| ISSN: 1139-8736 Depósito Legal: B-39200-99 |
3. El Diccionario Electrónico Fonético del Español.
El DEFE no es un trabajo aislado, forma parte de un proyecto de investigación cuyo objetivo es crear bases de conocimiento lingüístico, de acuerdo a determinados presupuestos; lo describiremos en este capítulo. También describiremos el sistema de fonetización del que partimos y su adaptación para adecuarlo a nuestros objetivos. Destinamos el resto del capítulo a mostrar los aspectos formales y de contenido del DEFE; concretamente, la información lingüística necesaria para generarlo, el modelo de pronunciación que transcribimos, el repertorio de signos fonéticos utilizados y los criterios en los que nos hemos basado para su elección.
El DEFE se integra en un proyecto general más amplio, desarrollado en el Laboratorio de Lingüística Informática (LaLI) del Departamento de Filología Española de la Universidad Autónoma de Barcelona bajo la dirección del profesor Carlos Subirats con financiación pública1: la creación de una Base de Conocimiento Lingüístico, cuyo objetivo es la descripción sistemática de la lengua a través de la construcción de una gramática léxica. Este proyecto se fundamenta en los trabajos de Subirats (1997; en prensa, a; en prensa, b; en prensa, c), que desarrollan el modelo de gramática de predicados de Harris (1982 y 1991) (cf. Leclere y Subirats, 1991; Subirats, en preparación). Para este modelo, el estudio de la gramática no puede separarse del estudio del léxico; se trataría de una disociación arbitraria dada la complejidad que presenta la distribución de las propiedades formales en las unidades léxicas. Dicha complejidad aumenta a medida que crece el número de elementos estudiados, de ahí que la gramática léxica parta del principio de que no existen dos palabras que posean las mismas propiedades formales y rechace el concepto de regla ligado a un valor explicativo o regularizador; las reglas han de constituir un medio para caracterizar formalmente cada una de las unidades léxicas de la lengua. Además, la aplicación de una regla gramatical está condicionada por las propiedades idiosincrásicas de los elementos léxicos individuales, por lo que no es posible establecer una distinción radical entre las reglas y sus condiciones de aplicación: dichas condiciones han de formar parte del estudio mismo de las reglas. Por tanto, "una descripción lingüística sistemática" no sólo ha de entenderse como la enumeración estructurada de las reglas gramaticales que definen una lengua, sino también como la representación exacta de las unidades del léxico en las que se aplican; de este modo, la gramática léxica constituye una representación sistemática del conocimiento lingüístico del hablante.
La estructura de la Base de Conocimiento Lingüístico refleja esa concepción del estudio de la lengua. Está integrada por una Base de Conocimiento Léxico y una Base de Conocimiento Sintáctico-Semántico interrelacionadas. Por Base de Conocimiento Léxico se entiende una base de datos lingüísticos, organizados en diccionarios, y las aplicaciones que permiten su tratamiento. Las unidades que forman los diccionarios de la Base de Conocimiento Léxico se clasifican en predicados y argumentos. Predicados son aquellas categorías sintácticas que seleccionan determinados argumentos para aparecer en una oración (nombres y adjetivos predicativos, verbos y preposiciones); argumentos son aquellas categorías seleccionadas por los predicados. En la Base de Conocimiento Sintáctico-Semántico se especifican las propiedades de selección, el significado y las transformaciones de las unidades contenidas en los diccionarios.
La Base de Conocimiento Léxico está formada por el siguiente conjunto de diccionarios (cf. Subirats 1989, 1992a, 1992b, 1994, 1995):
(1) El Diccionario Electrónico de Formas Simples del Español (DEFSE).
Consiste en una lista alfabética de 68.000 entradas que constituyen el léxico general de la lengua española; un léxico, tanto de uso común como culto. Se incluyen algunos extranjerismos de uso actual en el español, aunque sin dejar de tener presente que es un sector fluctuante del léxico, por ejemplo: leasing, jeep, input, output, etc.
Las formas simples contenidas en el DEFSE son palabras entendidas como cadenas de caracteres entre dos espacios en blancos consecutivos, por lo que presentan diversa complejidad formal: pueden ser morfológicamente no analizables, como flor, feliz, allí, y morfológicamente analizables, ya sean palabras formadas por derivación, como intransitividad, empobrecimiento, deshabituación, o por composición, como chupatintas, quitaipón, correveidile. También forman parte de este diccionario palabras que nunca aparecen libres, sino integrando formas compuestas, como tiquis y miquis (ejemplos de Subirats, 1989: 179). La selección de entradas del DEFSE sigue criterios estrictamente formales.
El DEFSE está lematizado siguiendo la tradición lexicográfica, es decir, las palabras que presentan paradigmas flexivos están citadas por una forma canónica de base:
(a) los verbos, por la forma de infinitivo;
(b) los nombres y adjetivos con variación de género y número, por la forma de masculino singular;
(c) los nombres y adjetivos sin variación de género o número, por la forma que presentan por defecto.
Todas las entradas del DEFSE llevan asociada una información gramatical mediante una codificación alfanumérica que especifica la categoría a la que pertenece el elemento léxico y sus propiedades flexivas. También consta, entre llaves, la fuente de documentación de la palabra y –cuando se ha considerado necesario, por ser especializado– el campo del saber; a estas informaciones adicionales no tienen acceso las aplicaciones informáticas.
Tabla 1. Ejemplos del DEFSE.
|
|
(2) El Diccionario Electrónico de Formas Simples Flexivas del Español (DEFSFE).
Este diccionario contiene todas las formas flexivas de las palabras contenidas en el Diccionario de Formas Simples (557.000). Estas formas flexivas están generadas automáticamente a través de una aplicación de flexión verbal, nominal y adjetiva que añade a la forma de base el paradigma que corresponda a la codificación alfanumérica de las entradas del DEFSE. Siguiendo la distinción mencionada por Lyons (1971: 69-70 y 203-205), las palabras representadas en el DEFSE son lexemas: unidades invariantes subyacentes consideradas por abstracción de sus propiedades accidentales, mientras que las representadas en el DEFSFE son palabras gramaticales, las variantes formales que adoptan los lexemas en virtud de las reglas sintácticas que generan las oraciones. En los siguientes ejemplos podemos observar la información contenida en las entradas del DEFSFE: se indica la forma de base a partir de la cual se ha generado la palabra, la categoría gramatical y las propiedades flexivas de la forma de base, así como la forma flexiva a la que corresponde la palabra.
Tabla 2. Ejemplos del DEFSFE.
|
|
(3) El Diccionario Electrónico de Formas Compuestas del Español (DEFCE).
Está formado por 26.000 compuestos sintagmáticos de la lengua española, formas como brazo de gitano, molino de viento y paquete bomba (nombres compuestos); en funciones, de sangre azul y largo de lengua (adjetivos compuestos); de vez en cuando, a sabiendas y sin decir esta boca es mía (adverbios compuestos); acerca de y en contra de (preposiciones compuestas); qué demonios y cielo santo (interjecciones compuestas). Todos los componentes de las formas compuestas están incluidos en el DEFSE. Las entradas del DEFCE también están codificadas alfanuméricamente: se indican las propiedades flexivas de las formas simples que experimentan variaciones de forma en la flexión del compuesto, con el mismo código alfanumérico que tienen en el DEFSE, y, en las entradas nominales, la estructura de la forma compuesta y sus propiedades flexivas (éstas no siempre pueden deducirse de las propiedades de los componentes). Como información adicional, codificada entre llaves, a la que no acceden las aplicaciones informáticas, consta la fuente de documentación y, cuando se ha considerado necesario, ejemplos de uso, definiciones y campo del saber.
Tabla 3. Ejemplos del DEFCE.
Diccionario Electrónico de Formas Compuestas del Español |
labor(N23A)/blanca(A47),.NA:f {MM;"labor de cocido..."} labor(N23A)/de//aguja,.NDN:f {MM;"bordado"} labor(N23A)/de//costura,.NDN:f {MM} labor(N23A)/de//ganchillo,.NDN:f {MM} labor(N23A)/de//punto,.NDN:f {PERS;"confección de tejidos de punto"} labor(N23A)/de/punto/de/media,.NX:f {MM} labor(N23A)/social(A63A),.NA:f {PERS;ej.:'esta oganización internacional de ayuda a los marginados esta recaudando fondos para financiar su importante labor social'} laboratorio(N1)/de//análisis,.NDN:m {SPIN} laboratorio(N1)/de//control,.NDN:m {SPIN} laboratorio(N1)/de//ensayo,.NDN:m {SPIN} laboratorio(N1)/de//fotografía,.NDN:m {PERS} laboratorio(N1)/de//investigación,.NDN:m {SPIN} laboratorio(N1)/de//pruebas,.NDN:m {PERS;ej.:'esta gran ciudad fue el laboratorio de pruebas donde se ensayaron por primera vez medidas de protección civil para hacer frente a los ataques aéreos contra el núcleo urbano'} laboratorio(N1)/de/investigación/y/desarrollo,.NX:m {SPIN}
|
(4) El Diccionario Electrónico de Formas Compuestas Flexivas del Español (DEFCFE).
Este diccionario contiene todas las formas flexivas de las palabras contenidas en el DEFCE, un total de 50.000 entradas. Se genera mediante una aplicación de flexión que añade a la forma de base el paradigma que corresponda a la codificación alfanumérica que consta en el diccionario de formas compuestas. Entre las palabras que aparezcan representadas en el DEFCE y en el DEFCFE existe la misma relación de "lexemas/palabras gramaticales" que hemos señalado para las formas simples del DEFSE y el DEFSFE. En las entradas del DEFCFE se indica la forma de base a partir de la cual se ha generado la palabra, la categoría gramatical y la forma flexiva a la que corresponda.
Tabla 4. Ejemplos del DEFCFE.
Diccionario Electrónico de Formas Compuestas Flexivas del Español |
laboratorios/fotográficos,laboratorio/fotográfico.N:mp laboratorios/móviles,laboratorio/móvil.N:mp laboratorios/orbitales,laboratorio/orbital.N:mp laboratorios/orbitales/tripulados,laboratorio/orbital/tripulado.N:mp labores/agrícolas,labores/agrícolas.N:fp labores/blancas,labor/blanca.N:fp labores/de/aguja,labor/de/aguja.N:fp labores/de/costura,labor/de/costura.N:fp labores/de/ganchillo,labor/de/ganchillo.N:fp labores/de/punto,labor/de/punto.N:fp labores/de/punto/de/media,labor/de/punto/de/media.N:fp labores/domésticas,labores/domésticas.N:fp labores/sociales,labor/social.N:fp laca/de/uñas,laca/de/uñas.N:fs lacas/de/uñas,laca/de/uñas.N:fp lado/oscuro,lado/oscuro.N:ms lados/oscuros,lado/oscuro.N:mp lagarto/de/Indias,lagarto/de/Indias.N:ms lagartos/de/Indias,lagarto/de/Indias.N:mp lago/artificial,lago/artificial.N:ms lago/de/leones,lago/de/leones.N:ms lagos/artificiales,lago/artificial.N:mp lagos/de/leones,lago/de/leones.N:mp lágrima/de/Batavia,lágrima/de/Batavia.N:fs lágrima/de/cocodrilo,lágrima/de/cocodrilo.N:fs lágrima/de/Holanda,lágrima/de/Holanda.N:fs lágrimas/de/Batavia,lágrima/de/Batavia.N:fp lágrimas/de/cocodrilo,lágrimas/de/cocodrilo.N:fp,lágrima/de/cocodrilo.N:fp lágrimas/de/David,lágrimas/de/David.N:fp lágrimas/de/Holanda,lágrima/de/Holanda.N:fp lágrimas/de/Job,lágrimas/de/Job.N:fp laguna/legal,laguna/legal.N:fs lagunas/legales,laguna/legal.N:fp lámina/metálica,lámina/metálica.N:fs laminación/de/metales,laminación/de/metales.N:fs laminaciones/de/metales,laminación/de/metales.N:fp |
A este conjunto de cuatro diccionarios, que representan el léxico del español en caracteres ortográficos, se añade el DEFE, objeto de nuestro trabajo, que consistirá en una representación en caracteres fonéticos del conjunto de palabras contenidas en el Diccionario Electrónico de Formas Simples Flexivas del Español. Desde el punto de vista formal, la transcripción fonética del DEFE se añade, en un campo específico, a la información gramatical y flexiva que contienen las estradas del DEFSFE; de hecho, el DEFE constituye el Diccionario Electrónico de Formas Simples Flexivas del Español_Fonético (DEFSFE_FON).
Con el DEFE se completa la representación del léxico del español, ya que indica la forma fonológica de sus unidades, su pronunciación. Este diccionario se genera mediante la aplicación de un sistema de transcripción fonética automática.
Tabla 5. Ejemplos del DEFE.
Diccionario Electrónico Fonético del Español |
|
3.2. El sistema Laporte para la fonetización automática de textos2.
El DEFE se ha desarrollado, adaptando al español, el sistema creado por el profesor Eric Laporte (1988) para la fonetización del Sistema DELA (Dictionnaires Electroniques du LADL -Laboratoire d’Automatique Documentaire et Linguistique-)3, un sistema de diccionarios electrónicos del francés que fue desarrollado en la Universidad de París VII.
El Dictionnaire Electronique du LADL pour les mots Simples (DELAS) es el elemento central del sistema DELA, una base de datos ortográfica cuya especificidad es la codificación gramatical y morfológica asociada a cada entrada. Esta codificación, en forma alfanumérica, indica la categoría de los elementos léxicos y sus propiedades relacionadas con la flexión; a ella acceden los programas que generan automáticamente el Dictionnaire Electronique du LADL pour les formes Fléchies (DELAF), que contiene todas las formas flexivas de las palabras contenidas en el DELAS, además de las formas invariables (cf. Courtois, 1984, 1987 y 1990).
Ejemplo de entrada del DELAS (citado en Laporte, 1988: 76):
léger,.A42
El esquema de variación 42, al que pertenecen numerosos nombres y adjetivos, corresponde a las siguientes propiedades:
- La palabra admite la variación de género masculino/femenino. En singular, el masculino acaba en -er y el femenino en -ère.
- La palabra admite la variación de número singular/plural. Tanto para el masculino como para el femenino, el plural se obtiene añadiendo la desinencia -s a la forma singular.
Por su concepción y su organización, los diccionarios DELAS y DELAF son, respectivamente, semejantes al DEFSE y al DEFSFE; y entre las unidades léxicas que contienen se establece la misma relación de "lexemas/palabras gramaticales" que hemos mencionado al describir los diccionarios de la Base de Conocimiento Léxico.
Además de un conjunto de diccionarios que se generan manipulando la información contenida en el DELAS y el DELAF (diccionarios de formas simples y flexivas sin codificación morfológica, de clases gramaticales y de ordenación inversa), el sistema DELA consta también de un diccionario de formas compuestas: el Dictionnaire Electronique du LADL pour les mots Composés (DELAC), y de dos diccionarios fonéticos: el Dictionnaire Electronique du LADL pour la Phonémique (DELAP) y el Dictionnaire Electronique du LADL pour la Phonémique de les formes Fléchies (DELAP-F) (cf. Courtois, 1985, 1986-1987; Courtois y Silberztein, 1989 y 1990; Gross, 1989 y 1991; Gross y Perrin, 1989; Laporte, 1989a, 1989b y 1990).
En el DELAP y en el DELAP-F se representan, respectivamente, la pronunciación de las palabras contenidas en el DELAS y en el DELAF.
En el DELAP las entradas se dividen en tres zonas separadas por comas: (1) ortográfica, (2) fonémica y (3) gramatical y flexiva; por ejemplo (Laporte, 1988: 49):
discothèque, /diskotek/,.N21
En la primera zona, que sirve de clave de entrada a la información, se representa la palabra ortográficamente, tal y como aparece en el DELAS.
En la segunda se representa la pronunciación de la palabra a través de una cadena de fonemas entre barras oblicuas.
En la tercera aparecen codificadas alfanuméricamente la categoría gramatical de la palabra y las variaciones fonémicas que experimenta en la realización de sus formas flexivas, es decir, la pronunciación de las formas flexivas de la palabra representada. Esta información es paralela a la que contienen las entradas del DELAS sobre la variación de la forma ortográfica a causa de la flexión. En el ejemplo citado, el código N21 corresponde a la siguiente información:
- Nombre femenino con flexión de número.
- El plural ortográfico se obtiene añadiendo la desinencia -s al singular.
- El singular y el plural se pronuncian igual y tienen la misma transcripción fonémica.
La relación entre el DELAP y el DELAP-F es semejante a la que existe entre el DELAS y el DELAF: del mismo modo que los programas de flexión automática permiten generar las formas flexivas a partir de las formas canónicas representadas ortográficamente en el DELAS, los programas de fonetización permiten efectuar la misma operación sobre las formas representadas mediante caracteres fonéticos en el DELAP. Utilizando simultáneamente ambos programas, flexión y fonetización, se obtiene cada forma flexiva bajo sus dos representaciones, ortográfica y fonémica. Sobre las representaciones fonémicas del DELAP y el DELAP-F es posible generar una nueva representación en caracteres fonéticos de la pronunciación del léxico del francés, menos abstracta, mediante una cadena de sonidos entre corchetes.
3.2.3. La fonetización del sistema DELA.
Laporte (1988) propone un sistema de fonetización de una gran complejidad, cuyo objetivo es realizar la transcripción fonética automática de textos del francés con un margen de error virtualmente nulo. Este objetivo sólo puede alcanzarse a través de un léxico previamente transcrito, no por reglas que tengan en cuenta únicamente la información contextual, dada la gran irregularidad de la ortografía de esa lengua; por ejemplo, el grafema s en posición final de palabra se pronuncia como [s] en la palabra atlas, como [z] en blues, y tiene una realización muda en cas (Laporte, 1988: 32).
El sistema propuesto por Laporte está formado por un conjunto de aplicaciones que permiten:
(1) Generar el DELAP a partir del DELAS.
(2) Generar el DELAP-F a partir del DELAP.
(3) Generar la transcripción fonética a partir de la transcripción fonémica.
Este conjunto de aplicaciones se caracteriza por la aplicación simultánea de las reglas y por la separación entre las reglas y el programa. Las reglas pueden modificarse siempre que se mantenga el formato que las define. Todas estas características permiten que sea un sistema de fonetización independiente de la lengua: el programa aplica el conjunto de reglas particulares que se defina para cada una. Tampoco es necesario utilizar el conjunto de aplicaciones que forman el sistema, ya que son independientes.
Además de los usos industriales y didácticos a los que puede ser aplicado, el DELAP constituye en sí mismo una investigación sobre la correspondencia ortografía-pronunciación y la fonología del francés.
3.2.3.1. Generación del DELAP a partir del DELAS.
3.2.3.1.1. El phonétiseur de mots connus.
La aplicación denominada phonétiseur de mots connus, escrito en lenguaje C, calcula la pronunciación del léxico del francés con un margen de error virtualmente nulo y permite generar el DELAP a partir de un diccionario intermedio en el que se formalizan las irregularidades de la interpretación fónica de las grafías. Este diccionario, el DELASP, está formado por un conjunto de ficheros en los que se han marcado lo que el autor denomina "particularidades de lectura" de los grafemas. Por ejemplo, u ante g y seguida de una vocal sin diéresis, generalmente, no se pronuncia (anguille, guérir), es el caso no marcado y puede ser formalizado mediante una regla contextual; pero en algunas palabras, como aiguille, tiene el valor fónico de la vocal [u]: es una "particularidad de lectura" de este grafema (Laporte, 1988: 32).
El phonétiseur de mots connus está basado en un estudio profundo de la correspondencia entre la ortografía y la pronunciación del francés. En el examen de las 64.000 palabras del DELAS se han localizado 200 particularidades de lectura distintas. El conjunto de palabras en las que se da la misma particularidad se agrupa en una clase, codificada con un número del 1 al 200 seguido de un punto y eventualmente de uno o más caracteres; en el ejemplo anterior, todas las palabras en las que se pronuncia la u cuando está precedida de g y seguida de una vocal sin diéresis se agrupan en la clase 39: ang(39.)uille. Cada clase describe un caso difícil de la correspondencia entre ortografía y pronunciación, en palabras de origen francés, como la l muda de fusil y marsault; o de origen extranjero, como la i de silentbloc y iceberg (Laporte, 1988: 33).
A partir del DELASP se ha creado una lista de particularidades de lectura que se denomina DELASP-PL (PL = "particularidades de lectura"). El DELASP-PL está estructurado en 200 sublistas; cada una de ellas contiene las palabras que comportan una particularidad de lectura determinada. Por tanto, el DELASP-PL es una lista clasificada de las excepciones en la correspondencia ortografía-pronunciación: describe todos los tipos de irregularidades constatadas en esta relación y da la lista de ejemplos para cada tipo de irregularidad.
La aplicación que calcula la pronunciación de las palabras del DELASP tiene en cuenta la interpretación fónica regular de la ortografía y las particularidades de lectura; posee todos los datos para realizar la fonetización con un margen de error virtualmente nulo. Está estructurada en cinco pases: el primero opera sobre la palabra que se ha de fonetizar y se genera una forma intermedia en la que sólo una parte de las letras están transcritas como fonemas, los demás pases operan sobre formas mixtas del mismo tipo y el último produce la forma fonémica.
3.2.3.1.2. El phonétiseur de mots inconnus.
El phonétiseur de mots connus debe su nombre al hecho de que ha sido concebido para fonetizar las palabras con la información consignada en el DELASP. La segunda aplicación, el phonétiseur de mots inconnus, opera sobre las formas puramente ortográficas, tal como se encuentran en los textos, sin particularidades de lectura. Puesto que la forma ortográfica de una palabra no explicita su pronunciación de un modo absolutamente fiable, el fonetizador calcula todas las lecturas posibles de cada letra a través del examen del contexto; por ejemplo, transcribe atlas como [atlas], [atlaz] y [atla] (Laporte, 1988: 41). Esta aplicación consta de dos componentes:
(1) El primero formula las hipótesis sobre la pronunciación de las grafías e introduce las particularidades de lectura en aquellas posiciones de la palabra donde sea posible más de una interpretación fónica.
(2) El segundo genera la forma fonémica que corresponda a cada una de las hipótesis propuestas; este componente no es más que el phonétiseur de mots connus.
El phonétiseur de mots inconnus permite calcular la pronunciación de cualquier palabra que se introduzca en el diccionario, pero ha sido creado para cumplir una función específica: la corrección ortográfica por fonetización (cf. Laporte, 1988, Cap. VI, sec. 1, p. 141).
3.2.3.2. Generación del DELAPF a partir del DELAP.
Para generar la flexión automática de los nombres, adjetivos y verbos en su forma fonémica se ha construido un sistema paralelo al sistema de flexión ortográfica: las palabras se han clasificado siguiendo los esquemas de variación ortográfica y fonémica, que han sido incorporados al DELAP. Esta estrategia está justificada por las disparidades que existen en francés en la relación ortografía-pronunciación. Las variaciones flexivas de una palabra son distintas si se las representa ortográfica, fonémica o fonéticamente:
- El plural ortográfico y el plural fonético generalmente no concuerdan: la mayoría de los nombres y adjetivos realizan su plural ortográfico en -s, pero el plural se pronuncia como el singular, por lo que el plural fonético se realiza sin cambios.
- Se constatan también disparidades entre las formas femeninas
ortográficas y las formas femeninas fonéticas: todos los nombres y adjetivos
clasificados N42 y A42 tienen la misma variación ortográfica en femenino singular,
añaden la desinencia -e a la forma masculina; generalmente, en la forma fonética
se reemplaza la desinencia [e] por [![]()
![]() ]: léger [
]: léger [![]()
![]()
![]()
![]() ] légere [
] légere [![]()
![]()
![]()
![]()
![]() ]; sin embargo, en los adjetivos amer, cher
y fier, el masculino y el femenino se pronuncian de la misma manera: amer [
]; sin embargo, en los adjetivos amer, cher
y fier, el masculino y el femenino se pronuncian de la misma manera: amer [![]()
![]()
![]()
![]() ] amère
[
] amère
[![]()
![]()
![]()
![]() ] (Laporte,
1988: 76).
] (Laporte,
1988: 76).
- También los verbos presentan el mismo problema de falta de coincidencia entre las variaciones que se dan en la forma flexiva ortográfica de la palabra y en la forma flexiva fonética: filer y figer no tienen la misma conjugación ortográfica, como observamos en la tercera persona del singular del pretérito imperfecto de indicativo: il fil-ait / il fig-eait, pero sí la misma conjugación fonética (Laporte, 1988: 82).
3.2.3.3. Generación de la transcripción fonética a partir de la transcripción fonémica.
Tanto en el DELAP como en el DELAP-F, la pronunciación de la palabra entrada se representa a través de una cadena de fonemas, es una representación abstracta que formaliza la variación fonética de los elementos léxicos (palabras, raíces, afijos). Sobre ella es posible aplicar otro sistema de fonetización, creado por el propio autor (Laporte, 1984), que genera una representación fonética donde se refleja con las mayores fidelidad y exactitud posibles la pronunciación del francés, y es más apropiada para aplicarla en la síntesis y en el reconocimiento del habla.
El sistema de fonetización de Laporte constituye un estudio sobre los fenómenos de la variación fonética sistemática del francés, sistemática en el sentido de que se extienden a la comunidad general de hablantes. La variación puede depender del contexto fonético que deriva de los procesos morfológicos de flexión y derivación, por el encadenamiento de palabras en el discurso o por la interacción del acento y la sintaxis. Por ejemplo (Laporte, 1988: 98-99):
(1) Flexión.
Las pronunciaciones del radical del verbo plier en una o en dos sílabas alternan a lo largo de la conjugación según que el sufijo sea nulo, comience por vocal o por consonante4:
Luc pliait la carte
*[plie] [plije]
Luc (plie, pliera) la carte
[pli] *[plij]
(2) Derivación.
El sufijo -ien de nombres de lugar o de persona se pronuncia también en una o en dos sílabas según el grupo consonántico que le preceda inmediatamente:
italien
*[ij] [j]
ombrien
[ij] *[j]
(3) Contexto sintáctico.
El artículo les se pronuncia con o sin sonorización de la fricativa
según la inicial vocálica o consonántica de la palabra que le siga:
Les chats dorment
[le] *[lez]
Les enfants dorment
*[le] [lez]
(4) Interacción de las estructuras sintáctica y prosódica (acento y posición de la frase).
La partícula adverbial y es átona excepto cuando se sitúa tras el verbo, lo que sólo se produce en el imperativo:
Jean y a mis un cendrier
[ja] [ia]
Mets-y un cendrier
*[
] [
]
Según el caso, la partícula puede o no pronunciarse como una semiconsonante [j], por lo que hay una clara correlación entre la estructura sintáctica de la frase, la estructura prosódica y la aceptabilidad de la pronunciación de [j].
En los elementos léxicos del DELAP se señalan:
(1) Si poseen una variación fonética libre; por ejemplo el verbo lier, cuya raíz puede pronunciarse en dos sílabas o en una sílaba y ambas variantes se aplican en las mismas condiciones y son intercambiables (Laporte, 1988: 97):
lier
?*[lie] [lije] [lje]
(2) Si poseen una variación fonética condicionada y sus condiciones de aplicación; por ejemplo, el grupo fónico final -ien puede pronunciarse o no en una o dos sílabas, pero ambas variantes no tienen las mismas condiciones de empleo y se excluyen mutuamente; están, por tanto, en distribución complementaria (Laporte, 1988: 97).
italien
*[
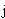
ombrien
[
En la transcripción fonética se descartan las variaciones estilísticas, geográficas o sociales; y sólo, de modo excepcional, se consignan entradas múltiples para aquellas palabras cuya pronunciación no está fijada en francés y admiten más de una representación fonémica; por ejemplo, el adjetivo exact, en el que puede pronunciarse o no el grupo final [kt] (Laporte, 1988: 51-53).
Además, Laporte (1988: 59-73) propone soluciones a determinados problemas de la transcripción del francés: el timbre vocálico, las vocales nasales, las consonantes finales y la e mudas, las consonantes dobles, las semiconsonantes, el fonema nasal velar, la h aspirada y los grupos consonánticos.
3.3. El sistema Laporte en la transcripción fonética automática español.
Para la generación del DEFE hemos partido del sistema creado por Laporte (1988), pero teniendo en cuenta las características de la lengua española y los objetivos de nuestra investigación.
3.3.1. El sistema de fonetización.
El sistema Laporte es de una gran complejidad, imprescindible para transcribir las irregularidades de la ortografía francesa con un margen de error virtualmente nulo. Para generar el DEFE no se ha de contar con todas las aplicaciones que generan el DELAP.
En español no cabe considerar
"particularidades de lecturas" de los grafemas como en francés, gran parte de
las irregularidades pueden ser resueltas por reglas. La interpretación fónica de las
letras sólo es impredecible en los extranjerismos y cada uno es un caso particular; será
suficiente con una lista de excepciones, que deberá ser abierta para que pueda incluir
nuevos términos. Por tanto, para generar el DEFE no contemplaremos particularidades de
lectura en el phonétiseur de mots connus. En cuanto al phonétiseur de mots
inconnus, es una aplicación útil en francés, por sus ambigüedades ortográficas fier:
[fie] (verbo se fier) / [![]()
![]()
![]()
![]() ] (adjetivo), pero no en la lengua española, regular
en su ortografía.
] (adjetivo), pero no en la lengua española, regular
en su ortografía.
No generaremos una transcripción fonémica flexiva a partir de la representación fonémica de una forma de base. En español no se ha de diferenciar entre flexión ortográfica y flexión fonémica, como sucede en francés; la interpretación fónica de la ortografía es tan regular en las formas de base como en las flexivas y no existen irregularidades ortográficas ligadas a la flexión que permitan diferenciar entre distintos esquemas de variación, ortográfica y fonémica.
En el DEFE, generaremos la transcripción fonética a partir de la transcripción fonémica, como en el DELAP. Este sistema tiene la ventaja de que permite obtener distintas representaciones fonéticas, con sólo aplicar el correspondiente conjunto de reglas, dada la independencia entre éstas y el programa que las aplica. Se podrán generar otros diccionarios, por ejemplo de pronunciación dialectal o de un determinado registro. En el DEFE transcribimos un modelo de pronunciación, pero siempre será posible transcribir otros.
En la transcripción del DEFE hemos incluido la división silábica y la acentuación, no contemplados en la transcripción de Laporte:
- En español, la silabación no siempre es predecible a partir de la organización secuencial de los segmentos (sub-lunar, sub-rayar) .
- Si la acentuación no es pertinente en una transcripción fonética del francés, sí en español, lengua con acento léxico libre (hábito, habito, habitó). Hemos creado una aplicación específica de asignación del acento.
3.3.2. Formalismo y características de las reglas de transcripción.
Las reglas del sistema Laporte (1988) son reglas contextuales de aplicación local.
El formato de las reglas consta del foco sobre el que se aplica el cambio propuesto y tres contextos precedentes y cuatro siguientes, opcionales, separados por pares de comas.
.........,,.........,,.........,, FOCO ,,.........,,.........,,.........,,.........,, 3 contextos precedentes 4 contextos siguientes CAMBIO. |
No hay límite en el número de signos que pueden aparecer en el foco; tampoco, en los campos contextuales. Si en éstos no hay ningún signo, se indica que no hay restricciones de aplicación de la regla. En el cambio pueden aparecer dos signos separados por comas, un signo o ninguno. Los signos que aparezcan en el cambio han de ir seguidos de « 0 », por formalismos del sistema informático. Un punto señala el fin de la regla.
La información contextual de las reglas puede hacer referencia a los límites de palabra: límite inicial y límite final; en ambos casos se representa mediante el signo « _ ». La distinta posición viene indicada por el lugar que este signo ocupa en la regla: si se sitúa en los contextos anteriores al foco, se referirá al límite inicial de palabra; si se sitúa en los contextos posteriores al foco, se referirá al límite final.
Los signos que aparezcan en el foco y en los campos contextuales pueden ser negados, mediante el símbolo « ! », indicándose así que la regla se aplica en todos los contextos excepto en ésos; por ejemplo, la regla que transcribe el grafema g como [g] siempre que no está precedido por las vocales e, é, i, í.
|
|
Las reglas tienen la particularidad de no ser ordenadas: se aplican todas simultáneamente (si el fonetizador es modular, dentro de cada módulo). El sistema detecta de modo automático cuándo dos o más reglas dan cuenta del mismo fenómeno y bloquea la aplicación de la fonetización. Se genera un fichero que en el que constan los contextos en los que se solapan la aplicación de las reglas.
Atendiendo a la transformación que realizan, existen tres tipos de reglas:
(1) Reglas que modifican un signo en otro en una relación unívoca; por ejemplo, la regla que transcribe el grafema g como [x] en el contexto precedente a las vocales e, é, i, í.
|
|
(2) Reglas que suprimen un elemento, es decir, reglas que realizan una conversión nula; por ejemplo, la regla que elimina la u en el dígrafo gu ante las vocales e, é, i, í.
|
|
(3) Reglas que insertan un elemento, es decir, que transcriben un signo de entrada como dos en la salida; por ejemplo, la regla que transcribe el grafema x como [ks].
|
|
Las reglas de inserción no tiene por qué modificar los signos de entrada; puede añadir un nuevo signo en la cadena de caracteres y mantener los existentes. Por ejemplo, las reglas de silabación insertarán una marca de división silábica, a la que representamos mediante un guión: « - », sin modificar la cadena de segmentos fónicos. Como la salida de la regla tiene dos campos, en uno de ellos se especificará el signo insertado y en el otro se marcará con el signo « = » la no modificación del carácter que consta en el foco.
La silabación puede operar de dos formas, que ejemplificamos con una regla general: "una consonante entre dos vocales siempre forma sílaba con la vocal siguiente":
V1 C V2 ---> V1 - C V2
(i) En el foco de la regla puede constar la consonante ante la que se sitúa la marca de división silábica; en ese caso, el primer campo de la salida contendrá dicho signo y el segundo, el carácter « = », con el que se impide la modificación de « C ».
|
|
(ii) La segunda opción es que en el foco de la regla conste la vocal tras la que se sitúa la marca de división silábica: el segundo campo de la salida contendrá dicho signo y el primero el carácter « = » con el que se impide la modificación de « V ».
|
|
Hemos preferido la primera formalización, atendiendo al enunciado de la regla: "una consonante (signo contenido en el foco) entre dos vocales (signos especificados en los contextos precedente y siguiente) siempre forma sílaba con la consonante siguiente (inserción de la marca de división silábica ante la consonante del foco). Esta formalización se mantendrá en todas las reglas del módulo (cf. infra, FON2.REG).
Para transcribir un dígrafo se necesitan dos reglas: una que transforme uno de los grafemas en el signo de salida y otra que borre el segundo grafema. Lo ejemplificamos con las reglas que transcriben la elle del alfabeto académico.
El dígrafo ll representa el fonema lateral
palatal /![]() /
(en nuestro alfabeto fonético, « L »); para transcribirlo se necesita:
/
(en nuestro alfabeto fonético, « L »); para transcribirlo se necesita:
- Una regla que convierta una de las eles en el símbolo fonético L (Regla L1).
- Otra que elimine la segunda ele (Regla L2).
La Regla L1 puede ser formulada indistintamente de dos modos:
(i) "Todo signo l, cuando va seguido de otro signo l, se convierte en L", cuya representación gráfica es la de (L1.1):
|
|
(ii) "Todo signo l, cuando va precedido de otro signo l, se convierte en L", cuya representación gráfica es la de (L1.2):
|
|
También la regla que elide la segunda ele puede ser formulada de dos modos:
(i) "Todo signo l, cuando va seguido de otro signo l, tiene una realización nula", cuya representación gráfica es la de (L2.1):
|
|
(ii) "Todo signo l, cuando va precedido de otro signo l, tiene una realización nula", cuya representación gráfica es la de (L2.2):
|
|
Las dos versiones enunciadas de la Regla L1 realizarían la conversión de una l en L y las dos versiones de la Regla L2 suprimirían la segunda ele, no existen argumentos para preferir una versión a otra; únicamente deberemos tener presente que ambas reglas están asociadas para dar cuenta de un mismo fenómeno y que para ello deberá mantenerse la coherencia entre las versiones elegidas. Si en la Regla L1 el cambio es sensible al contexto siguiente al foco, en la Regla L2 ha de ser sensible al contexto precedente:
|
|
Regla (L2.2) |
,, ,, l,, l,, ,, ,, ,, ,. |
Por el contrario, si en la Regla L1 el cambio es sensible al contexto precedente al foco, en la Regla L2 lo ha de ser al contexto siguiente:
|
|
|
|
El objetivo de nuestra investigación es crear el Diccionario Electrónico Fonético del Español a través de un sistema de transcripción fonética automática. El DEFE consistirá en una transcripción alofónica del conjunto de palabras contenidas en el Diccionario Electrónico de Formas Simples Flexivas del Español, las palabras con la forma con la que aparecen en los textos. La transcripción alofónica se generará a partir de una transcripción fonémica inicial. Por transcripción fonémica entendemos 'una representación como cadena de fonemas' y por transcripción alofónica 'una representación como cadena de alófonos, las variantes contextuales de los fonemas': son dos formas de representar, con distinto grado de abstracción, la pronunciación del léxico del español (definiremos estos conceptos en el Capítulo 5 de este trabajo).
El DEFE ha sido concebido desde la siguiente premisa: el sistema de transcripción fonética automática que lo genere ha de actuar con un margen de error virtualmente nulo, ha de transcribir el léxico del español contenido en el DEFSFE y toda palabra de nueva incorporación; para ello, es preciso estudiar lo regular y lo irregular de la relación entre norma ortográfica y pronunciación: aquellos fenómenos que puede ser tratados regularmente y aquellos que requieren una información adicional. Un sistema de transcripción fonética automática del español que quiera actuar con un margen de error virtualmente nulo se ha de basar en un estudio de la fonología en el léxico, deberá determinar el conjunto de reglas de transcripción y sus excepciones, así como las unidades léxicas en las que se aplican las reglas y las que están sujetas a excepción5.
3.4.2. La información lingüística en el DEFE.
3.4.2.1. La información lingüística en la transcripción fonética automática del español.
Ya hemos señalado que no siempre la pronunciación del español se desprende de la ortografía. Existen fenómenos fonológicos idiosincrásicos en el léxico para los que no es suficiente la información grafemática cuando han de ser tratados en un sistema automático de transcripción. Para transcribir el léxico con un margen de error virtualmente nulo se ha de contar con información lingüística (cf. Ríos, 1993):
1. Información fonológica:
1.1. La posición de los segmentos en la cadena.
En una transcripción regular de standing [s.'tan.din], la consonante [s] aparecería en una posición no permitida; en español no existen consonantes silábicas, han tener un apoyo vocálico o han de ser elididas. Este ejemplo muestra que es preciso determinar las posiciones permitidas de los segmentos en la cadena fónica.
1.2. Las restricciones de las combinaciones consonánticas y vocálicas en las agrupaciones silábicas.
Para transcribir correctamente palabras como standing, angstrom y palimpsesto, se ha de contar con que no existen los grupos tautosilábicos [ng], [ngs], [mp], [ps]: deberemos determinar las restricciones en la combinación de los segmentos consonánticos. Lo mismo sucede con los segmentos vocálicos: por ejemplo, la realización de un diptongo o un hiato es pertinente en español; es el caso de pie (nombre) / pié (verbo piar): se trata de una propiedad idiosincrásica de cada elemento léxico que ha de ser marcada en la transcripción y no siempre es deducible de la ortografía.
1.3. La acentuación
El español es una lengua con acento léxico libre y las normas ortográficas no siempre permiten deducir la acentuación de la palabra; es el caso, por ejemplo, de los monosílabos sin acento diacrítico, que pueden ser tónicos o átonos y en ningún caso llevan tilde.
2. Información morfofonológica.
En los verbos vocálicos, la presencia de un diptongo o de un hiato es una propiedad idiosincrásica ligada a la conjugación: se da en todo el paradigma flexivo; lo mismo sucede con nombres y adjetivos. La silabación no se puede deducir de la ortografía en las formas que no llevan tilde en la vocal cerrada. Por otro lado, la pronunciación como diptongo o hiato en los verbos vocálicos acabados en -uar depende de la consonante que precede a /u/ (si la consonante es velar hay diptongo; si es no velar, hiato), pero no sucede así en los verbos en-iar, en ellos, la existencia de un diptongo o un hiato no se puede deducir de la secuencia fónica. Los derivados de los verbos vocálicos pueden mantener o romper el hiato de la raíz según el sufijo adjuntado; por ejemplo, -ble tiende a mantener el hiato (fiable, acentuable, destruible), frente a -ción, que tiende a romperlo (variación, acentuación, intuición). Existen fenómenos fonológicos ligados a la forma de las palabras complejas que han de ser tenidos en cuanta en la transcripción6.
3. Información categorial.
La categoría de la palabra tiene consecuencias en su acentuación: existen clases de palabras átonas (determinantes, pronombres átonos, conjunciones y preposiciones), clases de palabras tónicas (sustantivos, adjetivos, verbos, adverbios y pronombres tónicos) y clases con doble acentuación (los adverbios en -mente ). De la ortografía no se puede deducir, por ejemplo, que vehemente es adjetivo y sólo tiene un acento, frente a simplemente, adverbio, con doble acentuación, en la raíz y en el sufijo. El carácter átono o tónico de los monosílabos sin acento diacrítico se ha de resolver recurriendo a su categoría.
3.4.2.2. El DEFE como sistema descriptivo de la fonología del español.
El resultado de la aplicación del sistema de transcripción fonética automática que hemos desarrollado constituye una descripción del sistema fonológico del español y da cuenta de los fenómenos regulares e irregulares de la lengua.
El DEFE es la formalización de un determinado conocimiento del hablante, explicita:
(1) el repertorio de fonemas y de alófonos,
(2) su distribución,
(3) la organización silábica de la cadena fónica,
(4) las restricciones de combinación de los grupos consonánticos y vocálicos,
(5) el carácter tónico o átono de una determinada unidad léxica,
(6) la posición del acento,
(7) los procesos que relacionan fonemas y alófonos.
A esa información fonológica se suma el conjunto de conocimientos implicados en la transcripción, toda aquella información lingüística que ha sido necesaria para construir un transcriptor que actúa según el objetivo propuesto: información categorial en el estudio del acento e información morfológica flexiva y de formación de palabras en el estudio de los diptongos e hiatos.
3.4.3. La transcripción fonética del DEFE.
3.4.3.1. Modelo de pronunciación y fuentes de documentación.
El registro de habla que transcribimos es la variedad estándar de la lengua (español no americano). Entendemos por variedad estándar de la lengua un registro no marcado ni dialectal ni estilísticamente. No es en modo alguno un habla abstracta, sin usuarios reales; ni es un habla ligada a una localización geográfica concreta, como señalan Canellada y Madsen (1987: 17):
"No es un lenguaje que solo se habla en un determinado lugar de Castilla, sino que es un lenguaje neutral en el sentido de que, venga de donde venga el hablante de este lenguaje, no se le puede localizar por su pronunciación de castellano. Este tipo de lenguaje se puede escuchar igual en Orense que Murcia, y puede muy bien convenir en una misma persona con un dialecto diferente. Su centro está en Castilla, por supuesto, pero en Castilla también hay hablas localizables."
Por tanto, no contemplaremos en nuestra transcripción los fenómenos dialectales (por ejemplo, el yeísmo) y los estilísticos (por ejemplo, las variaciones producidas en un estilo de habla relajado)7. Tampoco incluiremos variantes, la transcripción en caracteres fonéticos será una para cada palabra. Transcribiremos la variedad estándar de la lengua que ha sido descrita en los manuales de pronunciación especializados; fundamentalmente, Navarro Tomás (1918) y Canellada y Madsen (1987). Completaremos la documentación con manuales de fonética y fonología española y con aquellas obras especializadas que consideremos necesarias.
3.4.3.2. Formalismo de la representación: los símbolos de la transcripción fonética del DEFE.
En el Capítulo 5, justificaremos la elección de los segmentos transcritos (fonemas y alófonos) y su caracterización; en este apartado sólo mostramos su representación.
El objetivo de nuestra investigación, las características de la transcripción que proponemos y el medio informático han determinado la elección del repertorio de signos utilizados en el DEFE (cf. de la Mota y Ríos, 1996; Farjas y Ríos, 1995)8.
3.4.3.2.1. Consideraciones para la elección del repertorio de signos.
Al establecer los criterios para la formalización del repertorio de signos, lo que denominamos "criterios de transcripción", hemos tenido en cuenta el alfabeto fonético utilizado, los aspectos lingüísticos de nuestra transcripción y las características de la representación informática.
(1) Alfabeto fonético.
El alfabeto fonético elegido para representar la pronunciación del DEFE es el AFI, un alfabeto internacional ampliamente aceptado por la comunidad lingüística (cf. IPA, 1949, 1989a, 1989b, 1993, 1995). Sin embargo, presenta algunos problemas para la transcripción del español, por lo que ha sido necesario adaptarlo a nuestra lengua modificando algunas de sus convenciones.
En la representación del español, el uso estricto del AFI conlleva la proliferación de diacríticos en la transcripción, que dificulta la lectura, y la pérdida de la distinción entre semiconsonantes y semivocales.
(1.1) Proliferación de diacríticos.
El AFI no contempla mediante un signo propio todos los sonidos del español, se han de usar signos modificados con un diacrítico; son los casos de la representación de las articulaciones interdental, dental, africada y aproximante.
(1.1.1) Articulación interdental.
El punto de articulación interdental no ha sido
previsto en el AFI. Se ha de utilizar un diacrítico, aplicado en los símbolos de las
consonantes dentales, para indicar que se adelanta el punto de articulación. Siguiendo
estrictamente el repertorio de signos del AFI, la representación de la consonante
fricativa interdental sorda de la palabra zafio ha de ser [![]() +]. Como en
español no existe la fricativa dental sorda [
+]. Como en
español no existe la fricativa dental sorda [![]() ], no es necesario utilizar el diacrítico
si se asigna su símbolo para la interdental.
], no es necesario utilizar el diacrítico
si se asigna su símbolo para la interdental.
(1.1.2) Articulación dental.
Para representar las consonantes oclusivas dentales
del español [![]() ] (tierra) y [
] (tierra) y [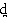 ] (conde)
ha de usarse el diacrítico que indica dentalización, puesto que los símbolos [t] y [d]
representan consonantes alveolares en el AFI. Como en español no existen dichas
alveolares se pueden usar los signos [t] y [d] sin diacrítico.
] (conde)
ha de usarse el diacrítico que indica dentalización, puesto que los símbolos [t] y [d]
representan consonantes alveolares en el AFI. Como en español no existen dichas
alveolares se pueden usar los signos [t] y [d] sin diacrítico.
(1.1.3) Articulación africada.
Puesto que [t] y [d] simbolizan consonantes alveolares en AFI, también en la representación de las consonantes africadas s
orda [(1.1.4) Articulación aproximante.
En la representación de las consonantes bilabial [![]() ] (lobo),
dental [
] (lobo),
dental [![]() ] (codo) y velar [
] (codo) y velar [![]() ] (dogo), se ha de usar un diacrítico, [
] (dogo), se ha de usar un diacrítico, [![]() ], para
indicar que en español poseen un modo de articulación aproximante, y que no son las
consonantes fricativas [
], para
indicar que en español poseen un modo de articulación aproximante, y que no son las
consonantes fricativas [![]() ], [
], [![]() ] y [
] y [![]() ] del AFI. Sólo la consonante
aproximante velar posee un signo propio: [
] del AFI. Sólo la consonante
aproximante velar posee un signo propio: [![]() ], por lo que puede ser
representada mediante dos formas distintas. Hay una asimetría en el alfabeto: un signo
propio para una aproximante y uso de diacrítico para las demás. Consideramos que la
mejor solución es representar las aproximantes del español como [
], por lo que puede ser
representada mediante dos formas distintas. Hay una asimetría en el alfabeto: un signo
propio para una aproximante y uso de diacrítico para las demás. Consideramos que la
mejor solución es representar las aproximantes del español como [![]() ], [
], [![]() ] y [
] y [![]() ], sólo aclarando que no son sonidos fricativos10.
], sólo aclarando que no son sonidos fricativos10.
(1.2) Pérdida de la distinción gráfica entre semivocales y semiconsonantes.
Con la adopción del inventario de símbolos que propone la Asociación Fonética Internacional se pierde la distinción gráfica entre semivocales y semiconsonantes, puesto que sólo puede utilizarse el diacrítico que indica "no silábico":
['
.
] ['
.
]
['
.
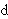
]
(2) Aspectos lingüísticos de la transcripción.
En la elección de un inventario de símbolos fonéticos se deberá decidir si se transcriben o no aspectos fonológicos.
Proponemos un sistema de transcripción fonética automática que relaciona dos niveles distintos: una representación fonémica abstracta y una representación alofónica derivada de la primera mediante la aplicación de reglas que explicitan el contraste fonético entre las variantes de un determinado fonema, el resultado de los procesos alofónicos del español11. Para no perder capacidad descriptiva en la relación entre ambas representaciones, en el uso de los símbolos y diacríticos del AFI hemos diferenciado los casos que representan una oposición fonológica de aquellos en los que no se produce dicha oposición. Así, con el AFI es posible usar diacríticos para distinguir los sonidos resultantes de procesos de asimilación de los sonidos derivados directamente del fonema correspondiente. Es el caso del proceso de palatalización12:
|
[ |
calle |
| [ |
peña | |
|
[lj] | colcha |
| [nj] | concha |
(3) Representación informática de la transcripción.
El resultado de nuestro sistema de transcripción puede ser representado materialmente a través de dos medios: en la pantalla del ordenador y en la salida por impresora; hemos tenido que diseñar dos convenciones distintas, una para cada tipo de representación.
En la pantalla, puesto que utilizamos el sistema operativo VAX-VMS, para el que no existe una fuente AFI, los signos fonéticos se representan mediante uno de los 125 primeros caracteres ASCII de dicho sistema (se exceptúan « ñ » y « ç »). Cada signo fonético es representado por un sólo carácter, sin diacríticos, manteniendo la simplicidad técnica necesaria para una buena operatividad del sistema de transcripción. La representación en pantalla es arbitraria cuando un signo fonético no tiene representación en el código ASCII.
Para la salida por impresora hemos adaptado el repertorio de signos propuesto por el AFI al español. También en esta representación es recomendable evitar la proliferación de diacríticos, puesto que el espacio ocupado por cada carácter tiene una determinada dimensión y al sobrecargarlo de diacríticos resultaría un signo de difícil lectura. Por ese motivo, en aquellos casos en los que el AFI presenta dos posibles representaciones para un mismo sonido, hemos escogido la más simple, es decir, siempre que un sonido del español puede ser representado mediante un símbolo único de AFI hemos adoptado dicho signo. Ello que nos ha permitido reducir el número de diacríticos en la transcripción.
3.4.3.2.2. Criterios de transcripción
Atendiendo a los aspectos considerados, hemos establecido los siguientes criterios de transcripción:
I. Si no se da oposición fonológica, no se usan diacríticos. Así,
en los segmentos oclusivos del español no existe la oposición alveolar-dental y no es
necesario usar el diacrítico de dentalidad para [t] y [d]; ni el de adelantamiento para [![]() ], puesto que
no existe la oposición dental-interdental en los segmentos fricativos.
], puesto que
no existe la oposición dental-interdental en los segmentos fricativos.
II. Si no se da oposición fonológica, sólo se usan diacríticos
cuando existe contraste fonético entre alófonos de un mismo fonema, salvo que tengan un
símbolo propio. Así, en los alófonos del fonema nasal alveolar /n/, diferenciamos
mediante diacríticos el dental [ ] y el palatalizado
] y el palatalizado
 ] y el velar [
] y el velar [III. Cuando se da oposición fonológica, no se usan diacríticos cuando hay un símbolo propio. Diferenciamos así, por ejemplo, el fonema nasal alveolar /n/ del nasal palatal /
IV. Cuando se da oposición fonológica, se usan diacríticos para diferenciar un sonido como realización plena de un fonema del mismo sonido como realización alofónica de otro fonema; son los casos del sonido lateral palatal
[El repertorio de símbolos fonéticos utilizados en el DEFE, en su representación en pantalla y en su representación en impresora, está contenido en las Tablas 6 y 7. En la primera, aparecen los símbolos con los que representamos los fonemas del español; en la segunda, los alófonos que resultan de los procesos alofónicos que describimos a través de la transcripción del Diccionario Electrónico Fonético del Español.
Recordamos que en el DEFE, el acento se representa con una tilde sobre la vocal acentuada, al modo ortográfico, para facilitar la lectura, y la marca de división silábica se representa mediante un guión « - ».
Tabla 6. Fonemas del español.
VOCALES |
||||
AFI |
DEFE impresora |
DEFE pantalla |
DESCRIPCIÓN |
EJEMPLO |
i |
i |
i |
vocal anterior cerrada13 |
libro |
e |
e |
e |
vocal anterior media |
pez |
a |
a |
a |
vocal central abierta |
caso |
o |
o |
o |
vocal posterior media |
coma |
u |
u |
u |
vocal posterior cerrada |
luz |
CONSONANTES |
||||
AFI |
DEFE impresora |
DEFE pantalla |
DESCRIPCIÓN |
EJEMPLO |
p |
p |
p |
oclusiva bilabial sorda |
peso |
b |
b |
b |
oclusiva bilabial sonora |
boca |
|
t |
t |
oclusiva dental sorda |
tabaco |
|
d |
d |
oclusiva dental sonora |
dote |
|
|
y |
oclusiva palatal sonora |
yeso |
k |
k |
k |
oclusiva velar sorda |
coma |
g |
g |
g |
oclusiva velar sonora |
goma |
|
|
z |
fricativa interdental sorda |
zapato |
f |
f |
f |
fricativa labiodental sorda |
falso |
s |
s |
s |
fricativa alveolar sorda |
sello |
x |
x |
x |
fricativa velar sorda |
jota |
|
|
c |
africada palatal sorda |
chico |
m |
m |
m |
nasal bilabial |
madre |
n |
n |
n |
nasal alveolar |
nada |
|
|
ñ |
nasal palatal |
ñu |
l |
l |
l |
lateral alveolar |
lona |
|
|
L |
lateral palatal |
llanto |
|
|
r |
vibrante alveolar simple |
caro |
r |
r |
R |
vibrante alveolar múltiple |
carro |
w |
w |
w |
aproximante labiovelar |
hueso |
Tabla 7. Alófonos del español (clasificados por procesos alofónicos).
1. Glidización14. |
||||
AFI |
DEFE impresora |
DEFE pantalla |
DESCRIPCIÓN |
EJEMPLO |
|
|
I |
glide palatal (semivocal y semiconsonante) |
miedo, doy |
|
|
U |
glide labiovelar (semivocal y semiconsonante) |
cuento, aula |
2. Debilitamiento. |
||||
AFI |
DEFE impresora |
DEFE pantalla |
DESCRIPCIÓN |
EJEMPLO |
B |
aproximante bilabial |
lobo |
||
D |
aproximante dental |
lodo |
||
j |
j |
j |
aproximante palatal |
haya |
G |
aproximante velar |
mago |
||
3. Sonorización. |
||||
AFI |
DEFE impresora |
DEFE pantalla |
DESCRIPCIÓN |
EJEMPLO |
 + + |
|
Z |
interdental fricativa sonora |
gozne |
z |
z |
S | alveolar fricativa sonora |
asno |
4. Debilitamiento y ensordecimiento15. |
||||
AFI |
DEFE impresora |
DEFE pantalla |
DESCRIPCIÓN |
EJEMPLO |
P |
aproximante bilabial ensordecida |
obcecado |
||
T |
aproximante dental ensordecida |
adjetivo |
||
K |
aproximante velar ensordecida |
zigzag |
||
5. Asimilaciones al punto de articulación. |
||||
5.1. Labiodentalización. |
||||
AFI |
DEFE impresora |
DEFE pantalla |
DESCRIPCIÓN |
EJEMPLO |
M |
nasal labiodental |
ánfora |
||
5.2. Interdentalización. |
||||
AFI |
DEFE impresora |
DEFE pantalla |
DESCRIPCIÓN |
EJEMPLO |
| t+ | v |
oclusiva interdental sorda |
hazte |
|
V |
lateral interdental |
alzar |
||
| + |
+ |
q |
nasal interdental |
anzuelo |
5.3. Dentalización. |
||||
AFI |
DEFE impresora |
DEFE pantalla |
DESCRIPCIÓN |
EJEMPLO |
Ç |
dental fricativa sorda |
pasta |
||
C |
lateral dental |
alto |
||
|
|
Q |
nasal dental |
antes |
5.4. Palatalización. |
||||
AFI |
DEFE impresora |
DEFE pantalla |
DESCRIPCIÓN |
EJEMPLO |
| lj | lj | J |
lateral palatalizada |
colcha |
| nj | nj | Ñ |
nasal palatalizada |
concha |
5.5. Velarización. |
||||
AFI |
DEFE impresora |
DEFE pantalla |
DESCRIPCIÓN |
EJEMPLO |
N |
nasal velar |
roncar |
||
6. Asimilación al punto de articulación (dentalización) y sonorización. |
||||
AFI |
DEFE impresora |
DEFE pantalla |
DESCRIPCIÓN |
EJEMPLO |
 |
|
ç |
fricativa dental sonora |
desdén |
7. Asimilación al modo de articulación (vibrantización) y sonorización. |
||||
AFI |
DEFE impresora |
DEFE pantalla |
DESCRIPCIÓN |
EJEMPLO |
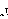 |
|
H |
fricativa vibrante |
Israel |
3.5. El sistema de transcripción fonética del DEFE
La creación del DEFE ha sido abordada aplicando dos tipos de mecanismos, según el aspecto de la transcripción que se deba tratar:
(1) Un sistema de transcripción fonética automática (que adapta el sistema Laporte) para todos aquellos casos en los que la representación fonética se puede obtener mediante reglas que se aplican sobre la representación ortográfica de la palabra. Este sistema transcribe todas las regularidades de la relación entre ortografía y pronunciación y aquellas anomalías del sistema ortográfico (por proceder de extranjerismos) que tienen una interpretación fónica regular.
(2) Mecanismos específicos para transcribir todos aquellos casos en los que la pronunciación no puede deducirse de la ortografía. Son, fundamentalmente, los hiatos no marcados ortográficamente, además de un gran número de extranjerismos.
En este apartado describiremos el sistema de transcripción fonética automática que genera el DEFE: su estructura y los distintos módulos de reglas que lo conforman, así como la metodología seguida para la construcción del diccionario. El conjunto de reglas de cada módulo de transcripción será descrito en un capítulo específico.
3.5.1. Estructura del sistema de transcripción.
El sistema de transcripción que genera el DEFE consiste en un sistema modular de grupos de reglas que, partiendo de la representación ortográfica, explicita la información lingüística necesaria para la pronunciación del léxico de la lengua española. El resultado de la aplicación de las reglas de cada módulo es la entrada para la aplicación de otro grupo, en una sucesión ordenada. Cada módulo da cuenta de un aspecto de la transcripción:
1. Presilabación (PRESILAB).
El primer mecanismo que se aplica a la representación ortográfica del DEFSE es el que hemos denominado presilabación. La operación que realiza es marcar el límite silábico en aquellas palabras con hiato no deducible de la ortografía. Se aplica sobre el diccionario de formas simples, antes de generar la flexión automática, porque –salvo casos excepcionales– el hiato se reproduce en todo el paradigma flexivo. Este módulo trata una anomalía del sistema ortográfico, y sólo actúa sobre aquel sector del léxico en el que se dé el fenómeno descrito.
2. Reglas de fonemización.
Sobre la representación ortográfica del DEFSFE actúa un grupo de Reglas de fonemización, integrado por cuatro módulos, cuya salida es una representación de la palabra como cadena de fonemas, con marcas de división silábica y acento.
2.1. Reglas de transcripción grafema-fonema (FON1.REG).
Asignan una representación en signos fonéticos a la cadena grafemática. La salida de la aplicación de este módulo de reglas representa la pronunciación de la palabra como cadena de fonemas, sin marcas de marcas de división silábica, pero conservando el acento marcado ortográficamente. Las reglas dan cuenta de las interpretaciones regulares de la ortografía.
2.2. Reglas de silabación (FON2.REG).
Agrupan los fonemas en las sucesiones silábicas permitidas en español. Tienen en cuenta las restricciones del sistema fonológico en las combinaciones de vocales y consonantes.
2.3. Reglas de ajuste silábico (FON3.REG).
Constituyen una propuesta de tratamiento regular de las excepciones en la relación grafema-fonema en español. Las reglas de silabación realizan un corte silábico normativo, que resulta erróneo en los extranjerismos no adaptados ortográficamente. El módulo de Reglas de ajuste silábico elimina aquellas secuencias no admitidas en la lengua española mediante el borrado o la inserción de elementos, como en /s.'tan.din.g/ ---> /es.'tan.din/, y realiza las resilabaciones pertinentes en cada secuencia, como en /'an.g.s.trom/ ---> /'ans.trom/. Con este módulo se reduce el número de reglas de conversión grafía-fonema de baja productividad y permite la reducción de las listas de excepciones. No obstante, la transcripción de una parte residual del léxico ha de ser corregida ad hoc: se trata, fundamentalmente, de extranjerismos anómalos cuya pronunciación no puede deducirse de la ortografía atendiendo a reglas de aplicación regular; esta operación se realiza tras la salida de FON3.REG.
1.4. Reglas de acentuación (FON4.REG).
Descartan el acento en las palabras átonas; asignan el acento en las palabras tónicas sin tilde, siguiendo las normas del español (atiende a los fonemas finales de palabra y a la posición de la sílaba en la palabra); y recogen los casos de doble acentuación, los adverbios en -mente.
1.5. Reglas de ajuste fonémico (FON5.REG).
Las reglas de acentuación parten de las normas de asignación de la tilde, concebidas para actuar sobre una representación ortográfica, pero se aplican sobre una representación de fonemas. Entre ambas representaciones existen desajustes que obligan a suspender la aplicación de algunas reglas de FON1 hasta que se apliquen las de acentuación. El módulo de ajuste fonémico completa la transcripción grafema-fonema.
La salida de este primer grupo de reglas constituye, de hecho, un primer diccionario: el Diccionario Electrónico Fonémico del Español (aunque no ha sido incorporado a la Base de Conocimiento Léxico), una representación abstracta de la pronunciación del léxico de la lengua española.
3. Reglas de transcripción fonema-alófono (FON6.REG).
Sobre la transcripción fonémica actúa este último módulo. Su salida es el Diccionario Electrónico Fonético del Español, en el que se representa la pronunciación del léxico de la lengua española como una cadena de alófonos (manteniendo las marcas de división silábica y acentuales de la representación fonémica). Las Reglas de fonetización expresan procesos alofónicos, el resultado de la variación contextual; a través de ellas se relacionan las dos representaciones, la fonémica y la alofónica.
También hemos diseñado un módulo de fonetización sintáctica (FON7.REG), concebido para la aplicación del DEFE en la fonetización de textos; no forma parte del sistema que genera el diccionario fonético. Este módulo realiza las operaciones de resilabación de los segmentos que se encuentran en el enlace entre palabras y transcriben la variación alofónica de esa misma posición.
La estructura del sistema de transcripción está representada en la Figura 1.
Figura 1. Estructura del sistema de transcripción fonética automática del DEFE.
DICCIONARIO ELECTRÓNICO DE FORMAS SIMPLES DEL ESPAÑOL (DEFSE) |

PRESILABACIÓN |
APLICACIONES DE FLEXIÓN |
DICCIONARIO ELECTRÓNICO DE FORMAS SIMPLES FLEXIVAS DEL ESPAÑOL (DEFSFE) |
REGLAS DE FONEMIZACIÓN
|
DICCIONARIO ELECTRÓNICO FONÉMICO DEL ESPAÑOL |
Reglas de transcripción fonema-alófono |
DICCIONARIO ELECTRÓNICO FONÉTICO DEL ESPAÑOL (DEFE) |
Reglas de fonetización sintáctica |
El orden final de los módulos de fonetización es el resultado del estudio del tratamiento de las excepciones. En el diseño inicial sólo existían cuatro subgrupos de reglas:
(1) Conversión grafema-fonema.
(2) Silabación.
(3) Acentuación.
(4) Conversión fonema-alófono.
De la conversión grafema-fonema se obtenía una transcripción fonética "limpia", sin segmentos no realizables, lo que suponía resolver todas las excepciones en ese módulo. La reglas de silabación se aplicaban sobre la cadena fónica real de cada palabra. En el transcurso de la investigación introdujimos un nuevo módulo de reglas que busca un tratamiento general de las irregularidades que lo permiten. Fue necesario modificar las reglas iniciales de conversión grafema-fonema y de silabación para adaptar el funcionamiento de los tres módulos. El diseño final del programa del acento, por su parte, obligó a alterar el orden de aplicación de las reglas de conversión grafema-fonema, como describiremos en su lugar correspondiente (cf. infra, §6.4.2). La ordenación final es el resultado de la interacción de los distintos módulos y de las soluciones adoptadas para resolver los problemas de la fonetización.
Nuestra propuesta tiene un enfoque eminentemente fonológico. Lo observamos en la ordenación de las operaciones. El procedimiento más sencillo partiendo de una representación ortográfica es realizar la silabación ortográfica antes de la asignación del acento y de la conversión de los grafemas en signos fonéticos; pero esta ordenación no se ajusta a nuestros propósitos. Creemos que con ella el sistema de transcripción pierde capacidad descriptiva. Las letras son una forma de representar los sonidos, pero con todos los inconvenientes derivados de las irregularidades del sistema ortográfico. En principio, es indiferente partir de una representación ortográfica o fonética; en cualquier caso, al final del proceso se han de obtener sílabas fonéticas. Sin embargo, si consideramos que los sonidos se agrupan formando sílabas según las restricciones fonotácticas de la lengua, debemos crear reglas que marquen los límites entre sonidos y no entre letras. Se ha de partir de una representación fónica de la cadena y no de una representación ortográfica. La conversión de símbolos ortográficos a símbolos fonéticos ha de preceder a la silabación.
3.5.2. Metodología para la construcción del DEFE.
En este apartado describiremos los aspectos metodológicos de esta investigación.
(1) Aplicación de las reglas.
Cada regla ha sido planteada como una hipótesis que ha sido verificada en el sector del léxico sobre el que se aplica. La validez de una regla viene dada por su correcta aplicación en el grupo al que pertenece.
Una regla ha de dar cuenta de un hecho del que no da cuenta ninguna otra. El sistema de Laporte (1988) aplica simultáneamente el grupo de reglas que se defina, detecta los solapamientos entre reglas y crea un fichero en el que se indican los contextos exactos donde se producen. El contenido final de las reglas que generan el DEFE expresa la información fónica de la parte de la transcripción que realiza y la información sobre su interacción en el conjunto, y es el resultado de un proceso continuo de aplicación y de verificación, con las modificaciones necesarias del contenido que se hubiera planteado inicialmente.
(2) Formato del fichero de trabajo.
Hemos trabajado sobre una versión del DEFSFE sin información gramatical, es decir, sobre la representación ortográfica de los lemas. Cada uno aparece por duplicado en su línea correspondiente. La primera representación ortográfica se conserva sin cambios, y las reglas se aplican sobre la segunda, que se transformará en la transcripción en caracteres fonéticos de salida. Es más operativo que ambas representaciones sean adyacentes, así se puede contrastar de un modo fácil la aplicación de las reglas.
(3) Estudio de los contextos de aplicación de las reglas.
En el sistema de Laporte (1988) las reglas se aplican simultáneamente en cada módulo y se detecta de modo automático cuándo dos o más reglas dan cuenta del mismo fenómeno. Por ello ha sido necesario realizar un estudio exhaustivo de los contextos exactos de aplicación de cada regla. Hemos extraído automáticamente las palabras en las que se da cada uno de los fenómenos ortográficos y fonéticos estudiados y hemos creado los correspondientes subdiccionarios. El coste informático es menor si sólo se trabaja con aquella parte del léxico que se estudia. Las reglas se aplican en el subdiccionario pertinente.
(4) Etapas de trabajo.
Nuestra investigación se ha desarrollado en las siguientes etapas:
(4.1) Diseño general del sistema de transcripción.
(4.2) Diseño de las reglas de conversión grafema-fonema.
Hemos partido de un estudio de todos los contextos de aparición de los grafemas que nos ha permitido determinar su valor fónico en cada caso. En el diseño inicial, las reglas de este módulo podían tener una aplicación productiva (daban cuenta de contextos regulares del español, por ejemplo, la regla que transcribe el grafema g como [
x] en el contexto precedente a las vocales e, i ) o improductiva (daban cuenta de anomalías del sistema ortográfico, pero con una interpretación fónica regular, por ejemplo, las reglas que eliden la g en los contexto ngs (angstrom) y ng final (standing), y la regla que inserta una e ante s inicial silábica). El objeto era obtener una representación en caracteres fonéticos del léxico. Quedaban descartados de la fonetización por reglas de este módulo casos peculiares de extranjerismos que deben ser tratados ad hoc, por ejemplo, la transcripción de los grupos vocálicos de rousseauniano, además de toda palabra cuya pronunciación no puede ser de deducida de la ortografía, como en los casos de la w y los hiatos.(4.3) Aplicación y verificación de las reglas de conversión grafema-fonema.
Por ahorro del coste informático, primero se aplicaron por separado las reglas de cada una de las letras en los subdiccionarios correspondientes. En las reglas que se refieren a un mismo foco es donde se pueden producir solapamientos. La aplicación del conjunto de reglas sobre todo el diccionario se realizó una vez que se verificaron las aplicaciones parciales.
(4.4) Diseño, aplicación y verificación de las reglas de división silábica.
Partimos de un estudio de las agrupaciones de segmentos adyacentes, consonánticos y vocálicos. En una primera fase, las reglas se organizaron en subficheros referidos a un fonema, de forma que se estudiaban todos los límites existentes entre cada uno de ellos con todos los demás. En una segunda fase se buscaron reglas más generales, con un estudio para el tratamiento de las excepciones que desembocó en la creación del módulo de Reglas de ajuste silábico.
(4.5) Estudio de las excepciones a las reglas generales y de los casos poco productivos de la fonetización.
Determinamos la existencia de tres grandes tipos de excepciones:
(i) Contextos ortográficos no propios de la lengua española, pero que tienen una interpretación fónica regular. Son los casos, por ejemplo, de angstrom y standing, ya mencionados, y pueden ser tratados a través de reglas (las que conforman el módulo de Reglas de ajuste silábico).
(ii) Los hiatos no marcados ortográficamente. Se trata de una propiedad idiosincrásica que ha de ser marcada individualmente en cada palabra; de otro modo, en la medida en que no depende del contexto fonético, sería necesario un determinado número de reglas ad hoc o largas listas de excepciones. Hemos estudiado todas las palabras con grupos de vocales susceptibles de formar hiato y hemos determinado los principios generales que rigen el fenómeno. El hiato se ha marcado en las formas de base del DEFSE, previamente a la generación de las formas flexivas, por economía informática.
(iii) Extranjerismos con contextos de difícil sistematización y cuya poca productividad desaconseja la fonetización por reglas; se ha de hacer individualmente.
(4.6) Desarrollo del módulo de Reglas de ajuste silábico y modificaciones de las Reglas de transcripción grafema-fonema y de las Reglas de silabación, como ya hemos indicado, para adaptar el funcionamiento de los tres módulos.
(4.7) Diseño, aplicación y verificación del programa del acento.
También hemos indicado que el diseño del programa de acentuación nos obligó a hacer determinadas modificaciones en el orden de aplicación de las reglas de transcripción grafema-fonema.
(4.8) Estudio de los procesos fonológicos del español y diseño, aplicación y verificación de las reglas de transcripción fonema-alófono (también en ficheros parciales).
(4.9) Estudio de un conjunto de reglas de fonetización sintáctica para la aplicación del DEFE a la fonetización automática de textos.
§ 5.4.1.2.2.2); nos referiremos a 'sonidos ensordecidos'.1. Financiación actual del proyecto: Proyecto del Plan Nacional, CICYT - MEC. TIC 96-0804.
2. Utilizamos la aplicación que nos fue cedida por el profesor Eric Laporte, de la Université Paris VII. en el marco de un proyecto de investigación de Acción Integrada 1992.
3. El Laboratoire d’Automatique Documentaire et Linguistique (LADL) fue un organismo perteneciente al Centre National de la Recherche Scientifique (CNRS) adscrito a la Université Paris VII.
4. Entre los símbolos utilizados por Laporte (1988), [i] representa una vocal silábica y [j] una vocal no silábica.
5. A diferencia de lo que sucede en la sintaxis y en la morfología, las reglas fonológicas del español tienen una aplicación regular siempre que se cumplen sus condiciones de aplicación. Las excepciones se refieren a la pronunciación de los extranjerismos aún no normalizados y a la silabación (a lo que hemos denominado "anomalías del sistema ortográfico"). Por tanto, sólo será necesario indicar las unidades léxicas en las que no se aplican las reglas generales.
6. Sobre el mantenimiento o ruptura del hiato en las formas complejas sólo podemos afirmar que existen tendencias generales, dada la gran variación en el habla; lo veremos en el módulo de reglas de presilabación (cf. infra, § 6.8).
7. En este trabajo, al describir los fonemas y alófonos del español, haremos referencia a términos como 'habla enfática', 'habla rápida', 'habla coloquial', 'habla popular', 'habla familiar', 'habla corriente', 'habla vulgar', 'habla relajada' y 'habla espontánea' (en gran medida, están tomados de Navarro Tomás, 1918). No entraremos en una definición de los estilos de habla, tema de indudable complejidad (cf. Llisterri, 1992; Eskénazi, 1993; Aguilar y Machuca, 1994); con esos términos queremos referirnos a una pronunciación no cuidada –aun de los hablantes cultos– en la que se tiende a fenómenos de relajación, o de refuerzo (en el caso del habla enfática), en oposición a la dicción culta que transcribimos, que no deja de ser una idealización.
8. Desde el punto de vista técnico, esta parte del trabajo no hubiera podido ser llevada a cabo sin la colaboración y asesoramiento informático de Jordi Farjas, del Departament de Físiques de la Universitat Autònoma de Barcelona. Él les dio vida en la pantalla y en el papel. Gracias por su conciencia de objetor.
Y desde mi intelecto y mi corazón, es impagable la ayuda de mi colega Carme de la Mota, que ejerció de psicoanalista lingüístico para clarificar las cuatro ideas que corren por aquí durante un viaje por Polonia. Compartí con ella una comunicación (de la Mota y Ríos, 1996) sobre el problema que estamos tratando, que ha servido de base para esta redacción.
9. En este trabajo asumiremos que cónyuge no se pronuncia con sonido africado, sino con oclusivo. Lo justificamos en el apartado 5.4.7.1.10. En las descripciones fonéticas tradicionales del español, se considera que estos sonidos son fricativos; sin embargo, existen trabajos experimentales en los que se demuestra que se realizan como aproximantes (cf. supra, § 4.3.3); así los representamos en este trabajo.
11. Discutimos el concepto de "proceso alofónico" en el apartado 5.2.
12. Diferenciamos entre 'sonido palatal' (la realización palatal de un fonema palatal) y 'sonido palatalizado' (la realización alofónica, que resulta de un proceso de palatalización, de un fonema no palatal). Describimos la diferencia entre estos sonidos en el Capítulo 4 de este trabajo. Éste es el único caso en el que establecemos tal distinción, que carece de sentido en el resto de procesos alofónicos (labiodentalización, interdentalización, dentalización, velarización, sonorización, vibrantización), puesto que no existen las correspondientes oposiciones fonológicas (labiodental / labiodentalizado; interdental / interdentalizado; dental / dentalizado; velar / velarizado; sonoro / sonorizado; vibrante / vibrantizado). Un caso aparte es el proceso de ensordecimiento, puesto que lo definimos como 'ensordecimiento parcial' (cf. infra,
13. En este trabajo, nos referiremos a las vocales /i/ y /u/ (fonemas o alófonos) como 'cerradas' o 'altas', puesto que así consta en la bibliografía.
14.
Creemos que se ha de distinguir entre 'diptongación' y 'glidización' como dos procesos
diferenciados. Desde nuestro punto de vista, el primero hace referencia al proceso
morfofonológico que relaciona, por ejemplo, la vocal /e/ de tener con el
diptongo [ ![]() ] de tiene, o la vocal /o/ de poder
con el diptongo [
] de tiene, o la vocal /o/ de poder
con el diptongo [![]()
![]() ] de puedo; el segundo, a la realización
como semivocal o semiconsonante de un fonema vocálico caracterizado como no silábico, o
a la realización como vocal no silábica de un fonema vocálico silábico por pérdida de
su silabicidad: son los casos de sinéresis y de sinalefa: (maestra [
] de puedo; el segundo, a la realización
como semivocal o semiconsonante de un fonema vocálico caracterizado como no silábico, o
a la realización como vocal no silábica de un fonema vocálico silábico por pérdida de
su silabicidad: son los casos de sinéresis y de sinalefa: (maestra [![]()
![]() ], este hombre [
], este hombre [![]()
![]() ]).
]).
15. El ensordecimiento parcial de las aproximantes, como variación dependiente del contexto, ha de ser indicado en la transcripción. El problema es representarlo a través de un alfabeto de signos fonéticos. Navarro Tomás (1918), que menciona la alternancia entre una realización sorda y otra semisorda, utiliza el alfabeto de la RFE. La realización sorda se indica mediante un diacrítico de ensordecimiento aplicado bajo el que representa la aproximante, por ejemplo [