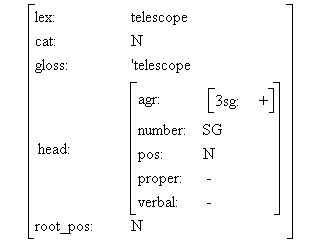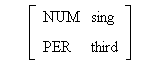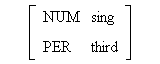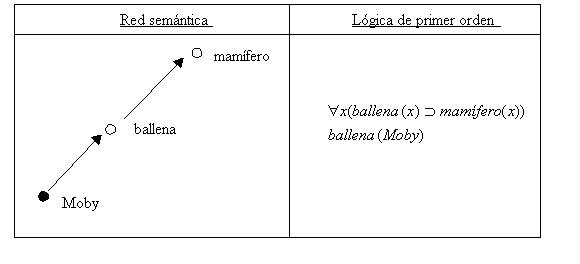
Figura 4.21 Herencia en red semántica y en lógica de prime orden
Como ya hemos adelantado, el denominador común a todos estos formalismos es la utilización de descripciones formales de las unidades gramaticales (palabras, frases, oraciones) por medio de conjuntos de pares atributo:valor, denominados genéricamente estructuras de rasgos (FS: Feature Structures). De hecho, las estructuras de rasgos se han convertido en el estándar de facto para las gramáticas de unificación (Carpenter 1991). La motivación para usar las estructuras de rasgos como formalismo de representación para los formalismos gramaticales basados en restricciones la encontramos claramente expuesta en Pollard & Sag (1987:7):
In all these formalisms and theories, linguistics objects are analysed in terms of partial information structures which mutually constrain possible collections of phonological structure, syntactic structure, semantic content and contextual factors in actual linguistic situations. Such objects are in essence data structures which specify values for attributes; their capability to bear information of non-trivial complexity arises from their potential for recursive embedding (...) and structure-sharing (...)
Los formalismos basados en rasgos se aplicaron con éxito por primera vez al problema del análisis en NLP, y en particular a las descripciones sintácticas del lenguaje, a finales de la década de los 50, para dar una respuesta a los problemas planteados por la subcategorización en las gramáticas de estructura de frase independiente del contexto. Mediante estos formalismos se han elaborado descripciones computacionalmente tratables de aspectos como la topicalización, cláusulas de relativo, complementación, concordancia, etc. (Shieber 1986; Pollard & Sag 1994). Las estructuras de rasgos poseen su propia semántica, por lo que son independientes de la implementación. Además, son declarativas, por lo que ofrecen una metodología eficiente y bien definida para describir los objetos lingüísticos. Las estructuras de rasgos resultan enormemente atractivas porque explotan la posible combinación de la flexibilidad de las redes semánticas con el poder expresivo y la capacidad de inferencia de la programación lógica. Carpenter & Thomason (1990) exponen esta interpretación lógica de una red semántica con el siguiente ejemplo:
Figura 4.21 Herencia en red semántica y en lógica de prime orden
Dicho de otra manera, esta combinación pretende suavizar las asperezas de ambos métodos de representación:
The calculi of symbolic logic were designed to account for mathematical reasoning, and as a result are expressively powerful, intractable, and rather distant from commonsense language and thought patterns. Networks are expressively weak, tractable, and tend to be closer to commonsense language and thought patterns.
(Carpenter & Thomason 1990:311)
Un gran atractivo de los formalismos basados en la unificación, es la habilidad, soportada por las estructuras de rasgos, de dar cabida a información parcial, lo que se conoce como subespecificación. Un ejemplo típico se refiere a la especificación de la concordancia sujeto-verbo; a la hora de escribir gramáticas, sería preferible no tener que especificar una regla para todas los rasgos que deben mantener valores compatibles (persona, número), sino tener una regla que dijese algo como: "el grupo de rasgos que representa la información de concordancia debe ser consistente con un grupo de rasgos correspondiente en el verbo, sin importar qué rasgos de concordancia son relevantes en esta lengua en particular." Este tipo de generalización puede expresarse y ser utilizada mediante la capacidad de herencia de las estructuras de rasgos.
Informalmente, una estructura de rasgos puede ser considerada como un conjunto de pares atributo:valor, donde los valores pueden ser atómicos o estructuras de rasgos (anidadas) y que son una especificación formal de palabras, afijos, frases, etc. Las operaciones básicas que se pueden efectuar sobre estas estructuras son las de unificación y herencia. La herencia permite representar la naturaleza jerárquica del léxico, haciendo posible que la información repetida a lo largo de determinados conjuntos de palabras sea expresada una sola vez (Pollard & Sag 1987).
Este mecanismo resulta especialmente útil en la representación de las propiedades de subcategorización de las entradas léxicas (Flickinger 1987), especialmente debido a su capacidad de recursividad. La unificación, por otra parte, es el mecanismo básico que permite integrar las especificaciones locales con las heredadas.
Formalmente, una estructura de rasgos es una tupla ![]() donde:
donde:
es una función de valor parcial
tal que cada nodo es alcanzable sólo desde la raíz. (Carpenter 1991, 1992).
La representación gráfica usual para las estructuras de rasgos es en forma de matrices atributo:valor (AVM: Attribute-Value Matrix), tal como la siguiente:
(1) |
|
Los atributos de una estructura de rasgos pueden tener bien valores atómicos o simples como los de (1). Pero también pueden ser valores complejos y contener estructuras anidadas de forma recursiva como en (2):
(2) |
|
donde el valor del atributo head es otra estructura de rasgos que a su vez puede contener otras estructuras anidadas.
Una forma alternativa de contemplar las estructuras de rasgos matemáticamente es en forma de grafos acíclicos dirigidos (DAG: Directed Acyclic Graph) (Gazdar & Mellish 1989), es decir, como máquinas de estados finitos. La Figura 4.22 ofrece dos representaciones gráficas equivalentes, la primera en forma de AVM y la segunda en forma de DAG.
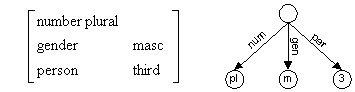
Figura 4.22 Representaciones AVM y DAG
El grafo de un DAG es "dirigido" porque los arcos tienen direcciones, indicadas por las flechas, y es "acíclico" porque no hay ciclos, es decir, no se puede ir de un nodo al mismo nodo siguiendo las flechas. Las dos estructuras indican lo mismo: una relación entre localizaciones y valores: en la AVM, los valores son slots de la matriz, mientras que en el DAG las localizaciones son nodos. Los valores de los slots ("plural, "masc", "third") de la AVM se pueden hacer corresponder con las etiquetas de los nodos, mientras que los nombres de los rasgos ("num", "gen", "per") se corresponderían con las etiquetas de los arcos del DAG. La representación mediante DAGs ha perdido terreno a favor de la presentación mediante AVMs, sobre todo por la adopción que de esta representación se ha hecho en uno de los formalismos gramaticales basados en unificación más extendidos, la HPSG.
Este tipo de representación no serviría de nada si no se pudiesen ejecutar operaciones sobre las estructuras. Las operaciones más importantes que hacen funcionar el sistema jerárquico de estructuras de rasgos son las de subsumpción y unificación. De las dos, la segunda es la que ha ejercido más influencia sobre el desarrollo de los formalismos gramaticales y del procesamiento del lenguaje natural (Gazdar & Mellish 1989). La operación de subsumpción se define de la siguiente manera:
Una categoría (o estructura) A subsume a otra
categoría B, escrito A ![]() B si y sólo si:
B si y sólo si:
Lo que es lo mismo que decir que una estructura de rasgos subsume a otra si la segunda contiene igual o más información que la primera y los valores para la información compartida son compatibles. Por ejemplo, (3)
(3) |
|
es más general que (o subsume) (4)
(4) |
|
(4) contiene más información que (3) y por tanto es menos parcial, imponiendo más restricciones y siendo capaz de describir menos objetos lingüísticos. De hecho, también decimos que una estructura B extiende a otra estructura A. En nuestro ejemplo (3) subsume a (4) y (4) extiende a (3).
La operación de unificación, aplicada a las estructuras de rasgos, toma dos estructuras y devuelve o bien un fallo, en caso de que las descripciones contengan información conflictiva, o bien otra estructura que combina la información de las dos estructuras de entrada. Siguiendo a Gazdar y Mellish (1989:231): "La unificación de dos categorías es la categoría más pequeña que extiende ambas, si tal categoría existe; de otro modo la unificación queda indefinida."
Por tanto la unificación de dos estructuras puede ser
considerada como la combinación de ambas. De este modo, se puede considerar esta
operación como algo parecido al operador lógico AND. Siguiendo con nuestro sencillo
ejemplo, (5) se unifica con (6) resultando en (7), escrito (5) ![]() (6) = (7):
(6) = (7):
(5) |
|
(6) |
|
(7) |
|
Como es lógico, los formalismos basados en la unificación hacen uso intensivo de esta operación, que es el mecanismo que permite la aplicación efectiva de la herencia de propiedades.
La unificación es, por otra parte, una seria desventaja en lo que respecta a la implementación, ya que resulta una operación muy costosa en términos de proceso. En muchos sistemas de análisis basados en unificación, esta operación acapara más del 80% del tiempo total de proceso (Akker et al. 1995:23).
En resumen, las características más importantes de las descripciones de rasgos son:
Anterior I Siguiente I Índice capítulo 4 I Índice General