Las actividades llevadas a cabo en el proyecto Acquilex (The Acquisition of Lexical Knowledge for Natural Language Systems) se pueden dividir en dos áreas de trabajo principales: primero, el desarrollo de herramientas informáticas que permitieran la extracción de información léxica de varios MRDs, y su posterior volcado a una LDB (Lexical Data Base). Segundo, la adopción o desarrollo de un marco teórico apropiado para dar cuenta de diversos fenómenos léxicos y de este modo facilitar la construcción (semi-automática) de una LKB (Lexical Knowledge Base) a partir de la información contenida en la LDB, con la ayuda de una serie de herramientas informáticas diseñadas para integrar, transformar y enriquecer la información contenida en la LDB (Briscoe, 1991).
Este proyecto, integrado dentro de la acción SPRIT BRA-3030, se dividió en dos fases (Acquilex I y Acquilex II), y en él participaron diversas universidades europeas, entre ellas la de Amsterdam, la Politécnica de Cataluña, la de Cambridge, la de Dublín, la de Pisa, junto con el Instituto de Lingüística Computacional de Pisa. Contó, así mismo, con la participación de cuatro editoriales (sobre todo en la segunda fase del proyecto): Cambridge University Press, Biblograf, Garzanti y Van Dale Lexicografie.
La finalidad primordial de Acquilex I era la adquisición de información léxica, no ya de un solo MRD, como había sido hasta entonces lo normal en casi todos los proyectos de investigación, sino de varios, y de varias lenguas, integrando dicha información en una sola LDB. Con ello, intentaban hacer frente a los problemas que, tal y como señalamos en el apartado anterior, plantea el uso de MRDs como fuentes de información léxica: falta de consistencia, circularidad en las definiciones, falta de información, etc.
En la extracción de la información de MRDs se llevaron a cabo los siguientes pasos (Calzolari & Briscoe, 1994):
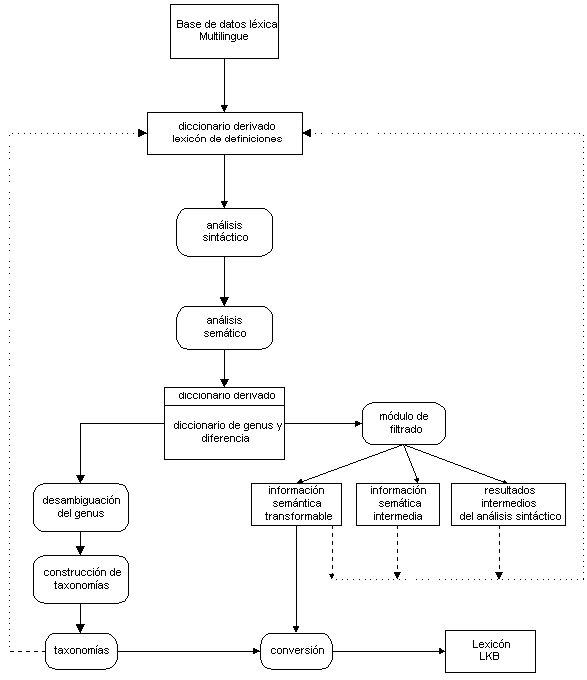
Tal y como se puede apreciar, los cuatro primeros pasos están relacionados con la extracción de conocimiento léxico, mientras que el cuarto concierne a la representación de dicha información.
En el proceso de conversión de los MRDs a LDB se implementó un diccionario con dos niveles diferentes, de manera que la información proveniente del diccionario fuente estaba separada de los códigos e índices que manejaban esta información. Se crearon dos tipos de índices: uno con los contenidos de cada uno de los campos de información relativos a cada entrada y otro basado en el contenido de las entradas, de manera que se pudiera acceder a ellas no sólo alfabéticamente, sino también a través de elementos relacionales comunes a varias entradas.
En lo que se refiere al proceso de extracción de información de las definiciones, se llevó a cabo un doble proceso. Primero se usaba una gramática genérica, que se había desarrollado especialmente para tratar el tipo de lenguaje utilizado en las definiciones, de manera que esta gramática ofrecía un análisis sintáctico preliminar de cada una de las definiciones. A continuación, una rutina de reconocimiento de patrones se encargaba de emparejar los patrones estructurales y/o léxicos con las descripciones sintácticas obtenidas anteriormente, con la intención de hacer explícita la información implícita en las definiciones. Este doble proceso se llevó a cabo en el LDOCE, IL NOUVO DIZIONARIO GARZANTI, en el diccionario español VOX y en algunos diccionarios de la editorial Van Dale.
No nos detendremos aquí a analizar las numerosas dificultades a los que hubo que hacer frente durante la aplicación de estos procedimientos a las definiciones de los diccionarios electrónicos19, aunque casi todas se derivan de los problemas que ya hemos señalado en el apartado anterior, y una de las soluciones que este proyecto aportó, el uso de varios diccionarios electrónicos, también trajo consigo bastante problemas de compatibilidad de los diferentes formatos (Briscoe 1991).
En resumen, los resultados obtenidos por la labor realizada por los miembros de las seis universidades integrantes en la primera fase del proyecto se plasmaron en la extracción (semi-)automática de definiciones en las que se había identificado el término usado como genérico ("genus") y la parte de la definición que correspondía a la diferencia específica, así como indicaciones de posibles relaciones entre las definiciones. Para que esta información les fuera de alguna utilidad, tanto en la creación de taxonomías como en su posterior volcado en la base de conocimiento léxico, debían antes desambiguar el significado de los términos genéricos usados en las definiciones.
Esto les llevaba, forzosamente, a la creación de un sistema de representación formal, que ellos denominaron "Lexical Representation Language" (LRL). Este lenguaje de representación está basado en la estructuras de rasgos tipificadas (TFS: Typed Feature Structure), cuya descripción detallada pospondremos hasta el apartado 4.4.1, enmarcándola en el ámbito general de la representación del conocimiento.
Este formalismo se basa en la utilización de estructuras de datos abstractas mediante pares atributo:valor, que se organizan en una jerarquía de tipos con herencia por defecto, y utilizando como mecanismo básico la unificación. Se trata en definitiva de una adaptación de un esquema de representación clásico como son las redes semánticas, y más concretamente los marcos (frames). Este tipo de esquema de representación es el que utilizaremos en el presente trabajo para la implementación de la ontología, por lo que también será descrito en detalle en el Capítulo 4. La distinción que en el proyecto Acquilex se hace entre LDB y LKB, está basada precisamente en que la segunda utiliza este tipo de esquemas de representación, considerados tradicionalmente como pertenecientes a las bases de conocimiento.
La Figura 2.1 resume los componentes del sistema de extracción de información usado por el grupo de investigadores de la Universidad y del Instituto de Lingüística Computacional de Pisa (Calzolari et al. 1993), en el que se puede apreciar la integración de las rutinas arriba mencionadas.
El desarrollo del formalismo de representación y la implementación de la LKB fueron los objetivos principales de la segunda fase del proyecto Acquilex. En esta fase, se desarrolló el LRL basado en TFS al que hacíamos alusión anteriormente, con la finalidad de representar formalmente la información léxica que se había extraído de los MRDs y que ya estaba contenida en las LDBs, creando así LKBs independientes para los cuatro idiomas estudiados en el proyecto (inglés, español, italiano y holandés). Se usó el mismo LRL para representar la información sintáctica y semántica de las entradas que conformaban cada una de las LKB. Posteriormente, esta información se tomó como base en la construcción de la MLKB (Multilingual Lexical Knowledge Base), cuya utilidad potencial estaba orientada a diversas aplicaciones de procesamiento de lenguaje natural, incluyendo, como veremos en el siguiente capítulo, la traducción automática.
Figura 2.1 El sistema de Acquilex para la extracción de conocimiento léxico
La Figura 2.2 es un ejemplo (parcial) de entrada léxica monolingüe tomada de la LKB inglesa (Copestake & Sanfilippo, 1993). Esta entrada contiene la información sintáctica y semántica extraída del LDOCE, asociada con sustantivo "chocolate" en su significado de "drinking chocolate":
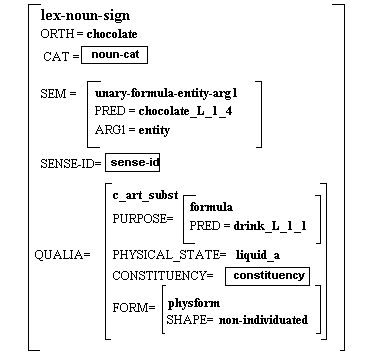
Figura 2.2 Ejemplo de entrada léxica monolingüe en Acquilex
Tal y como se puede apreciar en nuestro ejemplo, esta entrada léxica está representada por medio de una estructura de rasgos tipificada, de modo que lex-noun-sign se halla definido dentro de una jerarquía de "tipos", y este tipo concreto especifica las propiedades sintácticas y semánticas de los sustantivos. Los tipos están representados en negrita, los atributos en versales y los recuadros indican las partes de la estructura de rasgos que no aparecen completas, sino que refieren a información almacenada fuera de la entrada, a la que se puede acceder a voluntad. Por otra parte, drink_L_1_1 es el nombre de la entrada léxica de la que se "hereda" la información léxica detallada que aparece contenida en el atributo QUALIA. Por el momento, no creemos necesaria una descripción más profunda de este formalismo, ya que sólo estaremos en situación de mostrarlo correctamente después de haberlo enmarcado en el tipo de esquemas de representación en el que se encuadra.
El concepto de qualia está tomado del trabajo desarrollado por (Pustejovsky 1991, 1995) en su teoría léxico-semántica conocida como "Generative Lexicon". De los cuatro niveles de representación del significado léxico propuestos por Pustejovsky (argument structure, event structure, qualia structure y lexical inheritance structure), Acquilex II adaptó la estructura de qualia para hacer más específica la información léxico-semántica de los sustantivos, ya que éstos son descritos a través de cuatro roles o funciones (constitutive role, formal role, telic role y agentive role), junto con los posible valores que estas funciones pueden asumir. En este caso particular, la estructura de qualia aporta información sobre el estado físico y la forma del sustantivo "chocolate", además de heredar la información correspondiente a la entrada drink_L_1_1.
La función más importante de la qualia structure, en conjunción con la argument structure, es la de superar las limitaciones de las típicas restricciones de selección (Pustejovsky 1995).
Este lenguaje de representación usado en la descripción léxica también se usó en la descripción de las reglas gramaticales y léxicas, que son expresadas a través de estructuras de rasgos tipificadas que describen la relación entre dos o más signos lingüísticos.
Nuestra descripción del proyecto Acquilex no estaría completa sin hacer referencia a una de las aplicaciones de procesamiento de lenguaje natural que se implementó con la información contenida en las LKBs: la traducción automática basada en transferencia. Para facilitar nuestra exposición, pospondremos el análisis del sistema de traducción de Acquilex hasta el Capítulo 3, ya que en él trataremos en profundidad los diversos enfoques propuestos para la Traducción Automática y de este modo podremos analizarlo junto con otras alternativas ofrecidas.
NOTAS
Anterior I Siguiente I Índice capítulo 2 I Índice General