| ISSN: 1139-8736 Depósito Legal: B-37271-2002 Copyright: © Silvia Montero Martínez |
3.4.4.6 Explanatory Combinatorial Dictionary
En 1970, Mel'cuk y Zolkovsky proponen por primera vez una teoría que se ha convertido en una de las más influyentes dentro de la lingüística comtemporánea. Este enfoque novedoso y radical en la clasificación del léxico que Mel'cuk y Zolkovsky (1984) llevan a cabo con el nombre de Meaning-Text Model, actualmente Meaning-Text Theory (MTT), tiene como finalidad hacer frente al problema de la falta de consistencia de los diccionarios (Faber y Mairal Usón 1999: 12).
El objetivo principal de la MTT es dar una explicación de cómo se materializan los significados en el texto. Se trata de una aproximación modular y estratificada en niveles que coinciden parcialmente con los niveles tradicionales de descripción y representación (semántico, sintáctico, morfológico y fonológico). Pero además, la sintaxis de la MTT está basada en la dependencia, es decir, la descripción de los verbos en el diccionario incluye un inventorio de los actantes relevantes y su materialización sintáctica, convirtiéndose en una interfaz sintáctico-semántica que además permitirá dar una descripción de las colocaciones que incorporará la clasificación semántica de las mismas (Heid 1994: 235).
Toda esta información léxica se codifica en el Explanatory Combinatorial Dictionary (ECD), una metodología lexicográfica desarrollada para la elaboración de diccionarios generales que introduce el concepto de función léxica (FL) (§3.4.1.1) para describir sistemáticamente ciertas relaciones semánticas y colocacionales que existen entre los lexemas (Heylen y Maxwell 1994: 300). Mel'cuk concibe, por tanto, el diccionario como un sistema de relaciones léxicas donde cada relación se ha de especificar. Esta "red relacional" actúa como un sistema de referencia interno a gran escala cuyas referencias cruzadas, estructuradas sistemáticamente, permiten al usuario saber qué entradas remiten a otras, cómo se relacionan y por qué (Frawley 1980/1981: 22).
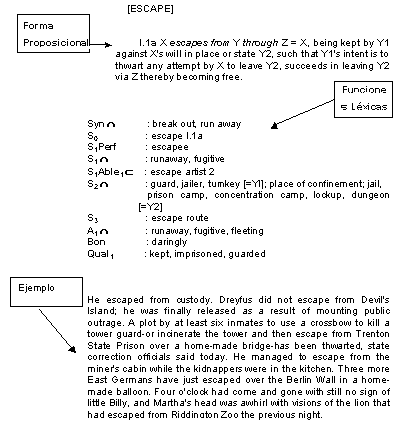
Según Elnitsky (1984) una entrada completa de un ECD cuenta, como mínimo, con el encabezamiento, la información morfológica, la definición y ejemplos que ilustren el significado y co-ocurrencias. Cada entrada se puede dividir por tanto en tres zonas: i) la semántica, en donde se da una definición analítica en forma proposicional; ii) la sintáctica, en la que se lleva a cabo la representación a través de fórmulas de las relaciones gramaticales pertinentes a una entrada; iii) la léxica, donde se recogen todas las asociaciones paradigmáticas y sintagmáticas de la entrada en forma de FL abstractas (Mel'cuk y Zholkovsky 1988: 42). Las primeras incluyen relaciones de sinonimia, antononimia, conversión, meronimia, etc., y las relaciones sintagmáticas conectan el lema de la entrada con su fraseología típica y ponen de manifiesto las relaciones contextuales. Podemos observar, por tanto, que a excepción de las FL, la información presentada sería la convencional en el marco de los diccionarios monolingües de lengua general:
[Elnitsky 1984]
Figura 3.39: Modelo de entrada en el ECD
A modo de resumen, Mel'cuk (1998: 50) afirma que las seis características formales de un ECD son las siguientes: i) es un diccionario teórico que se elabora dentro de un marco lingüístico coherente con un módulo semántico, uno sintáctico y uno morfológico y que pone gran énfasis en el lexicón; ii) es un diccionario activo en cuanto que está enfocado hacia la producción; iii) es un diccionario semántico basado en la representación semántica de todas las expresiones que contiene y donde la definición es una parte central de la entrada léxica; iv) es un diccionario combinatorio dado que se centra en la co-ocurrencia restringida (sintáctica y léxica); v) es un diccionario formalizado y se puede considerar como una base de datos léxica; vi) es un diccionario que pretende ser exhaustivo en cuanto a las UL, ya que su objetivo es una entrada léxica que incluya todo lo que un hablante nativo sabe sobre la unidad en cuestión.
Aunque Mel'cuk concibió este método para describir la lengua general, autores como Frawley (1980/1981) han sugerido que este modelo es el ideal para la compilación y elaboración de vocabularios de especialidad, ya que el formato del ECD asegura que toda la información relevante está incluida de forma ordenada consiguiéndose unos resultados sistemáticos y consistentes. Frawley (1980/1981:24) propone las siguientes FL para los diccionarios de especialidad: 'taxonomía', 'sinonimia', 'antonimia', 'gradación' (según la cual las relaciones de una entrada en particular han de estar explícitas siguiendo una ordenación determinada), 'causa', 'parte/todo', 'fuente' (cada entrada debe incluir otras entradas para las que es una fuente), 'resultado' y 'etimología'.
Somos conscientes del potencial que supone un enfoque sistemático a la hora de especificar las relaciones entre las entradas, ya que permitiría a los lexicógrafos y terminógrafos comprobar que toda la información relevante está presente y facilitaría a los usuarios el acceso a los términos relacionados. Sin embargo, a pesar de que este enfoque sea el subyacente en el ECD, el modelo de entrada que se propone plantea problemas de diversa índole. En primer lugar, la presentación es demasiado compleja para el procesamiento humano; la desventaja es la dificultad de comprensión del metalenguaje utilizado por lo que sería interesante profundizar en otras formas de representación que se adapten al usuario 43.
En segundo lugar, algunos afirman que las FL serían enormemente productivas en aplicaciones informáticas en las que serían compartidas por las representaciones semánticas de las colocaciones en las distintas lenguas (Wanner 1996, Tercedor Sánchez 1999) o también como sistema interlingüístico en aplicaciones de traducción automática. Sin embargo, no creemos que este mecanismo sea lo suficientemente refinado para un lexicón destinado al Procesamiento del Lenguaje Natural. Los que apoyan su utilidad asumen necesariamente que los aspectos más relevantes del significado de un colocado se encuentran recogidos en la FL, que por tanto será la que determine la exactitud de las traducciones. Sin embargo, el problema es el excesivo grado de generalidad que expresan las FL. La afirmación de que el significado del colocado se reduce en parte al significado que implica la FL no tendría problema si asumimos que las FL siempre contienen valores únicos pero observamos casos como el siguiente:
(64) Magn (oppose) = adamantly, bitterly...
La imprecisión implica que no tenemos forma de discriminar entre los distintos intensificadores posibles en el contexto de una palabra llave determinada y, por tanto, tampoco tenemos la información suficiente para elegir el equivalente correcto cuando existan múltiples posibilidades en la lengua meta.
En tercer lugar, si bien las relaciones que se establecen entr los términos por medio de las FL son productivas, aunque no accesibles desde la perspectiva del usuario final, creemos que las FL, al carecer de una estructuración conceptual base, son redundantes 44 y en ocasiones dejan información sin cubrir. Así, según Viegas et al. (1999: 3) "for NLP applications, it is not enough to have the relations between lexical items, especially from a multilingual perspective, and researches working in computational lexical semantics have added a conceptual layer in their lexicons".
Por otro lado, enumerar todas las FL estableciendo las interrelaciones entre todas las palabras, ya no sólo del lenguaje especializado sino del general, es una tarea ardua e innecesaria. Si bien las realizaciones de los términos/unidades fraseológicas en el discurso especializado son un reflejo de las relaciones conceptuales, no siempre dichas relaciones han de cristalizarse obligatoriamente en una entrada (García de Quesada 2001). Al establecer una estructura jerárquica, las propiedades, a veces en forma de relaciones, se heredan lo que hace que la formalización de todas las relaciones conceptuales posibles no sea necesaria.
En este sentido, las últimas aportaciones teóricas de Mel'cuk y Maxwell (1994: 331-337) hacen referencia a la posibilidad de implementar la herencia léxica en un ECD evitando la redundancia. Se trataría de delimitar el dominio semántico determinando el lexema genérico e introduciendo las dimensiones semánticas capaces de recoger los rasgos semánticos comunes. Así, una vez extraídos estos rasgos comunes a partir de los valores de las FL que aparecen en las entradas de los lexemas específicos, se transferirían a la entrada léxica del lexema genérico. Cada elemento transferido se completaría con información semántica que justifique su uso con el lexema específico del que se ha extraído y los valores de las FL que se enumeran en la entrada del lexema genérico se heredarían por todos los lexemas que se encuentren bajo las dimensiones semánticas. Al mismo tiempo, todas las excepciones se recogerían explícitamente en las entradas individuales. Para ello, es necesario reorganizar la entrada léxica del lexema genérico dividiéndola en dos partes: su propia entrada léxica (que describe su sintaxis y coocurrencia) y que se denomina subentrada privada y la subentrada para los rasgos comunes extraidos -la subentrada pública. Mel'cuk (1996: 78) recoge el ejemplo del sustantivo 'cancer' que tiene las FL 'Oper1 = [to suffer [from ~]', 'Real1 = [to] succumb [to ~]', 'AntiReal1 = [to ] win [over one's ~]', etc. Estas mismas FL las tienen los nombres de todas las enfermedades: 'John suffered from TUBERCULOSIS', 'succumbed to AIDS', 'won over his PNEUMONIA'. Por lo tanto, estas FL no se deberían repetir en las entradas individuales de las enfermedades, sino juntar en la subentrada pública del lexema DISEASE, que sería el lexema genérico del dominio semántico de las enfermedades.
En definitiva, aunque este modelo de representación supuso un avance en la lexicografía, es evidente la dificultad de su aplicación a gran escala porque, entre otras cosas, es excesivamente teórico y formalista (Liang 1991-1992; Piotrowski 1990); es fácil concluir que en la creación de un diccionario Mel'cuk da prioridad a la teoría lingüística y lexicográfica antes que a la accesibilidad para el usuario final. En nuestro caso particular, además, hay que tener en cuenta que no ofrece ninguna información sobre la motivación que impulsa la elección de un colocado específico para una determinada base, cuestión de interés para este trabajo que parte de la idea de que es posible predecir los patrones colocacionales utilizando información conceptual adicional y las relaciones predicativas de dependencia (Capítulo 5).
Pero a pesar de todos estos problemas, no se puede negar la influencia que ha tenido la MTT tanto en la teoría colocacional como en el panorama lexicográfico en general.
Notas
43 Cohen (1986) lleva a cabo esta idea en un diccionario de economía y bolsa (§3.5.3.1).
44 En la actualidad, un ECD describe la coocurrencia léxica restringida al especificar para cada lexema L todos los valores de todas las FL aplicables en su entrada. Se ignora la posible correlación entre significado/coocurrencia y la redundancia que se puede generar (Mel'cuk y Wanner 1994: 329).
Índice general I Índice Capítulo 3 I Siguiente
| ISSN: 1139-8736 Depósito Legal: B-37271-2002 Copyright: © Silvia Montero Martínez |