
Figura 3.5 Arquitectura directa
Los enfoques más primitivos a la TA contaban con unos recursos computacionales muy limitados y prácticamente no existían teorías lingüísticas formales. En estos sistemas no era infrecuente contar con lexicones de 250 palabras para la lengua de origen y algunas decenas de reglas gramaticales para dar cuenta de los procesos de desambiguación y de reordenación del texto meta. En definitiva, la traducción se realizaba palabra por palabra, al no contar con un proceso de análisis del texto meta previo a la traducción.
En su forma más pura, la traducción directa conlleva la traducción palabra por palabra junto con un proceso de equivalencias de cadenas y reordenación del texto meta. Los problemas inherentes a tal metodología son evidentes: el sistema no toma en consideración la estructura sintáctica de la frase ni las relaciones semánticas que existen entre las palabras (Trujillo 1995). Además, no existe ninguna forma de asegurar la correcta formación de las expresiones del lenguaje objeto, ya que no existen reglas gramaticales. De tal modo que una frase como "Pedro la tocó" podría ser traducida al inglés por un sistema de traducción directa como "Peter the touched" debido a la homonimia que exhibe la palabra española "la" (pronombre – artículo).
La principal idea, por tanto, de un sistema de traducción directa es transformar las frases de LO en frases de LM de la manera más simple posible, reemplazando palabras de LO con sus correspondientes de LM siguiendo un determinado diccionario bilingüe, y después reordenándolas según las reglas especificadas para la lengua meta en cuestión. La Figura 3.5 (Hutchins & Somers 1992:115) muestra tal tipo de motor de traducción.
Figura 3.5 Arquitectura directa
Este tipo de motores de traducción lleva a cabo un sucinto análisis morfológico del texto origen, consulta el diccionario bilingüe y ejecuta las rutinas de reordenación local sobre los constituyentes finales. La Figura 3.6 muestra este tipo de proceso con algunas reglas gramaticales añadidas para la traducción español - inglés.
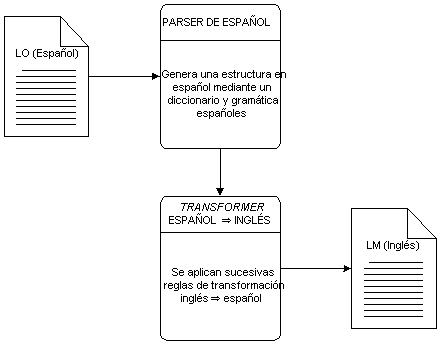
Figura 3.6 Arquitectura de un sistema directo (español - inglés)
A continuación mostramos los pasos concretos que un sistema de estas características toma para llegar a la traducción del texto (Arnold et al. 1994). Al igual que en el diagrama, suponemos que LO es español y el LM inglés. Tomaremos la frase "El gato buscará al ratón" como supuesto input para nuestro motor de traducción directo.
Paso 1: las cadenas del texto origen se comparan con las existentes en la base de datos y se les asigna la correspondiente parte de la oración a cada una de ellas. Dependiendo de la forma que estas cadenas presenten, esta búsqueda será más o menos fácil. Con toda seguridad habrá que hacer uso de un componente morfológico que pueda realizar búsquedas inteligentes. Por ejemplo, al encontrarse una cadena como "buscará", el parser morfológico podría hacer uso de una regla que indique "si encuentras una cadena que acabe en ‘ará’, recorta esta segunda cadena y compara el resultado con la lista de raíces verbales", con lo que el algoritmo correctamente asignaría el lema verbal buscar a la cadena "buscaría". El analizador morfológico puede incluso ir más allá e intentar dar alguna explicación a cadenas para las que no se encuentra un lema plausible. Por ejemplo, aunque la base de datos no contenga el verbo "faxear", el analizador puede ser instruido para que, de todos modos, considere tal cadena como un verbo, independientemente de que no se le pueda adscribir ningún lema.
Paso 2: se aplican las reglas de la gramática de español. El SN "al ratón" sería marcado como el objeto del verbo "buscará".
Paso 3: se aplican las reglas de transformación (traducción) de forma directa. Por ejemplo el artículo "El" se transformaría en el inglés "The", "gato" en "cat", y así sucesivamente. Lo más probable es que tengamos una regla que establezca una equivalencia entre la contracción "al" y las palabras "to the", con lo cual tal correspondencia también sería establecida. En estos momentos el sistema contendría una representación interna con la forma "The cat seek[future] to the mouse".
Paso 4: el motor aplicaría las reglas que modifican las formas base de su representación a las formas morfológicas correctas para el inglés. En nuestro ejemplo la única forma que necesita ser inflexionada es la del verbo, así que el módulo morfológico convertiría la secuencia "seek[future]" en "will seek".
El resultado sería la frase "The cat will seek to the mouse", que contiene una incorrección gramatical ya que el verbo inglés "seek" no requiere la preposición "to" para introducir el objeto. Sin embargo, un típico sistema de traducción directa no sería capaz de resolver esto a no ser que contenga un conjunto de reglas de reordenación muy amplio. Por supuesto, no se realiza ninguna elección de un determinado equivalente de traducción según el contexto. En un sistema más avanzado, el sistema podría contener algunas directrices para elegir entre equivalentes alternativos, en nuestro caso tal vez podría elegir entre los verbos relacionados "seek", "search" y "look for".
Tampoco se suele llevar a cabo en este tipo de sistemas ningún método de resolución de ambigüedad semántica. Por ejemplo, si tuviésemos la frase "El gato se rompió al intentar levantar el coche", probablemente obtendríamos el mismo equivalente (incorrecto en esta ocasión) "cat".
Una característica fundamental de este tipo de arquitecturas es la utilización de gramáticas muy simples (Arnold et al. 1994; Hutchins & Somers 1992), de tal modo que en la mayoría de los casos el sistema no es capaz de decidir si una determinada frase de la LO es correcta gramaticalmente o no, limitándose a traducir los distintos componentes por él hallados. La competencia de traducción de estos sistemas se reduce por tanto a las reglas de transformación de las palabras o frases que contiene en su diccionario bilingüe.
Otra característica que limita seriamente las posibilidades de las arquitecturas transformer es la total inexistencia de una gramática de la lengua meta. La única información que el sistema posee sobre esta lengua son las reglas morfológicas de formación de palabras, aparte, claro está, de las reglas de transformación (traducción). De ahí que errores tales como el anterior "seek to the mouse" sean corrientes. Así, en estos sistemas no existe ninguna garantía de que la traducción resultante sea gramaticalmente correcta. Aunque en la mayoría de los casos el resultado se asemejará a la LM, en otros muchos no obtendremos más que una "ensalada de palabras" ininteligible (Arnold et al. 1994:38).
Por supuesto, el lexicón de uno de estos sistemas está acorde, en cuanto a calidad de información léxica, con el tipo de gramática. Se trata típicamente de un diccionario con equivalencias de traducción de uno a uno, en donde no cabe la ambigüedad semántica. Las distintas entradas carecen de cualquier tipo de información aparte de la morfológica, ya que la sintaxis se implementa directamente en los algoritmos de parsing. En suma, estos lexicones son el resultado de una época en la que se carecía de experiencia alguna en el tratamiento automático del lenguaje natural y en la que los análisis morfológico y sintáctico eran considerados los realmente relevantes.
Todo esto nos lleva a pensar que un sistema de TA con arquitectura directa no es en absoluto apropiado. Sin embargo hemos de romper una lanza en su favor, ya que uno de los sistemas más importantes y con más repercusión a nivel mundial, Systran, es en esencia un sistema directo de primera generación8.
NOTAS
Anterior I Siguiente I Índice capítulo 3 I Índice General