan en mayor o menor medida al modelo teórico y, en cuanto a la arquitectura, han intentado seguir las recomendaciones del grupo RDBTG (Relational Data Base Task Group), parte del comité ANSI/X3/SPARC.
El resultado de este grupo fue restar importancia a las arquitecturas y realzar la de los lenguajes e interfaces. Como consecuencia, el lenguaje SQL, está hoy en día totalmente estandarizado, y en cambio encontramos distintas arquitecturas de RDBMS. Sin embargo se pueden distinguir dos tipos generales de arquitecturas para estos sistemas de bases de datos, que mostramos gráficamente respectivamente en la Figura 4.5 y Figura 4.6.
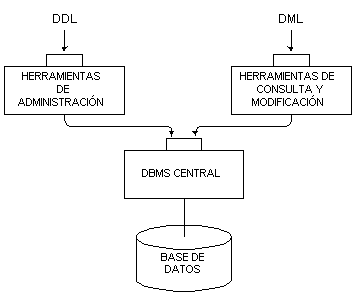
Figura 4.5 Arquitectura separada de RDBMS
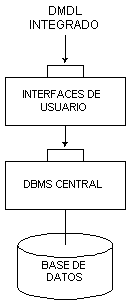
Figura 4.6 Arquitectura integrada de RDBMS
El tipo de arquitectura integrada es en general preferible a la arquitectura separada y el más común entre los RDBMSs comerciales. De todos modos, la consecuencia de una integración de los lenguajes de definición de datos (DDL) y los de manipulación de datos (DML) en un sólo lenguaje (DMDL: Data Manipulation and Description Language), son a nuestro parecer positivas y negativas. Por un lado, esta integración resulta muy cómoda para el DBA, puesto que le basta con aprender un solo lenguaje formal para realizar todas las tareas de creación y mantenimiento de la base de datos. Pero por otro lado, estos sistemas (tanto los separados como los uniformes) fuerzan una proyección directa desde el nivel externo al interno, haciendo que el nivel conceptual, el fundamental según la arquitectura ANSI/X3/SPARC, desaparezca o se implemente en el nivel externo como una vista global externa. Por esta razón algunos DBAs inexpertos tienden a obviar la fase de análisis, cuando de hecho es la vital para la correcta implementación de la base de datos. Insistimos en que un buen modelado conceptual es una condición indispensable para el correcto desarrollo de una base de datos. Pensamos que lo ideal es usar un DBMS que nos permita desarrollar todas las tareas (de descripción y de manipulación) lo más fácilmente posible, pero no sin antes disponer de todas las herramientas necesarias para un correcto modelado conceptual, estén éstas o no incluidas en el DBMS.
La estandarización en cuanto a arquitecturas que presentan las bases de datos no tiene paralelo en el ámbito de las bases de conocimiento. Cada implementación tiene su propia arquitectura. Lo que sí podemos aportar es alguna definición formal, siempre desde el punto de vista de la IA. La siguiente es una de las pocas que encontramos en la literatura (Hodgson 1991:49-50):
Un Sistema de Representación de Conocimiento para un universo U consiste en:
Teniendo en cuenta la definición anterior, podemos deducir los problemas más importantes que la representación de conocimiento presenta:
- ¿Cuáles son los individuos que constituyen el universo?
- ¿Que propiedades poseen?
- ¿Qué relaciones existen entre ellos?
A esta notación se le da el nombre de esquema de representación. En el apartado 4.3 mostramos los esquemas clásicos de representación del conocimiento, incluyendo el basado en marcos, que utilizaremos para la implementación de nuestra ontología.
El primer paso para desarrollar tanto una base de datos como una base de conocimiento ha de ser la elección de un determinado modelo de datos en el caso del primero o de un esquema de representación en el caso del segundo (Mylopoulos 1986). Esta elección repercutirá directamente en las características y posibilidades del sistema de información. En este apartado nos limitaremos a exponer una taxonomía de esquemas de representación para los sistemas basados en el conocimiento clásicos y otra clasificación tradicional de modelos de datos.
A esta actividad, es decir, el estudio de los sistemas desde un punto de vista más o menos abstracto se le denomina modelado conceptual. Por tanto, se entiende por modelado conceptual la descripción de un sistema de información (KBMS, DBMS, aplicaciones construidas con algún lenguaje de programación) en un nivel de abstracción por encima del nivel de arquitectura e implementación.
En IA, el problema de diseñar un sistema experto se centra en construir una base de conocimiento que represente el conocimiento de una empresa determinada. También las metodologías de bases de datos han venido ofreciendo desde su etapa de madurez modelos semánticos de datos. Los modelos de datos clásicos ofrecen niveles de abstracción muy bajos, es decir la correspondencia entre el nivel conceptual y el nivel físico suele ser muy directa. Los modelos semánticos de datos intentan escalar en el nivel de abstracción para poder dar cuenta de estados y procesos complejos de una forma relativamente simple. Como veremos, estos modelos están altamente influenciados por los sistemas de KB, que desde el principio fueron dotados de grandes capacidades de abstracción.
Resulta bastante más interesante describir estos dos tipos de sistemas desde el punto de vista conceptual que desde el de sus arquitecturas, porque el nivel conceptual intenta capturar la verdadera esencia del sistema.
Advertimos que no expondremos por ahora las evoluciones más modernas de estos modelos; nuestra intención es exponer claramente los tipos de sistemas básicos para después estar en posición de entender los sistemas más avanzados que, integrando técnicas clásicas, aportan grandes y valiosas funcionalidades.
NOTAS
Anterior I Siguiente I Índice capítulo 4 I Índice General