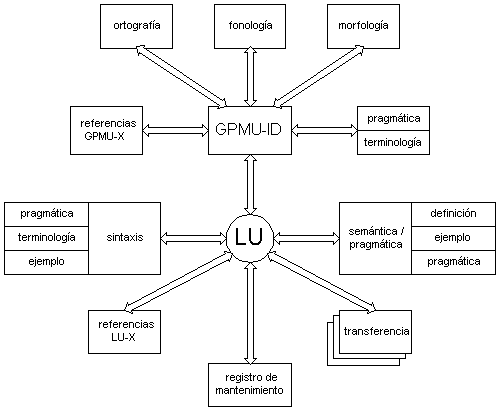
Figura 3.11 Modelo monolingüe de Multilex
El proyecto de ESPRIT Multilex se llevó a cabo con los siguientes objetivos (Krasemann 1991):
El proyecto Multilex comenzó en Diciembre de 1990. La primera fase del proyecto fue coordinada por CAP Gemini Innovation y la segunda por Triumph-Adler, con la debida representación de los grupos nacionales de Eurotra (UMIST, Universidad de Pisa, etc.). Los idiomas que tuvieron cabida en el proyecto (a través de los distintos grupos nacionales) fueron inglés, francés, español, alemán, danés, holandés, italiano y griego. Los lexicones creados variaron entre 40.000 y 120.000 lexemas (EAGLES 1993).
Lo realmente importante de este proyecto fue la consideración del lexicón de las lenguas naturales en términos de modelado de datos18, lo cual implica la inclusión del concepto de "arquitectura lingüística". Según la definición del Expert Advisory Group on Language Engineering Standards (EAGLES),
The linguistic Architecture defines the basic objects of the model and their relations. It also specifies the general terminology which is common to the whole standard and used to talk about dictionaries, their components and the interaction of these.
(EAGLES 1993:14)
El modelo de Multilex fue diseñado desde un principio para ser multilingüe, debiendo dar cabida a todas las lenguas de la UE, por lo que la arquitectura general debería ser independiente de la lengua. Además el modelo debe ser multifuncional, capaz de integrar información utilizable por diversas teorías y aplicable a distintas aplicaciones de NLP (no sólo a la traducción automática). Además, el diseño debería ser independiente de cualquier representación interna de base de datos19.
Multilex ofrece una arquitectura doble. Por un lado la arquitectura monolingüe, y por otro la multilingüe. El enfoque de Multilex a la traducción automática es, siguiendo los parámetros de Eurotra, de transferencia. Por un lado se especifican las necesidades de los distintos diccionarios monolingües y por otro cómo relacionarlos. El conjunto de especificaciones producidas por el proyecto Multilex es conocido como el modelo MLEXd, tal y como ya habíamos anticipado.
Describiremos en primer lugar la arquitectura monolingüe.
La noción básica en la arquitectura de Multilex es la unidad léxica (LU: Lexical Unit), que se define como "the description of a linguistic sign with its form and content characteristics" (Multilex 1992:4). Una LU es una unidad con un significado (y uno solo), por lo que no puede ser la forma gráfica correspondiente. Ésta es denominada (al igual que en otros enfoques a la formalización del léxico que ya hemos visto) "forma canónica". Varias LUs pueden corresponder a una única forma canónica.
Un diccionario (monolingüe) diseñado según los estándares de Multilex consiste, básicamente, en (Multilex 1993):
De estas distintas descripciones, las únicas obligatorias son las dos primeras, siendo el resto opcionales. Como se puede observar, el grueso de la descripción léxica es específica de cada lengua. De este modo se pueden describir las características morfológicas específicas de cada lengua por separado. Por ejemplo, el género no es relevante para los sustantivos y adjetivos en inglés, pero sí lo es en español o alemán; del mismo modo, existen los valores masculino, femenino y neutro para el alemán, mientras que en español, italiano o francés el neutro es irrelevante.
La especificación de reglas hace posible referirse a una regla aplicable a un determinado objeto léxico sin tener que describir esta regla. Normalmente se utiliza un nombre de referencia. Por ejemplo, una aplicación cliente puede referirse a las reglas de formación del plural para una determinada lengua sin conocer cuál es el funcionamiento o el nombre real del módulo morfológico responsable20.
La arquitectura léxica de Multilex se basa en la descripción léxica en dos niveles o nodos:
La motivación de esta separación no es otra que la clásica distinción saussereana de "signo lingüístico", estableciendo una distinción entre las características formales por una parte, y los rasgos de contenido por otro. Esta clásica idea de "signo" ha sido retomada por teorías gramaticales modernas de las conocidas "basadas en la información"; muy especialmente la gramática sintagmática de control nuclear (HPSG: Head-Driven Phrase Structure Grammar) (Pollard & Sag 1987).
Las descripciones léxicas de MLEXd, aunque enfocadas a ser neutrales con respecto a la teoría lingüística que habrá de hace uso de esta información léxica, están muy enfocadas a servir de soporte a este tipo de teorías gramaticales (Multilex 1993:5-10).
Una descripción léxica completa resulta de la unión de los GPMUs y LUs apropiados. En la Figura 3.11 presentamos el modelo monolingüe de Multilex (Multilex 1992).
Este modelo de descripción léxica tiene las siguientes implicaciones:
Como podemos ver, este modelo de descripción léxica es muy versátil. La arquitectura no impone ninguna jerarquía sobre las GPMUs. Las distinciones entre formas largas, siglas, abreviaciones, variaciones, etc. se expresan mediante rasgos, al igual que las preferencias (motivadas por la estandarización) de una determinada variante. Por ejemplo, "DNA" y "deoxyribonucleic acid" son dos formas del mismo significado (misma LU) que pueden ser descritas mediante dos GPMUs, cada una de ellas con el rasgo pertinente describiéndolas como "iniciales" o "forma larga". Esta disposición también permite que variaciones morfológicas de un mismo significado, como "cheque" y check" se definan mediante dos GPMUs, añadiendo el rasgo geográfico apropiado a cada una de ellas (UK / US)
Figura 3.11 Modelo monolingüe de Multilex
MLEXd también ofrece medios de tratar las formaciones multi-palabra mediante las denominadas CGPMUs21 (Complex GPMUs). La organización en dos nodos sigue siendo válida para éstas. De este modo se pueden tratar complejos multi-palabra de una forma eficiente. Por ejemplo, el compuesto "Object Database Management System" se puede describir mediante una sola LU (para su único significado) y dos GPMUs, una para la forma larga (CGPMU) y otra para las iniciales "ODBMS" (GPMU). La adición de este subnodo de descripción tiene como objeto dar cuenta de la estructura interna del compuesto. El CGPMU contiene la misma información que el GPMU, pero además contiene referencias a las GPMUs de cada uno de los componentes que forman el compuesto. Por ejemplo la CGPMU de "Object Database Management System" contendrá referencias a las cuatro GPMUs de las palabras constituyentes: "object", "database", "management" y "system".
En el diseño de nuestra base de datos, que mostraremos en el Capítulo 5, haremos uso de estas especificaciones. Como veremos en el siguiente capítulo, el modelo de datos relacional aporta mecanismos muy eficientes para el tratamiento de este tipo de situaciones. Concretamente, una relación de uno a muchos, mediante una clave externa, permite dar cuenta de las relaciones que hemos mencionado entre una LU y varias GPMU, es decir, un significado puede tener muchas realizaciones grafémicas, fonéticas y/o morfológicas.
La definición y descripción del nodo LU, es, por supuesto, la que plantea más problemas. Siguiendo la tónica general del proyecto Eurotra, el enfoque de Multilex a este aspecto es muy ecléctico. En realidad, pensamos que la descripción semántica aportada no es todo lo completa que sería necesario, haciéndose evidente el deseo de sus diseñadores de evitar el compromiso con teorías gramaticales concretas.
Come hemos mostrado, una LU se define como un identificador de un solo significado. En Multilex, El significado de "significado" queda totalmente abierto; puede ser especificado por una determinada teoría semántica o léxico-semántica (si la aplicación cliente usa una) o puede referirse simplemente a la noción que intuitivamente ha utilizado la lexicografía tradicional para separar las distintas acepciones que se listan bajo las formas canónicas.
Para definir una LU se usan varios "bloques" de rasgos, siguiendo los siguientes parámetros:
Por lo que respecta a la semántica, en Multilex se proponen dos enfoques distintos:
Estos dos enfoques son compatibles con el estándar Multilex. Sin embargo, el objetivo no es imponer un enfoque semántico determinado, sino ayudar a identificar, aclarar y comparar elementos de información léxica para facilitar el diseño, uso y reutilización del léxico. La realidad es que, en lo que respecta al modo de representar la información semántica, las estrategias propuestas por Multilex no son todo lo detalladas que deberían ser. Obviamente, éste es un punto difícil de tratar en cualquier enfoque de representación léxica, sobre todo cuando se pretende alcanzar un consenso entre los distintos participantes en el proyecto. De hecho, se afirma que
[...] at present, there is no available multilingual lexical resource large enough to demonstrate universal validity of a single semantic theory. There is an enormous amount of work to do before some uncontroversial results are achieved.
(EAGLES 1993:10).
Nuestra postura en cuanto a este espinoso tema es muy parecida. Resulta obvio que aún no se ha llevado a cabo ninguna teoría gramatical o lingüística que describa una metodología de descripción semántica universalmente válida y que a la vez aporte las especificaciones de formalización de las descripciones semánticas. Sin embargo, este hecho no significa que debamos renunciar a describir formalmente las unidades léxicas de una lengua.
En cuanto a la sintaxis, en la mayoría de los casos una LU se corresponde con una descripción sintáctica, pero, como se puede apreciar en la Figura 3.12, es posible expresar variantes sintácticas de un mismo significado. Esto se puede llevar a cabo de dos formas dentro de un mismo bloque de descripción sintáctica:
Cuando la variación sintáctica no puede ser expresada por ninguno de estos métodos, siempre queda el recurso de utilizar múltiples bloques y referirlos a una misma LU. Con cada uno de estos bloques es posible incluir distintos ejemplos de uso (ver Figura 3.12).
Para concluir la descripción del modelo monolingüe de Multilex, comentaremos el tratamiento que se propone de la terminología.
Multilex decidió no otorgar a los términos específicos un estatus diferente al resto de los lexemas. Su descripción léxica se realiza utilizando los mismos nodos que ya hemos mostrado. Lo que diferencia a un término de un lexema común es que ha de ser relacionado con la sublengua y el contexto conceptual al que pertenece. Esto se especifica en el correspondiente bloque semántico. En el caso de que un mismo lema tenga una lectura "normal" y una terminológica, se especifican distintos bloques semánticos. El contexto terminológico de una determinada sublengua muestra restricciones específicas respecto al uso de sus términos. Estas restricciones pueden afectar a cualquier nivel de descripción lingüística.
De este modo, la información sobre el uso de un término, o los dominios y sectores sobre los que éste se aplica, y que determina el uso de este término, no está concentrada en un bloque específico de descripción terminológica, sino que esta información se adjunta al bloque de rasgos pertinente. Por tanto, esta información se puede adjuntar a bloques sintácticos, semánticos, GPMUs y CGPMUs.
Describimos a continuación la arquitectura multilingüe.
La noción operacional es la unidad léxica (LU). Como hemos mostrado, este nivel de descripción identifica los distintos significados dentro de una lengua, organizando su semántica. Las equivalencias entre lenguas se obtienen relacionando las LUs de las distintas lenguas siguiendo determinadas reglas relacionales que mostramos a continuación. La Figura 3.12 muestra gráficamente esta arquitectura multilingüe para tres lenguas.
Los diccionarios estándar Multilex son por tanto
monolingües. Desde las LUs de cada uno de los diccionarios monolingües es posible
especificar equivalencias a otras LUs de otros idiomas. Estas equivalencias se tratan de
forma separada. Las descripciones de estas equivalencias se expresan en un bloque
específico. La relación puede ser uno-a-varios para expresar múltiples LUs en lengua
meta. Por ejemplo:
DE "Fahrrad-lu..." EN "bicycle-lu..."
EN "bike-lu..."
EN "cycle-lu..."
SP "bicicleta-lu..."
SP "bici-lu..."
FR "bicyclette-lu..."
FR "vélo-lu..."
Como se puede observar, el sistema de equivalencias está basado en el modelo de transferencia. Cada uno de los diccionarios monolingües se encarga de la descripción de las LUs según criterios monolingües, mientras que la transferencia se encarga de acomodar esta información a las necesidades de la lengua meta. Desde este punto de vista, las nociones de "origen" y "meta" sólo son válidas desde el punto de vista de la transferencia.
El bloque de equivalencias bilingües contiene, junto con la LU meta, información contrastiva bilingüe, tal como las discrepancias de significado entre las LUs de origen y meta o las modificaciones necesarias para la adecuación sintáctica.
Aunque las LUs son objetos semánticos, la transferencia está basada en la sintaxis. Esto no es una restricción impuesta por el estándar, sino que resulta del supuesto de que "large lexical resources do not provide extensive lexical descriptions yet which could supply enough information to perform semantic-based matching" (EAGLES 1993:13). Por supuesto, es muy difícil y costoso dotar a una base de datos léxica extensa del nivel de granularidad de información semántica necesario para llevar a cabo transferencia semántica.
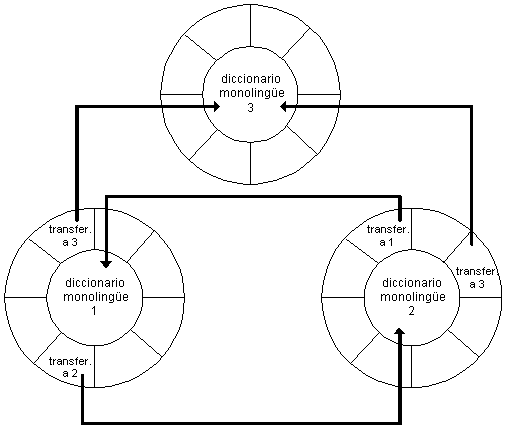
Figura 3.12 Modelo multilingüe de Multilex
Además, el sistema de transferencia propuesto es unidireccional. Para cada una de las transferencias bilingües, la LU de origen se considera desde el punto de vista de la lengua origen, y los bloques de transferencia se crean según las exigencias de las LUs meta. Así, el conjunto de reglas de desambiguación se aplican a un par de lenguas y sólo en una dirección. Los bloques de transferencia, por tanto, no son reversibles, aunque se afirma que un buen número de bloques de transferencia (los de las LUs que se declaran como "fully equivalent" son reversibles automáticamente).
El desarrollo conceptual de Multilex fue llevado a cabo siguiendo el modelo Entidad/Relación (Chen 1976). No nos extenderemos en la descripción de este modelo de datos en esta sección, puesto que nosotros también lo usaremos para el modelado e implementación de nuestra base de datos léxica y lo describiremos en detalle en el Capítulo 5, donde también compararemos algunos de los diagramas conceptuales de Multilex con los nuestros.
Para concluir la descripción de Multilex diremos que este relevante proyecto propone una arquitectura lingüística estándar, multilingüe y reutilizable. Constituye un gran esfuerzo en cuanto a reutilización de recursos léxicos al que aludíamos en el Capítulo 2, utilizando técnicas de modelado de datos estándar. La arquitectura lingüística de Multilex combina el enfoque lexicográfico con facilidades las del medio electrónico. La organización de los datos aporta un terreno lógico y lingüístico para la construcción de interfaces de usuario para acceder a la información lingüística y lexicográfica de un modo más o menos transparente, siguiendo los parámetros de la arquitectura cliente/servidor. La independencia de los datos también permite definir fácilmente sub-modelos derivados de la arquitectura lingüística inicial mediante la extracción de subconjuntos de información del recurso principal a una aplicación cliente.
En general, todas estas características son positivas y necesarias. El modelo de representación que proponemos en este trabajo persigue también estos objetivos y, de hecho, guarda muchas similitudes con la arquitectura lingüística monolingüe de Multilex, usando los mismos métodos de modelado conceptual y también la misma plataforma de base de datos, el modelo relacional.
En cuanto a la arquitectura multilingüe, Multilex propone un sistema de transferencia sintáctica que podría ser mejorado. El sistema de transferencia unidireccional propuesto ofrece ventajas de organización y facilita el desarrollo del sistema, ya que cada uno de los equipos de desarrollo (nacionales) se encarga sólo de un par de lenguas y una dirección. Sin embargo, la transferencia unidireccional multiplica el número de módulos de análisis y generación y, en general se considera engorrosa. Frente al modelo de transferencia, nosotros defendemos los basados en el conocimiento. Como veremos en el apartado 3.3.2, la implicación más importante de esta decisión es la inexistencia en los lexicones monolingües de enlaces explícitos con las unidades léxicas de otras lenguas. Las equivalencias de traducción se llevan a cabo a través de una ontología de conceptos organizada jerárquicamente.
NOTAS
Anterior I Siguiente I Índice capítulo 3 I Índice General