ISSN: 1139-8736
Depósito Legal: B-35510-2000
Escogemos este sistema para ilustrar la arquitectura transformer no por ser
representativo, ya que posee muchas virtudes que le hacen separarse radicalmente de otros
sistemas de su época, sino más bien como ejemplo de un sistema bien diseñado desde el
principio. En efecto, partiendo de una arquitectura hoy absolutamente desfasada, el
robusto diseño de este sistema le ha permitido evolucionar de forma sorprendente.
Hoy día, Systran® Software Inc. ofrece multitud de
soluciones en cuanto a traducción automática se refiere, incorporando los idiomas
español, francés, italiano, alemán, portugués y japonés. Además existen versiones
para las plataformas más difundidas (Unix, PC bajo Win32), e incluso se ofrece en
arquitectura cliente/servidor.
La principal característica que ha hecho posible la
supervivencia de este sistema desde los Años Oscuros es sin duda su modularidad
(Whitelock & Kilby 1995).
Esta modularidad se manifiesta en tres vertientes:
- El código. Los programas del sistema, escritos en ensamblador, son independientes de
los distintos idiomas. Los programas de traducción propiamente, escritos en un lenguaje
de macros, son dependientes del par de lenguas que están destinados a traducir.
- El proceso de traducción se divide en una serie de procesos que se reparten entre los
distintos módulos (homógrafos, delimitación de frases, etc.)
- Los programas de traducción se dividen en tres tipos: específicos de LO, específicos
del par de lenguas y específicos de LM.
Esta disposición es, por tanto, típica de un sistema de
transferencia. El proceso de traducción queda reflejado en la Figura 3.9 (Hutchins
& Somers 1992:255).
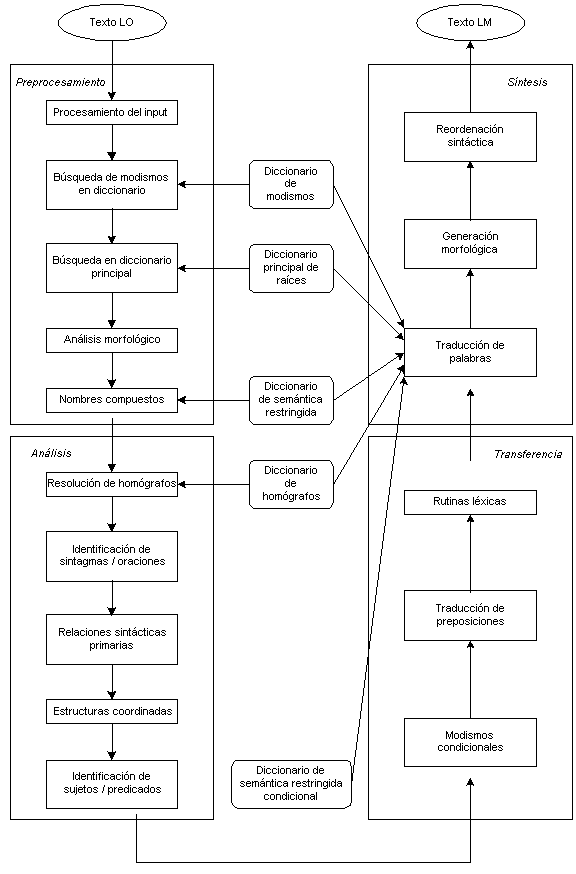
Figura 3.9 El proceso de traducción de Systran
Por lo que respecta al lexicón, la base de datos
léxica de Systran consiste básicamente en dos diccionarios bilingües (por par de
lenguas, claro está): el diccionario de palabras simples y el diccionario de expresiones multi-palabra.
En realidad, estos dos diccionarios se encuentran distribuidos en varios ficheros
magnéticos de acuerdo con ciertos parámetros como la frecuencia o la longitud de las
entradas. La clasificación de los distintos tipos de idioms y expresiones
multi-palabra es muy destacable, atendiendo siempre a las dificultades de traducción que
las distintas construcciones presentan. Es sin duda este aspecto otra de las claves del
éxito de este sistema: además de establecer una rica tipología de frases, sus
diccionarios contienen unas extensísimas listas de correspondencias frasales entre
idiomas, lo que facilita enormemente todos los procesos involucrados en la traducción.
En cuanto a la información léxica que cada entrada
contiene, cada registro de la base de datos contiene únicamente siete campos12:
- "-" line
: contiene la palabra o expresión propiamente, junto con algunos
códigos que representan el tipo de entrada y otros códigos de control.
- A-line
: contiene los códigos de inflexión para las palabras simples.
- B-line: contiene algunos códigos que marcan la categoría gramatical, el
género, el número (para los sustantivos, pronombres y adjetivos), el caso (en inglés
para los pronombres posesivos / objeto), y otros.
- C-line
: contiene información sintáctica o sintáctico-semántica detallada. El
número de códigos que puede aparecer en una entrada es variable, separados entre sí
mediante comas.
- D-line
: contiene códigos de naturaleza semántica. Se han definido unos 450
códigos diferentes. En la práctica, sólo una pequeña parte de éstos se han usado. La
decisión de incorporar etiquetas semánticas no responde a la adopción de una teoría
lingüística determinada sino que se ha hecho de una forma ad hoc, para resolver
problemas de traducción puntuales. Por ejemplo el verbo employ será traducido al
francés employer en lugar de utiliser siempre que el objeto sea descrito
con la etiqueta semántica prof.
- E-line
: la primera sección bilingüe de la entrada. Codifica la traducción
apropiada de la o las preposiciones que rige la entrada cuando ésta difiere de la
traducción que la preposición tiene en su propia entrada. Por ejemplo, wait for,
que en español debe ser esperar a, irá acompañado de un código que indique la
entrada de la preposición española a, tal y como aparece en la tabla de
preposiciones de la lengua meta.
- F-line
: contiene los equivalentes de traducción de la lengua meta, así como
información morfológica, sintáctica y de otros tipos requerida para la síntesis de la
lengua meta.
Los problemas que la polisemia plantea para la traducción se
reducen en Systran de varias maneras:
- Distintas entradas en el diccionario para homógrafos del texto origen.
- El uso de distintas entradas de idiom, LS o CLS para distinguir entre distintos
significados de una palabra del texto origen en diferentes contextos oracionales.
- La aplicación, durante la fase de transferencia, de rutinas léxicas que aportan la
correcta traducción de las palabras de la lengua origen para las que se las llama.
Cuando la polisemia tiene su origen en un contexto
supra-oracional, se recurre a códigos de tópico (TG: typical glossary) que
definen el tipo de texto/campo, y que deben ser previamente explicitados. Por ejemplo
0 general
1 physics
2 electronics
3 computers, data processing
(...)
La información léxica contenida en la LDB está organizada
en varios ficheros según las necesidades de acceso durante las diferentes fases de la
traducción. Estos ficheros, que constituyen los distintos diccionarios son:
- hfwdhigh-frequency word table
- hfithigh-frequency information table
- ridsource idiom table
- eidtarget idiom table
- ldictlong-stem dictionary (> 7 caracteres)
- mdictmedium-stem dictionary (4-7 caracteres)
- sdictshort-stem dictionary (< 4 caracteres)
- gdictgrammar dictionary
- lsdict – ls/clsdictionary
- xlsdict – ls/clsdictionary index
NOTAS
- La estructura interna de la base de datos es específica para el
sistema. Como nota destacable, no mantiene el principio de atomicidad deseable en todo
sistema de información moderno, ya que, como ha quedado claro, los "registros"
son de longitud variable. Esta característica, heredada de los sistemas de información
antiguos impide la reutilización de la información
Anterior
I
Siguiente
I
Índice capítulo 3
I
Índice General