ISSN: 1139-8736
Depósito Legal: B-35510-2000
2.2 El lexicón en el procesamiento de lenguaje natural: la
lexicografía computacional
En este apartado centraremos nuestra atención en la visión computacional del concepto
de lexicón, es decir, en los lexicones computacionales. Tal y como apuntábamos en la
introducción de este capítulo, los lexicones se consideran hoy día la base fundamental
en la construcción de sistemas computacionales que posibiliten la interacción entre la
máquina y el hombre.
Todas las aplicaciones que tienen como objeto el tratamiento
computacional del lenguaje natural consideran el lexicón como componente central, lo que
ha provocado una demanda constante de información léxica detallada sobre amplias áreas
de vocabulario. La finalidad fundamental del procesamiento de lenguaje natural es la
automatización de los procesos lingüísticos, tales como la comprensión, producción o
adquisición de una lengua, tareas que los usuarios de una lengua realizan fluida y
naturalmente. Tanto para los humanos como para las máquinas, todas estas tareas implican
un conocimiento profundo del vocabulario de una lengua aunque, tal y como señala Boguraev
(1991a:3), durante años los lexicones
enfocados al procesamiento del lenguaje natural han sido los "hermanos pobres"
de la lingüística computacional.
La mayoría de los sistemas diseñados hasta hace
relativamente poco tiempo contenían sólo lexicones ilustrativos con no más de cien
palabras4, y a pesar de los numerosos avances en este
área, aún hoy no existe consenso sobre la naturaleza de la información que el lexicón
debe contener ni, por supuesto, sobre la manera en la que la información debe ser
representada. La tarea de construir un lexicón completo para una lengua natural es
enorme. El Oxford English Dictionary (OED), por ejemplo, contiene 250.000 entradas
de palabras independientes, y a pesar de tan elevado número, no incluye muchas palabras
pertenecientes al vocabulario técnico.
Resulta por tanto muy costoso, tanto en recursos humanos como
en tiempo y dinero, construir un lexicón "a mano", lo que ha llevado a muchos
investigadores a considerar las versiones electrónicas de los diccionarios impresos como
fuentes potenciales de información léxica, que puede ser vertida de forma automática o
semi-automática en sistemas de procesamiento de lenguaje natural. En el apartado
2.3 nos ocuparemos de esta línea de investigación, analizando las ventajas y
desventajas que plantea el uso de diccionarios electrónicos como fuente de información
léxica para la creación de lexicones computacionales.
El ámbito de investigación del procesamiento del lenguaje
natural, que tal y como decíamos antes, tiene como finalidad la automatización de los
procesos lingüísticos, hace converger los intereses de lingüistas computacionales,
psicolingüistas, informáticos e ingenieros de sistemas. Todos ellos, desde diferentes
perspectivas teóricas y prácticas, intentan desarrollar una teoría que sea totalmente
explícita (y por tanto automatizable) de los procesos lingüísticos.
Aunque hasta la fecha no existe una teoría completa, no
debemos olvidar que hay bastantes ejemplos de sistemas de NLP que han sido construidos
sobre la base de un entendimiento parcial de algunos de esos procesos. Se han construido,
por ejemplo, sistemas de síntesis hablada de textos (text-to-speech-synthesisers);
estos sistemas no intentan "entender" el input, sino que se apoyan en un
análisis lingüístico superficial de las palabras que conforman el texto y en su
organización sintáctica en oraciones. También se han conseguido sistemas de
reconocimiento de habla que convierten una cadena de habla en su correspondiente escrito
con bastante exactitud.
Bastante menos, sin embargo, se ha avanzado en las áreas de
generación o comprensión del lenguaje, aunque hay un gran número de proyectos de
investigación dedicados a ello. La mayoría de los sistemas de procesamiento de lenguaje
natural adoptan un enfoque que se ha dado en llamar "basado en el conocimiento"
(knowledge-based)5, ya que para llevar a cabo la
tarea para la que están diseñados, necesitan incorporar conocimiento lingüístico
explícito, junto con otros tipos de conocimiento de carácter más general. Por ejemplo,
un sistema de síntesis que convierta un texto en su correspondiente cadena hablada,
necesita "conocimiento" sobre la pronunciación de las letras y las secuencias
de letras, así como de las palabras individuales que no siguen las reglas generales.
También precisa conocimiento sobre los patrones rítmicos de acentuación y de cómo la
organización sintáctica afecta la prosodia y la entonación. Sin esta información el
sistema no podría sintetizar el texto correctamente.
Hablando en términos generales, se pueden identificar al
menos cinco tipos de conocimiento que son relevantes en cualquier sistema de procesamiento
de lenguaje natural, y el hecho de que la mayoría de este conocimiento sea almacenado en
el lexicón hace de él el eje central de cualquier sistema de NLP6:
- Conocimiento fonológico:
información sobre el sistema de sonidos y la estructura
de las palabras y las expresiones, los patrones de acentuación, la entonación, etc.
- Conocimiento morfológico:
información sobre la estructura de las palabras; por
ejemplo, que los fonemas /s/ y /z/ se añaden en inglés a los nombres para formar el
plural.
- Conocimiento sintáctico:
información sobre la organización de las palabras en
frases y oraciones; por ejemplo, el cambio en el orden de las palabras en inglés para
formar oraciones interrogativas, en el que se invierte el sujeto y el verbo auxiliar, etc.
- Conocimiento semántico:
información sobre el significado de las palabras y de
cómo esos significados se combinan para formar el significado de las oraciones; por
ejemplo, que el concepto denotado por pegar implica dos entidades: un agente (el
que pega) y un paciente (la persona o cosa a la que el agente pega), y que esas entidades
estarán representadas, correspondientemente, en el sujeto y el objeto del verbo.
- Conocimiento pragmático:
información que puede ser considerada como central en
muchas tareas específicas que sistemas de procesamiento de lenguaje natural han de
realizar, por ejemplo, la recuperación de los referentes de los pronombres o de las
oraciones elípticas, el análisis de las presuposiciones del hablante, o de las
intenciones comunicativas que subyacen en una frase en particular. Casi todas estas tareas
implican información sobre la intención y la disposición de los interlocutores, sobre
el contexto extralingüístico, etc.
Cada uno de estos cinco tipos (generales) de conocimiento
puede ser caracterizado por medio de un conjunto de reglas. Por ejemplo, es una regla de
tipo sintáctico en inglés que los adjetivos aparezcan siguiendo al verbo to be y
precediendo al nombre en las frases nominales:
Ej. That house is beautiful That beautiful house
Sin embargo, esta regla no se puede aplicar en el caso de un
adjetivo como por ejemplo "lone":
Ej.: That lone house *That house is lone
Este tipo de particularidades deben hacerse explícitas en el
lexicón. En este caso, es necesario representar el hecho de que un grupo de adjetivos no
pueden ser usados como atributos (en inglés, a esta posición se la conoce
tradicionalmente como "predicative position"). Si no podemos encontrar
una regla general que identifique a los miembros de este grupo, habrá que marcar a cada
miembro con un rasgo, como por ejemplo "non-predicative", y restringir de
este modo la aplicación de la regla sintáctica a los adjetivos que no estén marcados
con ese rasgo.
Este tipo de reglas sintácticas se pueden representar en la
forma de reglas de estructura de frase (phrase structure rules), que tienen la
siguiente forma genérica:
Mother  Daughteri, Daugherj ....... Daughtern
Daughteri, Daugherj ....... Daughtern
en la que la categoría sintáctica "madre" puede contener una o más
categorías "hija" y las categorías consisten en un nombre con algunos rasgos
sintácticos opcionales. Una gramática escrita con esta notación que sólo genere
ejemplos gramaticalmente correctos sería:
- S NP VP
- VP V AP[prd +]
- NP Det N
- NP Det AP[prd
x] N
- AP[prd x] A
[prd x]
|
En estas reglas se especifica que una oración (S)
está formada por una frase nominal (NP) y una frase verbal (VP),
y que una frase verbal, a su vez, puede estar formada por un verbo y una frase adjetiva (AP)
marcada como [prd +]. El rasgo [prd] tiene dos valores (- / +) y
se usa para indicar si una categoría adjetiva puede o no aparecer como atributo. Las
reglas 3 y 4 especifican que una frase nominal está formada por un determinante (Det)
y un nombre (N), con una frase adjetiva que puede aparecer opcionalmente.
Este frase adjetiva está marcada como [prd x], donde x es una variable que
representa los posibles valores de este rasgo. La última regla especifica que una frase
adjetiva está formada por un adjetivo con valor [prd] que ha de ser
idéntico al de la frase adjetiva.
Tal y como veremos con más detalle en el siguiente
capítulo, al proceso de aplicar una gramática a una oración para determinar si es
gramaticalmente correcta o no se le conoce como análisis sintáctico (parsing).
Sin embargo, para aplicar esta gramática de forma mecánica y automatizada a una
oración, es necesario contar con un lexicón que ofrezca información al analizador
sintáctico (parser) sobre las categoría gramaticales que están asociadas a las
palabras que aparecen en la oración que se desea analizar. Siguiendo con nuestro ejemplo
anterior, un lexicón (incompleto, por supuesto) para nuestra oración sería:
beautiful : A [prd+], A [prd-]
house : N
is : V
lone : A [prd -]
that : Det
El proceso de análisis sintáctico sería el siguiente:
- Para cada una de las palabras del lexicón, se consulta el lexicón y se le asigna una
categoría sintáctica.
- Se intenta hacer corresponder las reglas que contienen categorías léxicas
"hijas" explícitas con las categorías léxicas de las palabras de la oración,
yendo de izquierda a derecha. Después, las categorías madre se relacionan con las hijas
tal y como se especifica en cada regla.
- Se construye un árbol de representación con un nodo raíz S (oración) llenando los
huecos con más reglas que conectan las demás categorías.
Por ejemplo, el primer paso en el análisis de la siguiente
oración:
That lone house is beautiful
sería:
Det
|
That |
A[prd-]
|
lone |
N
|
house |
V
|
is |
A[prd+]
|
beautiful |
El segundo paso nos daría el siguiente árbol parcial:
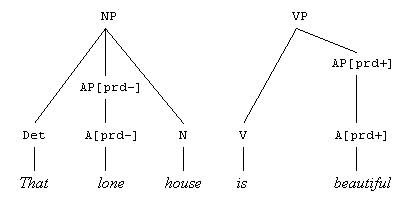
En este caso, el valor variable [prdX] contenido
en la regla 5 se ha asignado a un adjetivo (beautiful) que puede actuar con dos
valores, aunque en este caso se ha seleccionado el valor [prd+]. Si se
hubiera seleccionado el valor [prd-] de nuestro pequeño lexicón, la regla
número 2 no hubiera correspondido con el valor asignado, y el proceso de parsing debería
volver a realizarse.
El tercer paso añadiría el nodo S (oración), asignando
así la regla nº 1:
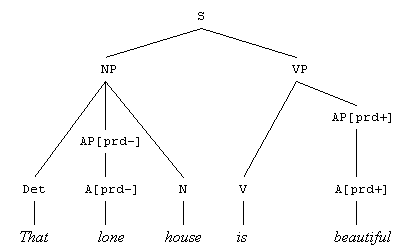
En el Capítulo 3 trataremos con más
detalle el proceso de parsing y los distintos métodos de análisis propuestos,
así como una caracterización más adecuada de las gramáticas de estructura de frase o
gramáticas sintagmáticas. Hemos querido ofrecer aquí este ejemplo como muestra de la
interacción necesaria entre las reglas (gramática) y el lexicón. En nuestro ejemplo, el
lexicón se adaptaba a la gramática que habíamos diseñado, pero ambos tendrían que ser
extendidos cada vez que se introdujeran reglas nuevas en la gramática o se añadieran
palabras al lexicón. Si añadimos, por ejemplo, un verbo no copulativo, como hate,
necesitaríamos hacer una distinción entre diferentes tipos de verbos, tanto en la
gramática como en el lexicón, para evitar que se generen oraciones incorrectas como por
ejemplo:
* That lone house hates beautiful
Esto demuestra la necesidad de que en cualquier sistema de
procesamiento de lenguaje natural exista una gran interconexión entre las reglas
generales que se incorporan a la gramática y la información incluida en las entradas del
lexicón, ya que el lexicón deberá aportar toda la información que no sea predecible de
las reglas, y deberá "rellenar" estas reglas de modo que funcionen
correctamente.
El lexicón también ha de incluir otros tipos de
información idiosincrásica o no derivable de reglas, como por ejemplo, en el caso del
inglés, la pronunciación, que se considera normalmente como un aspecto lingüístico que
no se puede derivar del significado de las palabras o de su forma morfológica.
El significado de las palabras tampoco parece ser derivable
de reglas generales, por lo que debe ser definido para cada entrada léxica, aunque en
ciertos casos se puedan hacer consideraciones morfológicas; por ejemplo, el significado
del verbo think no es predecible, pero el de rethink puede serlo, a través
de una regla morfológica que combine el significado del prefijo –re con el
significado de think7 (lo que podríamos glosar
como "to think again"). Consideraciones de este tipo indican que el
conocimiento morfológico debe estar también integrado en el lexicón.
Un lexicón válido para tareas de procesamiento de lenguaje
natural ha de contener, por tanto, información fonológica, morfológica, sintáctica,
semántica y pragmática, pero además esta información debe ser estructurada de forma
que permita su reutilización para diversas tareas. En este sentido, los conceptos de
"atomicidad" e "independencia de los datos" necesitan ser expuestos,
por lo que pospondremos esta discusión hasta el Capítulo 4.
Volveremos sobre la cuestión del contenido de una entrada
léxica en las secciones siguientes, pero antes debemos hacer una serie de
puntualizaciones de carácter terminológico.
Se pueden distinguir dos grandes ámbitos de investigación
en lo referente a los lexicones computacionales: el de la adquisición y el
de representación de conocimiento léxico. Nos ocuparemos de la
adquisición de conocimiento léxico en el apartado 2.3, y en él
veremos los recursos y métodos que se han empleado con mayor frecuencia para obtener de
modo automático o semi-automático los tipos de información que ha de popular un
lexicón computacional a los que hacíamos referencia más arriba. La cuestión de la
representación del conocimiento léxico la abordaremos en el apartado
2.4.
Otra puntualización es necesaria en referencia a los
términos información y conocimiento: los hemos usado como
sinónimos en este capítulo, aunque el significado preciso de cada uno de estos términos
se definirá formalmente en el Capítulo 4, mostrando las
características y peculiaridades de cada uno de estos sistemas, tanto de forma genérica
como específica. Por el momento, cuando hablemos de base de datos o base de conocimiento
podemos pensar en el concepto más abstracto que los engloba a todos: "sistema de
información".
Los términos knowledge (data)base, lexical data base,
lexical base, lexical knowledge base, también se han usado como sinónimos
en este capítulo, siguiendo la tónica general de las publicaciones internacionales que
tratan de este tema. Casi todos los autores los usan indistintamente, y en caso de
definirlos, ofrecen definiciones bastante vagas o genéricas. Para terminar esta sección
nos gustaría destacar la definición que Boguraev & Pustejovsky (1996:9), ofrecen en su
reciente libro dedicado a los avances en la construcción de lexicones computacionales:
(...) the term "lexical knowledge base" has become a
widely accepted one. Researchers use it to refer to a large-scale repository of lexical
information, which incorporates more than just static descriptions of words, e.g., by
means of clusters of properties and associated values. A lexical knowledge base would
state
- constraints on word behaviour
- dependence of word interpretation on context, and
- distribution of linguistic generalisations
It is essentially a dynamic object, as it incorporates, in addition to its information
types, the ability to perform inference over them and thus induce word meaning in context.
This is the sense of "computational lexicon", the population of which is giving
new meaning to lexical acquisition from MRDs...
Muchas de los conceptos que se mencionan en esta definición,
como los de "objetos dinámicos" y "restricciones" serán abordados en
el Capítulo 4, en el que ofreceremos una panorámica de las
técnicas de representación, tanto del conocimiento en general, como del conocimiento
léxico.
NOTAS
- Hecho que en la mayoría de los casos no se hacía explícito en informes, libros o
tesis publicadas. Una anécdota relatada en Wilks et al. (1996:2)
refleja esta situación con bastante precisión: hace cinco años, se le preguntó a un
grupo de investigadores del campo de NLP cuál era realmente el número de palabras
contenidas en los lexicones de sus sistemas. La media de estas respuestas fue de 36, una
cifra, en palabras de los autores, "often taken to be a misprint when it appears,
though it was all too true...".
- En este ámbito, el término "conocimiento" se utiliza de
una manera muy imprecisa. En el Capítulo 4 intentaremos perfilar
una definición más concreta del mismo, en comparación a los términos relacionados de
"información" y "datos". Por otra parte, como veremos en el capítulo
siguiente, el calificativo de "knowledge-based" se refiere, en el ámbito de la
Traducción Automática a un tipo muy específico de sistemas. Por el momento,
mantendremos este significado vago e impreciso del término que se ha venido utilizando en
el campo de la lexicografía computacional durante mucho tiempo.
- Desarrollaremos esta afirmación en el Capítulo 3
en referencia a la TA y en el Capítulo 4 en cuanto a la
representación de conocimiento léxico.
- En otros casos, este tipo de regla morfológica para derivar
significados no sería productiva como por ejemplo con los verbos recall o represent,
cuyos significados no se corresponden con "to call again" o "to
present again".
Anterior
I
Siguiente
I
Índice capítulo 2
I
Índice General