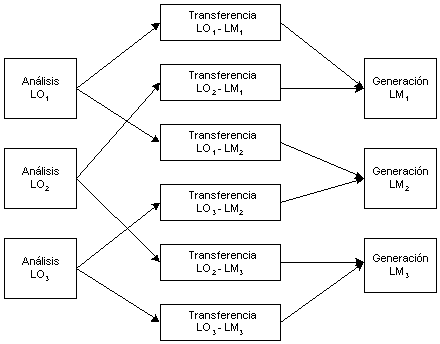
Figura 3.7 Modelo de transferencia para seis pares de lenguas
En cualquier caso, el enfoque directo a la TA en su forma pura, es obviamente considerado hoy en día como naïve. Sus deficiencias fueron puestas de manifiesto en el bien conocido informe ALPAC (ALPAC 1966) y aunque en algunos casos se continuó trabajando sobre esta arquitectura, en general se buscaron fórmulas que evitasen los defectos arriba expuestos.
Los avances en NLP, lingüística computacional, computación y lingüística teórica condujeron a los enfoques indirectos a la Traducción Automática, también llamados de conocimiento lingüístico. La idea común a todos los enfoques indirectos (básicamente, transferencia e interlingua) es que para conseguir TA de alta calidad es indispensable tener información tanto de la lengua de origen como de la lengua meta. También es común la necesidad de una representación intermedia que capture el "significado" de la oración del texto de origen para generar una oración en el texto meta que sea equivalente en significado.
El primero de éstos que mostró sistemas viables fue la arquitectura de transferencia (Trujillo 1995)9. La principal característica de los sistemas de transferencia es la existencia de un módulo adicional de transferencia que proyecta representaciones intermedias del texto origen sobre representaciones intermedias del texto meta. Éste módulo de transferencia puede trabajar en distintos niveles de análisis lingüístico, por lo que se pueden distinguir tres tipos de transferencia (Hutchins & Somers 1992):
Sea cual sea el tipo de transferencia que el sistema lleva a cabo, hay una característica común a todos los sistemas basados en transferencia, y es el elevado número de módulos que deberán ser implementados según aumenta el número de lenguas. En concreto, para un sistema que trabajase n lenguas deberían ser implementados al menos n(n-1) módulos de transferencia, es decir, cada lengua requerirá sus propios componentes de análisis y generación y, además, existirá un módulo de transferencia (dos en el casos de sistemas unidireccionales) para cada par de lenguas. La Figura 3.7 muestra una disposición típica de un motor de transferencia para seis pares de lenguas.
Un sistema de TA basado en el modelo de transferencia incorpora, por una parte, un análisis monolingüe del texto origen, al cual le sigue una segunda fase que utiliza conocimiento bilingüe. El sistema de representación que transporta la información sobre el texto entre los dos análisis son las llamadas estructuras normalizadas, intermedias, o interfaz (Whitelock & Kilby 1995).
Figura 3.7 Modelo de transferencia para seis pares de lenguas
En un sistema de transferencia típico, la cadena del texto de origen se analiza primero morfológicamente y el resultado se analiza sintácticamente dando como resultado una representación sintáctica superficial. Esta representación se transforma después en una representación más abstracta que ignora algunos fenómenos no relevantes para el proceso de traducción, aportando a su vez una representación más apropiada de otros tipos de información. El módulo de transferencia convierte esta representación (que está aún ligada a la lengua de origen) a una representación al mismo nivel de abstracción pero ligada al lenguaje meta. Estas dos representaciones son las llamadas normalizadas, de interfaz o intermedias. A partir de esta representación el proceso se invierte: los módulos de síntesis generan una representación sintáctica del texto meta y finalmente la cadena de texto en la lengua meta.
Como veremos, las críticas más importantes al paradigma de interlingua son también aplicables al de transferencia, y tienen que ver precisamente con las representaciones abstractas (que tanto uno como otro usan, sólo que en distintos niveles de abstracción). La crítica se basa en el hecho de que la derivación de una estructura abstracta a partir de una estructura sintáctica superficial dejará de lado algunas diferencias en cuanto al orden de las palabras que no tienen, en principio, repercusiones semánticas. Por ejemplo, la estructura interfaz sería la misma para las oraciones 1a y 1b.
1a. Sam gave the money to Max
1b. Sam gave Max the money
En general, se podría imponer algún tipo de orden canónico y reemplazar las palabras puramente gramaticales (sin contenido léxico) por rasgos o marcas en las categorías pertinentes. Por ejemplo, el tipo de determiner (a vs. the) se podría marcar mediante el rasgo DEF. Esto podría resultar en una estructura como la de 1c.
1c [S gave [ NP Sam ], [ NP-DEF money ], [ NP Max ]
El módulo de transferencia se encargaría de relacionar esto
con una estructura que subyace a las frases correspondientes en la lengua meta. En el caso
de la traducción inglés ![]() español, se podrían usar la siguiente regla:
español, se podrían usar la siguiente regla:
[ gov:give, subj:$1, obj:$2, iobj:$3 ]
![]()
[ gov:dar, subj:$1, obj:$2, iobj:$3 ]
El hecho de que el verbo español dar requiere la preposición a para introducir el objeto indirecto no influye en la fase de transferencia, sino que sería resuelto en la síntesis. Lo que esta regla indica es una instrucción para traducir una estructura cuyo governor (el núcleo de la oración) es give (y que tiene un sujeto, un objeto y un objeto indirecto), en una estructura cuyo governor es dar y cuyo sujeto es la traducción del sujeto de give (lo mismo para el objeto directo y el objeto indirecto)10. Este enfoque es muy versátil, porque permite establecer condiciones de traducción según el tipo de constituyente que exprese el sujeto, etc. Por ejemplo, se podría especificar que el verbo inglés know se tradujese por conocer (en lugar de saber) cuando el objeto del verbo fuese un sintagma nominal (como en Sam knows Max). Esto se podría especifica con una regla como la siguiente:
[gov:know, subj:$1, obj:$2[NP] ]
![]()
[gov:conocer. Subj:$1, obj:$2 ]
No entraremos en este trabajo en la conocida disputa "transfer vs. interlingua"11. Como mostraremos más adelante, este debate se puede considerar ya como obsoleto, puesto que los enfoques de interlingua modernos (esto es, los enfoques basados en el conocimiento) tienen muy poco que ver con la interlingua primitiva que ha recibido un sin fin de críticas. Adelantamos, sin embargo, que nuestra elección es precisamente la traducción basada en el conocimiento, aunque desde un ángulo ecléctico y enfocado siempre a la consecución de resultados prácticos. Volveremos sobre este tema en el apartado 3.3.2.
NOTAS
Anterior I Siguiente I Índice capítulo 3 I Índice General