– ‘¿Es un avestruz un ave?’
avestruz(x),
(x)[avestruz(x) ave(x)],
ave(x)],
ave(x);
– ‘Sí.’
Todos los conceptos referentes a las bases de datos están hoy muy claros y definidos formalmente, al contrario que los de las bases de conocimiento. La tecnología de gestión de bases de datos se halla en una etapa muy madura. Las bases de datos han evolucionado durante los pasados 30 años desde sistemas de archivos rudimentarios hasta sistemas gestores de complejas estructuras de datos que ofrecen un gran número de posibilidades. Los principales objetivos de un DBMS son los siguientes:
Una base de datos típica conlleva la existencia de tres tipos de usuario con relación a su diseño, desarrollo y uso:
No cabe duda de que la parte más importante es la llevada a cabo por el DBA. A él le corresponde la elección de un determinado modelo de datos y el diseño de la DB. La etapa de diseño es la más importante, ya que es ahí donde se refleja la semántica7 de la información contenida en la DB a través del denominado esquema conceptual. Nos detendremos sobre este tema cuando estudiemos el modelado de datos.
En general, podemos decir que el propósito de una base de datos es doble:
Una consulta (query) se expresa como una expresión lógica sobre los objetos y relaciones definidos en el esquema conceptual; el resultado es la identificación de un subconjunto lógico de la base de datos. Una transacción consiste en un número de consultas y operaciones de modificación o actualización sobre un subesquema. Las transacciones son atómicas8 por definición: todos los pasos de una transacción han de ser debidamente ejecutados y confirmados como requisito previo para que la transacción pueda ser llevada a cabo en su conjunto, en caso contrario ha de ser invalidada.
Para llevar a cabo estas tareas, el DBA tiene a su disposición la principal herramienta de una base de datos, el sistema gestor de bases de datos (DBMS). A través de éste se realizan todas las operaciones con los datos (consultas y transacciones), de forma que al DBA no le atañe la manera en que los datos se encuentran almacenados físicamente, pudiéndose concentrar en los aspectos conceptuales en cuanto a diseño, desarrollo y mantenimiento. Un DBMS típico integra los siguientes componentes:
El QL por excelencia es el llamado Structured Query Language (SQL), que, aun con muchas modificaciones y adiciones, es un estándar de las DBMS relacionales (RDBMS: Relational Database Management System). Hoy en día, sin embargo, con la llegada de las DBMS orientadas a objetos (ODBMS: Object Database Management System), otros estándar de consulta se han hecho necesarios; así ha nacido otro estándar, OQL (Object Query Language), como resultado de una de las primeras implementaciones de ODBMSs (O2, de O2 Technologies). Además, una base de datos puede ser consultada y modificada mediante técnicas "externas", es decir, mediante lenguajes de programación de propósito general, típicamente de tercera generación (3GL). Hoy en día, estas técnicas se hallan muy avanzadas, existiendo estándares que simplifican el acceso a diferentes DBMSs de forma transparente, tales como ODBC (Open Database Connectivity), que garantizan el acceso a los datos de bases, posiblemente remotas, de distintas compañías.
Por lo que a la representación de información léxica se refiere, los sistemas de bases de datos tradicionales presentan serios problemas reconocidos por muchos autores (cf. Ide et al. 1995). En general, las bases de datos no fueron pensadas para almacenar información compleja, sino grandes cantidades de información relativamente simple. Como ya hemos mencionado, los datos contenidos en una DB han de ser por definición atómicos. Esto es necesario para un correcto tratamiento de los mismos, pero por otra parte entorpece la visión de conjunto, esto es, dificulta el tratamiento "inteligente" de entidades complejas.
Este gran inconveniente se hizo evidente una vez superada la fase de dificultades puramente técnicas. Cuando las bases de datos comenzaron a ser utilizadas para otras tareas que no fuesen el guardar los datos correspondientes a una compañía de seguros o una entidad bancaria. Entonces se planteó la necesidad de prestar mayor atención al diseño lógico de la DB, en vez de al nivel físico9. Esta etapa se halla fuertemente influenciada por la investigación en IA, como veremos a continuación.
La representación del conocimiento, entendido en los términos que presentamos anteriormente, es un problema central en el más vasto campo de la Inteligencia Artificial, en cuanto que esta disciplina tiene como principal objetivo el desarrollo de sistemas "inteligentes" que sean capaces de reproducir lo más fehacientemente posible los mecanismos intelectuales comunes en los humanos, de forma destacada, la comprensión del lenguaje natural, el aprendizaje (acumulación de experiencia), el razonamiento lógico, la resolución de problemas y el reconocimiento de patrones (p. ej. en visión robótica). Una definición representativa de lo que comúnmente se entiende por "Inteligencia Artificial" es la de Barr y Feigenbaum (1981:4):
Artificial Intelligence (AI) is the part of computer science concerned with designing intelligent computer systems, that is, systems that exhibit the characteristics we associate with intelligence in human behavior - understanding language, learning, reasoning, solving problems, and so on.
Las técnicas comunes en IA consisten por tanto en el estudio minucioso de la actividad o comportamiento que se desea emular, en primer lugar y después, y sobre todo, su implementación en algún tipo de autómata.
El paradigma actual de "inteligencia", en contraste con el anterior, basado principalmente en técnicas heurísticas de búsqueda (Goldstein & Papert 1977), acentúa la necesidad de conocimiento experto para la realización de tareas inteligentes (Mylopoulos & Levesque 1984). La idea es que lo central para nuestra actividad mental normal es un gran repositorio de conocimiento experto sobre muy diferentes materias específicas y sobre el mundo en general. Por tanto, es evidente que si nuestro objetivo es replicar esquemas mentales humanos en un autómata, éste deberá poseer un repositorio parecido de información del que pueda hacer uso, mediante diversos dispositivos, para el manejo inteligente de esa información. En suma, la posesión de conocimiento es absolutamente indispensable para la realización de una tarea "inteligente".
Sin embargo, como venimos diciendo, esto no fue siempre así. De hecho, podemos distinguir cuatro fases o "categorías históricas" (Barr & Feigenbaum 1981) en el estudio del lenguaje natural por parte de los investigadores de IA:
– ‘¿Es un avestruz un ave?’
avestruz(x),
(x)[avestruz(x) ave(x)],
ave(x);
– ‘Sí.’
Como esta evolución implica, los sistemas de lenguaje natural de IA hoy día están casi exclusivamente basados en el conocimiento. Éste, por otra parte, necesita ser estructurado y debidamente modelado para poder almacenarlo bajo una notación apropiada como repositorio de información. De hecho, podemos afirmar que la representación de conocimiento es el hilo conductor de los diferentes campos que abarca la IA (McCalla & Cercone 1983).
A este repositorio de información estructurada que se usa para resolver tareas que requieren conocimiento experto se le conoce como base de conocimiento. Este concepto, necesita de una definición más formal . Por ejemplo, dicho así - "repositorio de información estructurada" - cabría pensar que una enciclopedia impresa, estructurada en artículos, es una base de conocimiento; sin embargo una KB tiene que poseer otras facultades.
Sin embargo, en lo que respecta a las bases de conocimiento, no existen estándares ni definiciones. En general se supone que un KBMS, a diferencia de un DBMS, debe ofrecer estas dos posibilidades fundamentales (Mylopoulos 1986):
A partir de estos requerimientos deberíamos establecer alguna tipología de KBMSs atendiendo no a su arquitectura (no existen arquitecturas genéricas estándar), sino a su funcionalidad. Lo que caracteriza a los sistemas de representación de conocimiento es que se han desarrollado en diversos ámbitos con propósitos específicos. Mientras que un mismo sistema de bases de datos se puede utilizar para múltiple propósitos, los KBMS no son por lo general de propósito general. (Jarke et al. 1989) presentan la siguiente tipología de aplicaciones de IA en las que las bases de conocimiento son utilizadas:
Son los segundos los que nos interesan, aunque en realidad la mayoría de los sistemas de IA toman la forma de sistemas expertos. Las relaciones entre el procesamiento del lenguaje natural y los KBMS han estado siempre motivadas por los intereses de los investigadores en IA, no por los de lingüistas o lexicógrafos. La aplicación de sistemas basados en el conocimiento a la TA es muy novedosa, y, según pensamos, los clásicos sistemas de KBMS no se adaptan a las necesidades de este tipo de aplicaciones, al no conceder la importancia necesaria a la información detallada en general ni a los aspectos procedimentales. El interés de los investigadores de IA por el lenguaje natural está centrado casi exclusivamente en la comunicación hombre-máquina, por tanto su objetivo es la construcción de interfaces en lenguaje natural que faciliten esta interacción. Éstos son los denominados interfaces de lenguaje natural (NLI: Natural Language Interfaces).
De hecho, el interés por los sistemas de NLP basados en el conocimiento surgió a raíz de la necesidad de construir interfaces en lenguaje natural para sistemas expertos. Estos sistemas son alimentados con toda la información disponible sobre un determinado tema muy específico, por ejemplo diagnósticos médicos, sistemas de ingeniería. Después, mediante un interfaz apropiado que acepta un conjunto de estructuras sintácticas y elementos léxicos específico, son capaces de responder adecuadamente a consultas complejas relacionando la información que poseen.
Las tareas para las que estos sistemas se desarrollan son, casi por definición, complejas (Walker et al. 1987). Por tanto, un sistema experto es un sistema computacional capaz de representar y razonar sobre un dominio determinado que precisa de gran cantidad de conocimiento, tal como la aeronáutica o la medicina. Se puede distinguir de otros tipos de aplicaciones de IA en que (Jackson 1986):
Los sistemas expertos son el tipo de aplicación de IA que mejores resultados ha conseguido. Estos sistemas son usados hoy en día en un amplio abanico de dominios y han probado ser altamente fiables. Por ello sería deseable la disponibilidad de interfaces en lenguaje natural que facilitasen la comunicación con el sistema por parte de usuarios no expertos en computación (médicos, biólogos, ingenieros). Existen tres modos de ver la relación entre un NLI y el KBMS. La primera es la construcción de un NLI para manejar un KBMS. La segunda construir un KBMS para implementar un NLI. La tercera construir un NLI (soportado por el KBMS) para sistemas basados en el conocimiento. Estas relaciones quedan expuestas en la Figura 4.1.
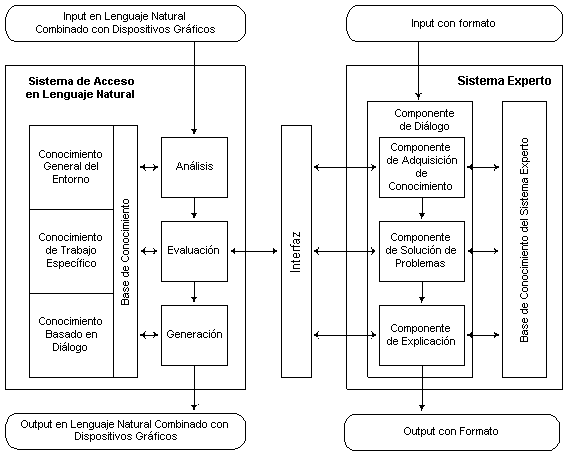
Figura 4.1 Relaciones NLI / KBMS
Para que un programa pueda ser calificado de NLI debe cumplir las dos condiciones siguientes:
Los tres modos anteriormente citados de usar el lenguaje natural en IA reflejan a nuestro parecer tres estadios de investigación, superando una primera fase en que se pretendía un análisis extremadamente simplista del lenguaje. Tras observar la enorme complejidad que éste conlleva, se hizo obvia la necesidad de tratar el lenguaje humano como un objeto de estudio en sí mismo, para poder siquiera pensar en usarlo como medio de interacción hombre-máquina. En esta etapa se empezaron a plantear cuestiones que los lingüistas han estado estudiando desde mucho tiempo atrás. Un KBMS para NLI habrá de integrar los siguientes tipos de conocimiento (Jarke et al. 1989):
La Figura 4.2 resume las fuentes de conocimiento lingüístico necesario para el desarrollo de NLIs según la IA. Este cuadro revela cómo los investigadores de IA contemplan el estudio del lenguaje natural.
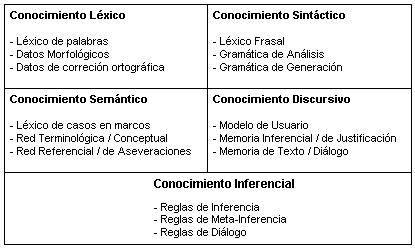
Figura 4.2 Conocimiento requerido por un NLI
Finalmente, en IA se señalan algunas características necesarias en una KB para el procesamiento de lenguaje natural:
Como observamos, las diferencias de descripción detallada de bases de datos y bases de conocimiento son abismales. Las bases de datos son sistemas muy bien establecidos en donde todo lo que puede o no puede llevar a cabo el sistema y cómo llevarlo a cabo está perfectamente establecido. El trabajo en bases de conocimiento se encuentra aún en una fase germinal, y por lo general se trata de sistemas específicos para necesidades específicas. La literatura en torno a las bases de conocimiento es aún altamente programática, intentando sentar las bases de lo que se supone que estos sistemas serán capaces de hacer. No es extraño encontrar aserciones contradictorias en distintos autores con distintos fines. Incluso así, en el siguiente apartado intentaremos mostrar cuáles son las definiciones formales y arquitecturas que se han propuesto hasta ahora. Ni que decir tiene que el entorno de bases de datos se encuentra totalmente establecido. Comenzamos pues por exponer la arquitectura general de bases de datos.
NOTAS
Anterior I Siguiente I Índice capítulo 4 I Índice General