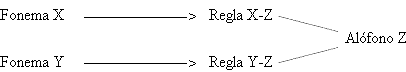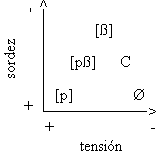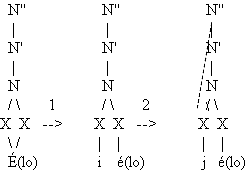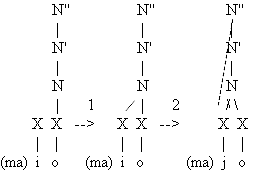| ISSN: 1139-8736 Depósito Legal: B-39200-99 |
5. Fonemas y alófonos del DEFE.
5.1. El concepto de fonema en el DEFE.
El concepto de fonema desarrollado por el
estructuralismo a partir de los presupuestos funcionalistas de Trubetzkoy tiene ciertas
limitaciones para la representación de los enunciados de una lengua mediante un alfabeto
de signos fonéticos, como es nuestro objetivo. Un fonema no se define aisladamente, sino
en función de los demás, por lo que se llega a desvirtuar la caracterización individual
si así lo exige la coherencia interna del sistema. Si un fonema no puede ser definido
mediante rasgos distintivos que contradigan los de sus variantes, ¿qué se ha de
representar, en el caso del español, cuando los rasgos [sordo / sonoro] no son
pertinentes en la caracterización de los fonemas fricativos /s/ y /![]() / o el par
[interrupto / continuo] en la de los fonemas clasificados tradicionalmente como oclusivos
sonoros?, ¿cómo representamos en una transcripción la no pertinencia de una determinada
característica fonológica? Un problema deriva de estas consideraciones: si cuestionamos
la validez de los principios teóricos con los que se ha establecido el repertorio de
fonemas, estamos cuestionando la validez de ese repertorio.
/ o el par
[interrupto / continuo] en la de los fonemas clasificados tradicionalmente como oclusivos
sonoros?, ¿cómo representamos en una transcripción la no pertinencia de una determinada
característica fonológica? Un problema deriva de estas consideraciones: si cuestionamos
la validez de los principios teóricos con los que se ha establecido el repertorio de
fonemas, estamos cuestionando la validez de ese repertorio.
Para determinar el repertorio de fonemas del DEFE necesitamos partir de un concepto que permita su representación. La dificultad podría evitarse si transformáramos la representación ortográfica del DEFSFE en una representación fonética, directamente, sin el paso intermedio de la representación fonémica, pero el sistema que proponemos tiene ciertas ventajas, como ya hemos indicado. A partir de una transcripción inicial (que hemos denominado "fonémica") podemos generar más de una representación fonética, ampliando o reduciendo los fonos elegidos; el DEFE no es un objeto cerrado en sí mismo, sino que está sujeto a las variaciones que se consideren pertinentes. Consideramos que nuestro sistema aporta una descripción del sistema fonológico del español que no encontramos en los sistemas creados hasta la fecha, a los que no negamos eficacia, pero que están concebidos como meros instrumentos para su aplicación en la síntesis del habla; el DEFE, en cambio, es un objeto de investigación fonológica.
El concepto de fonema del que partamos deberá tener en cuenta la estructura del sistema de transcripción del DEFE: una representación fonémica inicial que se relaciona con la representación fonética final a través de un conjunto de reglas, de ahí que no podamos desligar los segmentos que aparecen en la representación fonémica de los segmentos que se derivan de él y de las reglas que permiten la derivación.
Las reglas relacionan fonemas con alófonos, es decir, segmentos abstractos que constituyen los elementos primitivos de la representación con segmentos abstractos pronunciables. Nos referimos a "segmentos abstractos pronunciables" porque los sonidos transcritos no son, obviamente, "sonidos concretos", tal como los definió Daniel Jones (1950: 6): "A concrete sound is a physical thing, a sound actually uttered in a particular occasion", sino una abstracción que hacemos de la realidad del habla prescindiendo de las particularidades de la pronunciación del hablante en una situación comunicativa concreta1; y si en los alófonos derivados hacemos una abstracción de la realidad del habla, aquella concerniente al emisor, en el segmento abstracto primitivo de la representación también: prescindimos de aquellas características de los sonidos que están condicionadas por el contexto, es decir, de la variación contextual. Las reglas de transcripción fonema-alófono describen las relaciones que mantienen los sonidos en la organización del enunciado y explicitan dicha variación, que ha de ser considerada como el resultado de la aplicación de un determinado proceso fonológico. El conjunto de segmentos abstractos pronunciables que se derivan de un mismo segmento abstracto primitivo constituyen un grupo de sonidos emparentados: poseen una serie de características fonéticas comunes y se diferencian por el resultado de la variación contextual.
De la disquisición anterior se deduce que concebimos el fonema como un segmento en el que se ha hecho abstracción de las particularidades de la pronunciación del hablante y de la variación debida al contexto; ha de ser considerado como el representante de un conjunto de sonidos abstractos pronunciables emparentados, sus alófonos, con los que se vincula a través de las reglas que dan cuenta de la variación contextual.
Debemos constatar la semejanza de nuestra concepción del fonema con la de Jones (1950):
"Viewed from the physical angle, a phoneme is a family of uttered sounds (segmental elements of speech) in a particular language which count for practical purposes as if they were one and the same; the use of each member of the familiy (allophone) is conditioned by the phonetic environment" (p. 258).
"[...] a phoneme is a family of sounds in a given language which are related in character and are used in such a way that no one member ever occurs in a word in the same phonetic context as any other member" (p. 10).
También el Principio 7 del AFI (IPA, 1959: 4) define el fonema en términos semejantes:
"Phonemes are thus families of related sounds which count linguistically in a given lenguage as if they were one".
Para nosotros el fonema no es la familia de sonidos en sí, sino el segmento que la representa en la transcripción. Jones (1950: 8) hace referencia a un miembro que ha ser considerado el más importante de cada grupo y a la relación que el resto de sonidos mantienen con él:
"When a phoneme comprises more than one member, it generally happens that one of the sounds seems more important than the other(s). This may be because it is commoner than the other(s), or because it is the one used in isolation, or because it is intermediate between extreme members. Such a sound may be termed the principal member or norm of the phoneme. The other sounds in the same phoneme may be called subsidiary members or subsidiary allophones. Subsidiary members have also been termed divergents and sub-phonemic variants".
Desde nuestro punto de vista, las indicaciones de Jones sobre ese sonido son insuficientemente precisas y de dudosa utilidad.
Creemos que por "más común" se ha de
interpretar "aquel segmento con mayor frecuencia de uso". Aunque podamos prever,
por la distribución de los sonidos en la cadena, que una determinada variante aparecerá
en un mayor número de ejemplos, es algo que no se puede establecer con absoluta seguridad
sin un estudio estadístico. Siguiendo este criterio, al elegir entre los alófonos
oclusivos [b], [d], [g] o aproximantes [![]() ], [
], [![]() ], [
], [![]() ] deberíamos decidirnos por los segundos, pues son los
más frecuentes, como han señalado Canellada y Madsen (1987:39). La cuestión es si el
argumento de frecuencia de uso es fonológicamente relevante para ser tenido en cuenta.
] deberíamos decidirnos por los segundos, pues son los
más frecuentes, como han señalado Canellada y Madsen (1987:39). La cuestión es si el
argumento de frecuencia de uso es fonológicamente relevante para ser tenido en cuenta.
El aislamiento de los sonidos del habla no parece un criterio apropiado para determinar, entre las distintas variantes, el segmento que ha de constar en una transcripción. Los sonidos del habla se agrupan en un continuo sonoro formando mensajes. Es cierto que podemos emitirlos aislados, pero en un contexto natural sólo podríamos pronunciar las vocales, por ejemplo, en algunas interjecciones, en la mención de las conjunciones e, y, o, u, y de los nombres de las letras (en el uso metalingüístico, las palabras tienden a pronunciarse aisladas):
¡Ah!, tú sabrás lo que haces.
¡Eh!, ven aquí.
La conjunción copulativa «e» es una variante de «y» ante palabras que empiezan por vocal «i».
La conjunción disyuntiva «u» es una variante de «o» ante palabras que empiezan por vocal «o».
La letra «a» es la primera del alfabeto.
Transcribir el segmento intermedio entre los miembros extremos es una elección ecuánime, pero arbitraria desde el punto de vista fonológico. Por ejemplo, entre los distintos alófonos nasales que resultan de las asimilaciones al punto de articulación de la consonante siguiente, ¿cuál consideramos como intermedio para ser representado?, ¿el dental, que se sitúa en el centro de los siete puntos articulatorios?:
bilabial |
labiodental |
interdental |
dental |
alveolar |
palatal |
velar |
En algunas agrupaciones nos resulta imposible establecer el segmento intermedio, por ejemplo, en los alófonos descritos del fonema /s/: fricativo alveolar sordo [s] (asa), fricativo alveolar sonoro [z] (asno) y fricativo dental sordo [
Posiblemente, no sea lícito hablar de miembros extremos e intermedios de una familia de sonidos, a menos que todas las variantes consideradas sean las realizaciones de un mismo proceso fonológico gradual que permita determinar claramente esas categorías. En el caso de los alófonos de /s/ actúan dos procesos fonológicos distintos, la asimilación del punto de articulación de la consonante siguiente y la asimilación de su sonoridad, de ahí la dificultad para aplicar el criterio de la posición. Tampoco podríamos aplicarlo cuando sólo haya dos variantes.
Si analizamos la serie de sonidos vocálicos y consonánticos palatales podemos observar las contradicciones que pueden surgir de la aplicación de los distintos criterios mencionados por Jones. Los sonidos de esa serie están fonéticamente emparentados, como se puede observar en las distintas realizaciones de la conjunción y descritas por Alarcos (1965: 154) a las que ya hemos hecho referencia. Podemos defender un proceso de consonantización en el que los alófonos se ordenan gradualmente (indicamos las distintas realizaciones que constan en la bibliografía):
| vocal [i] / glide [ |
aproximante [j] -----------> | oclusiva [ |
| fricativa [ |
africada [ ] ] |
Entre los alófonos más abiertos —vocales y glides— y los más cerrados —las consonantes oclusiva o africada— se sitúan las realizaciones aproximante o fricativa. Según el criterio del segmento intermedio, uno de estos dos últimos sonidos es el que debería constar en la transcripción (aquél que decidamos que se realiza), pero si adoptamos el del aislamiento, la representación fonémica de la conjunción y ha de ser la vocal /i/.
En la transcripción del DEFE, para elegir el representante de cada grupo de sonidos pronunciables emparentados necesitamos seguir un criterio objetivo que sea coherente con el concepto de fonema que hemos definido. Si en el fonema abstraemos la variación contextual especificada en los alófonos a través de las reglas, el segmento que ha de constar como elemento primitivo de la representación será aquél no marcado por el contexto, es decir, el segmento sobre el que no se aplicará ninguna regla porque se realiza en una posición que consideramos no marcada por la variación contextual2. Para determinar esa posición deberemos analizar el conjunto de alófonos que transcribamos.
Hemos presentado un concepto formal de fonema, que
antepone los aspectos físicos del habla a los mentalistas y a los funcionalistas. No
negamos el carácter de representación mental del fonema, que sea "el equivalente
psíquico de los sonidos del lenguaje", como lo definió Baudouin de Courtenay (cf.
Trubetzkoy, 1973: 35), pero ésta es una concepción más propia de la psicología que de
la lingüística. Tampoco negamos el carácter de unidad distintiva del fonema, es una
asunción comúnmente aceptada que no rechazaremos; pero, siguiendo a Daniel Jones (1950:
265), se ha de diferenciar entre lo que el fonema "es" y lo que el fonema
"hace". El fonema es una unidad abstracta que el lingüista utiliza en los
análisis y en la descripción de las lenguas. En una fonología funcionalista, el fonema
es lo que hace; en una fonología concebida como formalización de las realizaciones
fonéticas, su definición no puede sustraerse de los sonidos del habla que representa.
Antes de proceder a la prueba de la conmutación para determinar el carácter distintivo
de una unidad se ha de establecer el repertorio de fonemas formalizando la realidad
fónica, porque la aplicación de dicha prueba está condicionada por los segmentos
conmutados. Por ejemplo, si afirmamos que los diptongos son unidades vocálicas
monofonemáticas, podemos encontrar pares mínimos que lo justifiquen, como hueso
/'![]() e.so/
- oso /'o.so/; en cambio, la conmutación no es posible si consideramos que
el diptongo es una unidad vocálica difonemática o que los dos sonidos iniciales de hueso
forman una secuencia de /consonante + vocal/, /we/.
e.so/
- oso /'o.so/; en cambio, la conmutación no es posible si consideramos que
el diptongo es una unidad vocálica difonemática o que los dos sonidos iniciales de hueso
forman una secuencia de /consonante + vocal/, /we/.
El concepto del que partimos para establecer el repertorio de fonemas del DEFE, que proponemos como repertorio de fonemas del español, permite representar los enunciados de la lengua mediante un alfabeto de signos fonéticos y evita los problemas que hemos señalado al comentar el enfoque estructuralista en el Capítulo 4 de este trabajo:
(1) Los fonemas del DEFE no se definirán en función de los demás, como en los presupuestos de Trubetzkoy, sino en función de los alófonos que de ellos se deriven. La caracterización individual de los segmentos estará supeditada a la realidad fónica, de la que el fonema es una abstracción, y no a la coherencia interna del sistema.
(2) Las características que definan un fonema serán las mismas que definan uno de sus alófonos, sin atender a situaciones contradictorias en la caracterización de ambos tipos de segmentos.
(3) Si tomamos como fonemas los sonidos de los que abstraemos la variación individual y contextual, las definiciones mediante términos articulatorios no constituirán un cuadro fonético de fonemas, como critica Martínez Celdrán (1989: 76, n. 3), sino que reflejarán el resultado de la abstracción que se haya realizado.
Nuestro concepto de fonema es incompatible con el de archifonema estructuralista, ya que debemos transcribir un segmento concreto, la variante que consideramos no marcada. La neutralización será la confluencia en un mismo sonido de las realizaciones de dos o más fonemas; tales realizaciones deberán darse en el mismo contexto silábico. En nuestro sistema de fonetización quedará formalizada a través de las reglas de transcripción fonema-alófono, como se muestra en la Figura 3:
Figura 3: La neutralización en el DEFE.
|
Nuestro sistema de transcripción tiene un claro paralelismo con la formulación inicial de la fonología generativa, aunque nuestro trabajo no se inscriba en dicha escuela: partimos de una representación subyacente sobre la que se aplican un conjunto de reglas que generan la representación fonética final. Tanto la gramática léxica, en la que se inserta nuestro trabajo, como el generativismo intentan explicar la competencia lingüística del hablante; nosotros nos centramos en el conocimiento sobre la pronunciación de su lengua. No obstante, existe una diferencia esencial entre la transcripción fonémica del DEFE y la representación subyacente de la fonología generativa. Como señalan D'Introno et al. (1995: 320), para ésta la noción de fonema se hace irrelevante y las reglas operan sobre rasgos y no sobre fonemas; en el DEFE no se especifican matrices de rasgos, sino un signo que remite a una caracterización articulatoria de los segmentos (modo y punto de articulación, y vibración de las cuerdas vocales: [sordo / sonoro]) que hemos considerado representantes de cada grupo de sonidos abstractos pronunciables emparentados. Las representaciones subyacentes de la fonología generativa no siempre tienen en cuenta la realidad fónica, un ejemplo de ello es el caso de la vibrante geminada que Harris (1991) propone para derivar la vibrante múltiple intervocálica; discutiremos este problema en el apartado 5.4.4.3, pero nuestra principal objeción es que ese segmento geminado subyacente no tiene ningún fundamento en la realidad del habla. Si la fonología ha de formalizar el conocimiento que el hablante tiene de la pronunciación de su lengua, la representación de una vibrante subyacente carece de sentido en español, porque creemos que ese segmento no está en la competencia de los hablantes.
5.2. Los segmentos fónicos y su representación.
Tradicionalmente se establece una distinción entre representación fonética y representación fonológica, que están asociadas a los segmentos representados (sonidos y fonemas) y a las disciplinas de las que éstos son objeto de estudio (Fonética y Fonología). Las palabras de Anderson (1985: 263) son ilustrativas de esta concepción:
"Virtually all views of sound structure have assumed that utterances can be represented in (at least) two distinct ways, each with its own importance. One of these is a phonemic (or phonological) representation, which indicates the properties of the form that differentiate it from other forms in the same language; and another is a phonetic representation, which indicates in an objective, language-independent way how the form is pronounced"3.
En nuestro trabajo, los conceptos de "sonido concreto" (o "fono", realmente pronunciado), "segmento abstracto pronunciable" (o "alófono") y "representante de los sonidos abstractos pronunciables emparentados" (o "fonema") nos obligan a replantear la distinción tradicional. Si establecemos la existencia de tres tipos distintos de segmentos, debemos proponer tres representaciones:
(1) Representación fonética.
Es la representación mediante fonos, la de los enunciados realmente pronunciados por el hablante.
(2) Representación alofónica.
Es la representación mediante alófonos, en los que hemos abstraído las peculiaridades provenientes del hablante en una situación comunicativa concreta. En ella sólo se refleja la variación contextual.
(3) Representación fonémica.
Es la representación mediante fonemas, en los que hemos abstraído las peculiaridades del hablante y la variación contextual.
Las tres representaciones se conectarán entre sí mediante reglas que formalicen las diferencias existentes entre ellas; las tres constituirán la representación fonológica, entendida como la representación del conocimiento que el hablante tiene de la pronunciación de su lengua, puesto que todas la representan, cada una con un distinto grado de abstracción. Mostramos esta propuesta en la Figura 4:
Figura 4: La representación fonológica como conjunto de las representaciones fonémica, alofónica y fonética.
Representación fonológica
|
Las reglas que conectan las tres representaciones formalizan un determinado proceso, entendido como la modificación que experimentan los segmentos.
Machuca (1997: 25-29) distingue entre procesos fonológicos y procesos fonéticos; parte de un análisis en el que sistematiza los factores descritos en la bibliografía que pueden producir variaciones en la señal de habla: existen factores lingüísticos (el contexto fónico, la estructura silábica, el acento y la categoría gramatical de la palabra) y factores extralingüísticos; éstos pueden ser dependientes del hablante (las características anatómicas del aparato fonador, el sexo, la edad, el estado de ánimo, la velocidad de elocución propia, la variedad geográfica de habla y las características socioculturales) o dependientes del uso que el hablante hace de su lengua (la intención, el contexto social y la relación entre el hablante y el oyente). Machuca entiende por procesos fonológicos aquellas variaciones de la señal provocadas por factores lingüísticos; estos procesos se puede hacer extensivos a la mayoría de los hablantes, por ejemplo: el debilitamiento de las obstruyentes continuas, la sonorización de /s/ ante consonante sonora y las asimilaciones de /n/ al punto de articulación de la consonante siguiente. Los procesos fonéticos son las variaciones provocadas por factores extranlingüísticos.
Los factores de variación que distinguen ambos tipos de procesos coinciden con los que nos han permitido establecer los distintos segmentos de la transcripción; sin embargo, siendo coherentes con la nomenclatura, debemos diferenciar entre 'procesos alofónicos', la formalización de las variaciones dependientes del contexto (de los factores lingüísticos), y 'procesos fonéticos', la formalización de las variaciones dependientes del hablante y de la situación comunicativa (de los factores extralingüísticos). Ambos procesos son 'fonológicos', puesto que formalizan las diferencias existentes entre los segmentos de la representación fonológica.
El conjunto de artículos reunidos en el volumen 18,3 del Journal of Phonetics (Beckman, 1990) indagan en el concepto de representación fonética, desde distintos puntos de vista.
Para Ladefoged (1990), desde una perspectiva pragmática, una representación fonética es una herramienta descriptiva práctica para los análisis lingüísticos. Browman y Goldstein (1990) abordan el concepto desde la producción del habla: se ha de representar la organización de las acciones físicas implicadas en ella; las unidades de la representación fonética son los gestos articulatorios, definidos dinámicamente. Neary (1990) enfatiza los aspectos perceptivos: una representación fonética es una representación cognitiva de la percepción del habla. Estos trabajos ponen en evidencia la necesidad de establecer el dominio de la representación, como indican Nolan (1990) y Rischel (1990): la producción, la acústica o la percepción, como dominios individuales o interconectados. Pierrehumbert (1990) mantiene un punto de vista tradicional al distinguir entre una representación fonológica, cognitiva y cualitativa, y una representación fonética, no cognitiva y cuantitativa. La representación fonética da cuenta de los fenómenos que existen en el mundo físico, se pueden observar en los análisis instrumentales del habla y se pueden implementar en la síntesis. La representación fonológica se relaciona con lo fonética a través de reglas que realizan determinadas abstracciones de la señal de habla.
Nuestra propuesta se asemeja a la de Keating (1990). La autora enfoca los conceptos de representación fonológica y fonética desde los presupuestos de la gramática generativa, una diferencia radical con nuestro trabajo, pero establece varios niveles.
Distingue tres tipos de representación fonética:
(1) Una representación fonética categorial, que es la salida de la fonología, es decir, una representación fonológica derivada de una representación subyacente. Esta representación se define en términos de rasgos binarios. Es categorial porque expresa las diferencias –no distintivas– entre los miembros de una misma categoría fonológica.
(2) Una representación paramétrica articulatoria
(3) Una representación paramétrica acústica.
Las dos últimas representaciones fonéticas corresponden a representaciones "físicas" del habla. Son paramétricas porque no se definen en términos de rasgos sino de parámetros físicos, articulatorios y acústicos. Ambas se sitúan en un mismo nivel y pueden derivarse de la representación fonética categorial; queda representado en el siguiente esquema (cf. Keating, 1990: 324):
Fonología
|
Representación fonética categorial
| |
Representación paramétrica articulatoria Representación paramétrica acústica
No obstante, expresan relaciones distintas en cuanto a la dualidad hablante-oyente: los hablantes usarían la representación categorial para llegar a la articulatoria, los oyentes, para llegar a la acústica.
Reflexiona también la autora sobre el concepto de alófono: si por alófono se entiende 'subfonémico', los alófonos aparecerían en las tres representaciones fonéticas, pero prefiere circunscribirlo al segmento de la representación categorial.
Existe un claro paralelismo entre la propuesta de Keating y la nuestra. No entraremos en la discusión de cómo ha de ser una representación fonética, en el sentido con que la hemos definido: en el DEFE no transcribimos emisiones reales de habla, y deberá ser la investigación experimental la que decida los términos en que éstas deben representarse, pero los parámetros articulatorios y acústicos son observables mediante instrumentos y caracterizan a las realizaciones del habla. Debemos señalar una diferencia, Keating distingue entre representación fonológica (la subyacente) y representaciones fonéticas; para nosotros, todas las representaciones son fonológicas, puesto que todas explican un conocimiento del hablante: la pronunciación de su lengua, pero lo formalizan con un distinto grado de abstracción. Evidentemente, desde nuestro punto de vista, esta propuesta aboga por una integración de los tradicionales estudios fonéticos y fonológicos: los primeros han de proporcionar datos empíricos con los que construir hipótesis explicativas de los fenómenos del habla (el resultado de los experimentos de laboratorio carecen de sentido como mera recolección de datos) y los segundos deben construir hipótesis que puedan ser estudiadas empíricamente (ninguna teoría fonológica tiene sentido si no se puede validar en el laboratorio). Esta idea no es nueva en los estudios lingüísticos; en nuestro ámbito académico, los trabajos de Aguilar (1994) y Machuca (1997) se incriben en una línea de investigación interdisciplinar fonético-fonológica. Indica Ohala (1991), a propósito de la relación entre Fonética y Fonología, que ambas tratan de entender el mismo fenónemo: el habla, y su colaboración ha de contribuir a encontrar las respuestas a los problemas comunes. En nuestro trabajo no incluiremos experimentos fonéticos propios que validen las relaciones entre los fonemas y los alófonos que establezcamos en la transcripción del DEFE (tarea imposible analizar todo el sistema fonológico de la lengua española), pero recogeremos problemas y datos que han de permitir futuros estudios experimentales.
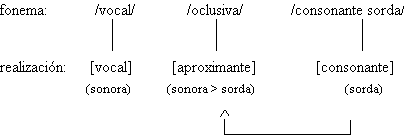
Ejemplificamos la representación fonológica que hemos definido con algunos de los datos del trabajo de Aguilar et al. (1993), en el que estudian los procesos de reducción en el habla espontánea del español. El corpus consiste en cuatro entrevistas a cuatro informantes (R., I., J.C. y P.L.). En dos de ellas –las realizadas a R. e I.– el entrevistador tiene una relación interactiva con el entrevistado (han de ser consideradas diálogos); mientras que en las otras dos –las realizadas a J.C. y P.L.– el entrevistador sólo interviene, brevemente, cuando el entrevistado ha acabado su locución (han de ser consideradas monólogos). Mostramos los casos de los fonemas oclusivos sordos en posición intervocálica y de los fonemas oclusivos sonoros también en posición intervocálica y tras nasal. En el primer caso, la bibliografía del español describe alófonos oclusivos sordos, el contexto no influye en la realización alofónica; sin embargo, en el habla espontánea, los hablantes también realizan oclusivas implosivas, oclusivas sonoras, aproximantes y elisiones, como resultado de un proceso gradual de debilitamiento, o 'lenición' (desde la no lenición, en los sonidos oclusivos sordos, hasta el máximo grado, con la elisión de la consonante). En el caso de los fonemas oclusivos sonoros tras nasal, la bibliografía tampoco describe variación alofónica, pero en el habla espontánea los informantes realizan variantes oclusivas sonoras, aproximantes y elisiones, también en un proceso gradual de lenición. Las oclusivas sonoras en posición intervocálica están sujetas a variación alófonica, se realizan como aproximantes, pero en el habla espontánea también pueden producirse elisiones. Para todos los casos, el comportamiento no es uniforme, cambia entre los informantes y en la distinta situación comunicativa (monólogo-diálogo), con un porcentaje variable. En una transcripción fonética, la de los enunciados realmente emitidos, constarán los sonidos pronunciados; sin embargo, las realizaciones oclusivas sonoras y las aproximantes, por ejemplo, no pueden ser consideradas alófonos de los fonemas oclusivos sordos, porque no dependen del contexto en sí, sino de la elección individual del hablante: en el habla cuidada, sin relajación, se realizarían los sonidos oclusivos sordos, que son los determinados por el contexto. Lo mismo sucede en los otros casos comentados.
En la Tabla 13 mostramos la representación fonológica de los ejemplos descritos; en la sección de la representación fonética, con los signos « + » y « - » se indica, respectivamente, la realización y no realización del sonido por los hablantes.
Tabla 13: Ejemplos de los segmentos en una representación fonológica (datos de Aguilar et al., 1993: 434-435).
Represent. Fonémica |
Contexto |
Proceso Alofónico |
Represent. Alofónica |
Proceso Fonético |
Representación Fonética |
diál |
ogo | monó |
logo |
R. |
I. |
J.C. |
P.L. |
||||||
| oclusivo bilabial sordo |
V __ V |
(ninguno) |
oclusivo bilabial sordo |
- lenición + |
oclusivo bilabial sordo |
+ |
+ |
+ |
+ |
implosivo bilabial |
+ |
+ |
+ |
+ |
|||||
oclusivo bilabial sonoro |
+ |
+ |
+ |
+ |
|||||
aproximante bilabial |
+ |
+ |
- |
+ |
|||||
Ø (elisión) |
+ |
- |
- |
- |
|||||
| oclusivo dental sordo |
V __ V |
(ninguno) |
oclusivo dental sordo |
- lenición + |
oclusivo dental sordo |
+ |
+ |
+ |
+ |
implosivo dental |
+ |
+ |
+ |
+ |
|||||
oclusivo dental sonoro |
+ |
+ |
+ |
+ |
|||||
aproximante dental |
+ |
+ |
+ |
+ |
|||||
Ø (elisión) |
+ |
- |
- |
- |
|||||
| oclusivo velar sordo |
V __ V |
(ninguno) |
oclusivo velar sordo |
- lenición + |
oclusivo velar sordo |
+ |
+ |
+ |
+ |
implosivo velar |
+ |
+ |
+ |
+ |
|||||
oclusivo velar sonoro |
+ |
+ |
+ |
+ |
|||||
aproximante velar |
+ |
+ |
+ |
+ |
|||||
Ø (elisión) |
+ |
- |
- |
- |
|||||
| oclusivo bilabial sonoro |
nasal __ |
(ninguno) |
oclusivo bilabial sonoro |
- lenición + |
oclusivo bilabial sonoro |
+ |
+ |
+ |
+ |
aproximante bilabial |
+ |
- |
- |
- |
|||||
Ø (elisión) |
- |
+ |
- |
- |
|||||
V __ V |
lenición |
aproximante bilabial |
lenición + |
aproximante bilabial |
+ |
+ |
+ |
+ |
|
Ø (elisión) |
+ |
+ |
+ |
+ |
|||||
| oclusivo dental sonoro |
nasal __ |
(ninguno) |
oclusivo dental sonoro |
- lenición + |
oclusivo dental sonoro |
+ |
+ |
+ |
+ |
aproximante dental |
+ |
+ |
- |
- |
|||||
Ø (elisión) |
+ |
+ |
+ |
+ |
|||||
V __ V |
lenición |
aproximante dental |
lenición + |
aproximante dental |
+ |
+ |
+ |
+ |
|
Ø (elisión) |
+ |
+ |
+ |
+ |
|||||
| oclusivo velar sonoro |
nasal __ |
(ninguno) |
oclusivo dental sonoro |
- lenición + |
oclusivo velar sonoro |
+ |
+ |
+ |
+ |
aproximante velar |
+ |
+ |
- |
- |
|||||
Ø (elisión) |
+ |
+ |
+ |
+ |
|||||
V __ V |
lenición |
aproximante velar |
lenición + |
aproximante velar |
+ |
+ |
+ |
+ |
|
Ø (elisión) |
+ |
+ |
+ |
+ |
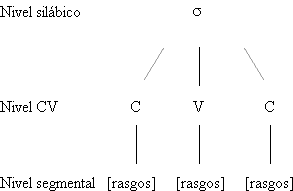
Para determinar los segmentos no marcados por el
contexto se han de tener en cuenta la posición de los sonidos en la sílaba y las
relaciones de adyacencia que mantienen entre sí, ya que son los factores que determinan
la variación. En el español, las consonantes y las vocales forman paradigmas
perfectamente diferenciados por su distribución silábica, de ahí que deban ser
estudiadas separadamente; únicamente pondremos en relación los segmentos vocálicos y
consonánticos de las series palatal y velar, por los problemas que presenta la
bibliografía para su adscripción fonemática: en la serie palatal, la glide [![]() ], la vocal
silábica [i], la aproximante [j], la fricativa [
], la vocal
silábica [i], la aproximante [j], la fricativa [![]() ], la oclusiva la [
], la oclusiva la [![]() ] y la africada
[];
en la serie velar, la glide [
] y la africada
[];
en la serie velar, la glide [![]() ], la vocal silábica [u], las aproximantes [w] y [
], la vocal silábica [u], las aproximantes [w] y [![]() ] y la oclusiva
[g].
] y la oclusiva
[g].
También debemos tener en cuenta que nuestro objetivo es transcribir un diccionario de formas flexivas y de distinta complejidad formal (palabras simples, derivadas y compuestas), es decir, las palabras tal como aparecen en los enunciados que emitirían los hablantes. Por tanto, debemos contemplar las relaciones que los sonidos mantienen dentro de la palabra y en el enlace entre palabras. Teniendo en cuenta que los sonidos del habla se realizan en un continuo sonoro, debemos partir de la hipótesis de que no habrá diferencias entre ambos tipos de relaciones; si las hubiera, sería por condicionamientos morfológicos particulares de la unidad léxica. Por ejemplo, el prefijo /in-/ tiene tres alomorfos: [in-], ante vocal y consonante distinta a bilabial y líquida; [im-], ante consonante bilabial; e [i-], ante consonante líquida. La nasal asimila su punto de articulación al de la consonante siguiente, tanto en interior de palabra como en el enlace entre palabras, pero nunca se elide: el proceso fonológico de elisión que explica la existencia del alomorfo [i-] está condicionado morfológicamente en las unidades léxicas formadas con este prefijo. No sucede lo mismo con el prefijo /kon-/, que también tiene tres alomorfos: [kon-], [kom-] y [ko-]; la elisión de la nasal en este último no tiene el comportamiento regular que observamos en /in-/, dada la existencia de palabras como coautor, conloar, conllevar, conreinar, correinado, correinante. Otro proceso fonológico condicionado morfológicamente es la diptongación en /'ie/ de la vocal /'e/, que afectaría, por ejemplo, a la flexión verbal: no se aplica en todos los verbos (se da en tener y no en temer), ni en todas las formas de un mismo verbo (tengo, tienes). La fonología puede formalizar los casos de alomorfia y la irregularidad de los paradigmas verbales, pero su actuación está condicionada por la existencia de una propiedad idiosincrásica de la unidad léxica4. Las reglas fonológicas condicionadas por la morfología se aplican en la palabra, no en el enlace entre palabras, y no tienen una aplicación regular en todo el léxico; en cambio, las reglas fonológicas no condicionadas morfológicamente tienen una aplicación regular y actúan en el interior de palabra y en el enlace entre palabras.
También puede haber condicionamientos sintácticos y semánticos que modifiquen las relaciones de adyacencia entre los segmentos y que bloqueen la realización de un determinado proceso. Pensamos en el fenómeno de la juntura, que evitaría, por ejemplo, la resilabación en las secuencias formadas por una consonante final palabra y una vocal inicial de la palabra siguiente cuando se puedan producir ambigüedades, o la coalescencia de dos consonantes en el enlace entre palabras, por el mismo motivo. Así, la pronunciación del sintagma las salas coincidiría con la de las alas si se produce la resilabación y la fusión de las fricativas (dos procesos generales en la lengua estándar); para evitar la ambigüedad, el hablante puede optar por marcar el límite silábico en el límite entre palabras5:
las salas : /la.'sa.las/ - /las.'sa.las/
las alas : /la.'sa.las/ - /las.'a.las/
Los condicionamientos sintácticos y semánticos que modifican las relaciones de adyacencia entre los segmentos fónicos son difícilmente predecibles y se apartan de nuestro objetivo: el estudio de la fonología en el léxico, por lo que no los tendremos en cuenta; para determinar los fonemas y alófonos del DEFE, asumiremos un comportamiento regular de los procesos alofónicos en el interior de palabra y en el enlace entre palabras6.
La mayoría de los problemas del sistema fonológico del español que hemos descrito en el resumen bibliográfico del Capítulo 3 han de ser analizados separadamente, pero podemos hacer algunas generalizaciones sobre la posición no marcada por la variación contextual.
Para las consonantes, la posición final de sílaba
está marcada por el debilitamiento, y es allí donde se producen las asimilaciones de
sonoridad y de punto de articulación descritas para el español. Los alófonos que se
realizan en ese contexto han de ser descartados como segmentos de la transcripción
fonémica del DEFE. La posición de ataque silábico ha de ser la no marcada para
transcribir las consonantes, pero se ha de tener en cuenta que en ella pueden producirse
fenómenos de refuerzo que incidan en la caracterización de los fonemas clasificados
tradicionalmente como oclusivos sonoros /b/, /d/ y /g/ y fricativo palatal sonoro /![]() /, y en la
inclusión de la aproximante labiovelar /w/ como fonema del español. Deberemos decidir si
tomamos como no marcado el ataque silábico en posición inicial absoluta o en posición
interior de palabra, en la cual las realizaciones de los segmentos han de coincidir con
las de interior de grupo fónico.
/, y en la
inclusión de la aproximante labiovelar /w/ como fonema del español. Deberemos decidir si
tomamos como no marcado el ataque silábico en posición inicial absoluta o en posición
interior de palabra, en la cual las realizaciones de los segmentos han de coincidir con
las de interior de grupo fónico.
Para las vocales, la posición no marcada ha de ser la del núcleo silábico. Discutiremos el carácter fonemático de los diptongos y de las glides en apartados específicos. Además, debemos decidir si transcribimos los alófonos vocálicos clasificados tradicionalmente en el español a partir de la descripción de Navarro Tomás (1918): vocales relajadas, abiertas, cerradas, nasales y orales.
5.4. Fonemas y alófonos consonánticos.
5.4.1.1. Consonantes oclusivas en el ataque silábico.
No hay problemas en la caracterización fonemática
de las consonantes oclusivas sordas.en el ataque silábico: se realizan únicamente cuatro
segmentos, bilabial [p], interdental [t+] y dental [t] y velar [k]. El sonido oclusivo
interdental sordo se realiza tras consonante interdental fricativa sorda, como describe
Navarro Tomás (1918: § 97): "Cuando la ![]() va inmediatamente seguida de una t,
la articulación de ésta se forma también entre los dientes, manteniéndose la lengua en
la misma posición de la
va inmediatamente seguida de una t,
la articulación de ésta se forma también entre los dientes, manteniéndose la lengua en
la misma posición de la ![]() , sin otra diferencia que la de aumentar un poco la
fuerza del contacto de la lengua contra el borde de los incisivos, de modo que durante un
instante se interrumpa por completo la salida del aire. El sonido de la t
(interdental), como el de la t normal, termina con explosión. Si el contacto entre
ambos sonidos no es suficientemente estrecho, la t recobra su articulación
propia". Este alófono se pronuncia tanto en el interior de palabra como en el enlace
entre palabras; por ejemplo, hazte allá, [
, sin otra diferencia que la de aumentar un poco la
fuerza del contacto de la lengua contra el borde de los incisivos, de modo que durante un
instante se interrumpa por completo la salida del aire. El sonido de la t
(interdental), como el de la t normal, termina con explosión. Si el contacto entre
ambos sonidos no es suficientemente estrecho, la t recobra su articulación
propia". Este alófono se pronuncia tanto en el interior de palabra como en el enlace
entre palabras; por ejemplo, hazte allá, [![]() .t+]; con una cruz tan
pesada [
.t+]; con una cruz tan
pesada [![]() .t+].
Evidentemente, se trata de una variante, marcada por el contexto, del fonema dental /t/.
.t+].
Evidentemente, se trata de una variante, marcada por el contexto, del fonema dental /t/.
Los fonemas oclusivos sordos son los tres tradicionalmente considerados en el español: /p/, /t/ y /k/. El problema reside en la caracterización de los segmentos sonoros de esta serie.
Los alófonos oclusivos sonoros
[b], [d] y [g] y los aproximantes [![]() ], [
], [![]() ] y [
] y [![]() ] se realizan en posición inicial de sílaba, tanto en
la palabra aislada como en el decurso, por lo que en principio no existe un criterio
objetivo que nos permita decidir qué segmentos han de constar en la transcripción
fonémica como representantes de estas familias de sonidos emparentados. Hay una
diferencia en la distribución de ambos tipos de variantes: en posición inicial absoluta
sólo se realizan las oclusivas, mientras que en posición interior de grupo fónico (ya
sea inicial o interior de palabra) se pueden realizar las oclusivas y las aproximantes;
pero en esta diferencia distribucional no encontramos ningún argumento que nos permita
establecer qué variante tomamos como fonema: en ambos casos la realización alofónica
depende del contexto. El criterio de mayor frecuencia de uso —haría que nos
decidiésemos por las aproximantes— tampoco nos parece conclusivo.
] se realizan en posición inicial de sílaba, tanto en
la palabra aislada como en el decurso, por lo que en principio no existe un criterio
objetivo que nos permita decidir qué segmentos han de constar en la transcripción
fonémica como representantes de estas familias de sonidos emparentados. Hay una
diferencia en la distribución de ambos tipos de variantes: en posición inicial absoluta
sólo se realizan las oclusivas, mientras que en posición interior de grupo fónico (ya
sea inicial o interior de palabra) se pueden realizar las oclusivas y las aproximantes;
pero en esta diferencia distribucional no encontramos ningún argumento que nos permita
establecer qué variante tomamos como fonema: en ambos casos la realización alofónica
depende del contexto. El criterio de mayor frecuencia de uso —haría que nos
decidiésemos por las aproximantes— tampoco nos parece conclusivo.
Si tomamos las aproximantes como realizaciones no marcadas, debemos considerar la existencia de un proceso alofónico de refuerzo que las relaciona con las variantes oclusivas; en cambio, si consideramos que son las variantes oclusivas las realizaciones no marcadas, el proceso que las relacionaría con las aproximantes sería de lenición o debilitamiento (cf. D'Introno, 1995: 282-288, y Kenstowics, 1994: 487-488)7. Ambas soluciones son perfectamente plausibles. No obstante, podemos analizar cuál de los dos procesos mencionados es más natural en español.
Para ello es imprescindible tener en cuenta la evolución de la lengua. La lenición es un proceso constitutivo del español, como describió Menéndez Pidal (196813: §§ 37, 40, 41 y 48): tanto las oclusivas sordas latinas como las sonoras se mantienen en posición inicial, pero en posición intervocálica las sordas se convierten en sonoras y las sonoras se fricativizan8 o desaparecen; el mismo comportamiento se da si las oclusivas aparecen solas o agrupadas con una líquida. Este proceso es característico del latín vulgar occidental y muestra las realizaciones relajadas como las marcadas por el contexto. Incluso en el habla actual, el hablante culto de español tiende a relajar antes que a reforzar, lo han demostrado los trabajos experimentales de Aguilar et al. (1991 y 1993), Aguilar y Andreu (1991), Aguilar y Machuca (1993 y 1994) y De la Mota (1991). El debilitamiento de estos mismos sonidos en la distensión silábica también es característico de la lengua española, que en una posición articulatoriamente difícil no ha optado, como otras lenguas (por ejemplo, el catalán), por el refuerzo:
español: Madrid *[
.'
] / [
] / [
] / [
]
catalán: Madrid [
.'
Si asumimos la existencia de un proceso de debilitamiento que relaciona unos fonemas oclusivos sonoros con unas realizaciones aproximantes en posición inicial de sílaba, podemos tratar de un modo unitario un conjunto de fenómenos de la lengua española, puesto que ese mismo proceso nos permite explicar también el comportamiento de las oclusivas sordas y sonoras en la distensión silábica, como veremos en el siguiente apartado. Por tanto, consideraremos que en la posición de ataque silábico existen tres fonemas oclusivos sonoros, /b/, /d/ y /g/, que se realizan como oclusivos o aproximantes en función del contexto. Su distribución, según indica la bibliografía, es la siguiente: los alófonos oclusivos se realizan en posición inicial absoluta y tras nasal (el dental, también tras lateral) y los alófonos aproximantes, en el resto de contextos; en el apartado siguiente veremos que también se realizan las variantes oclusivas de los tres fonemas sonoros tras consonantes oclusivas sordas homorgánicas.
En este trabajo clasificaremos como oclusivo el fonema tradicionalmente denominado fricativo palatal sonoro; lo justificaremos en un apartado específico.
5.4.1.2. Consonantes oclusivas en la distensión silábica.
5.4.1.2.1. Neutralización de los fonemas oclusivos.
Para la fonología estructuralista, los fonemas
oclusivos sordos y sonoros, bilabiales /p/ y /b/, dentales /t/ y /d/ y velares /k/ y /g/,
se neutralizan en la distensión silábica. El resultado de este fenómeno son las
realizaciones aproximantes [![]() ], [
], [![]() ] y [
] y [![]() ], respectivamente; la neutralización se representa
mediante los correspondientes archifonemas. Como en la transcripción fonémica a partir
de la cual generamos el DEFE no constan estas unidades fonológicas, en posición final de
sílaba representaremos los fonemas oclusivos sordos y sonoros considerando que existe una
interpretación fónica regular de la ortografía:
], respectivamente; la neutralización se representa
mediante los correspondientes archifonemas. Como en la transcripción fonémica a partir
de la cual generamos el DEFE no constan estas unidades fonológicas, en posición final de
sílaba representaremos los fonemas oclusivos sordos y sonoros considerando que existe una
interpretación fónica regular de la ortografía:
grafema |
fonema |
grafema |
fonema |
p t c, k, q |
/p/ /t/ /k/ |
b, v d g |
/b/ /d/ /g/ |
Hemos mostrado en la revisión bibliográfica que no hay un común acuerdo sobre la oposición neutralizada: para Alarcos (1965), Canellada y Madsen (1987) y Quilis (1993) se neutraliza la sonoridad; para Martínez Celdrán (1989), la tensión. Creemos que debe diferenciarse entre la definición fonológica de una consonante como tensa o relajada y las propiedades articulatorias, acústicas o perceptivas que sean utilizadas para clasificarlas como tales9. Las consonantes sordas han sido definidas como 'tensas', 'fuertes' o 'fortis', y las sonoras, como 'relajadas', 'débiles' o 'lenis'; pero el carácter tenso o relajado de una consonante no sólo se observa en la vibración de las cuerdas vocales: las consonantes tensas se articulan con una mayor deformación del canal bucal con respecto a la posición neutra, o de reposo, y poseen una mayor intensidad y una mayor duración que las relajadas. En el caso de las oclusivas, la explosión que sigue al cierre de los órganos articulatorios es más fuerte en las tensas que en las débiles y la perceptibilidad suele ser mayor en las primeras que en las segundas (cf. Gil, 1988: 94-95). Según se desprende de los trabajos experimentales de Martínez Celdrán (1984b), parece ser que en español la tensión consonántica guarda una relación directa con la duración y una relación inversa con la intensidad, puesto que las oclusivas sordas son comparativamente más largas que las sonoras y apenas tienen intensidad.
Si definimos la neutralización como la confluencia en un mismo sonido de las realizaciones de dos o más fonemas en la misma posición silábica (cf. supra, apartado 5.1), para determinar qué se neutraliza debemos tener en cuenta los procesos que relacionan los fonemas con sus alófonos. La propiedad afectada por el proceso será la neutralizada.
La posición final de sílaba es una posición de debilitamiento, de pérdida de la tensión articulatoria, y en el debilitamiento de las oclusivas del español intervienen las modificaciones de la sonoridad y del modo de articulación. Teóricamente, podemos establecer la siguiente gradualidad, que coincide con el proceso histórico de la lenición romance10:
oclusiva sorda > oclusiva sonora > aproximante
La vibración de las cuerdas vocales distiende la articulación de las oclusivas sordas, y la articulación aproximante (en la que los órganos articulatorios se acercan sin producir un cierre) relaja la tensión de las oclusivas sonoras (realizadas con un cierre total). Si la máxima tensión corresponde a la ausencia de vibración de las cuerdas vocales y al cierre completo de los órganos articulatorios, podemos caracterizar las realizaciones de los fonemas oclusivos sordos y sonoros en la distensión silábica como en la siguiente tabla, donde se muestra que los sonidos aproximantes (citados en la bibliografía como las realizaciones comunes en ese contexto) son los más relajados, aquellos en los que se manifiesta el grado máximo de debilitamiento:
Tabla 14: Debilitamiento de los fonemas oclusivos en la distensión silábica.
| TENSIÓN | realizaciones oclusivas sordas | realizaciones oclusivas sonoras | realizaciones aproximantes |
| ausencia de vibración de las cuerdas vocales | + |
- |
- |
| cierre articulatorio | + |
+ |
- |
Por tanto, consideramos que los fonemas oclusivos sordos y sonoros se relacionan con sus realizaciones aproximantes en la distensión silábica a través de un proceso de debilitamiento; éste se manifiesta en las modificaciones del cierre articulatorio y de la vibración de las cuerdas vocales. La propiedad fonológica afectada por el proceso no es la sonoridad, porque no se justificaría la existencia de los alófonos aproximantes, sino la tensión; en ello coincidimos con Martínez Celdrán (1989). Sin embargo, no estamos de acuerdo con este autor cuando afirma que no existe neutralización de estos fonemas en posición final de palabra, basándose en la distribución defectiva de /p/, /b/, /k/, /g/ y /t/, que sólo aparecen en cultismos y extranjerismos: los ejemplos que cita son handicap, club, bistec, déficit, stop. Es cierto que la presencia de esas consonantes en posición final absoluta sólo puede darse en palabras procedentes de otros sistemas lingüísticos, pero éstas ahora forman parte de la lengua española y hasta pueden tener un uso relativamente frecuente; así lo creemos en casi todos los ejemplos citados por el mismo Martínez Celdrán, que hemos reproducido. Además, en la distensión silábica interior de palabra esos fonemas también aparecen en palabras no patrimoniales, puesto que en la evolución del latín al español las oclusivas implosivas de los grupos consonánticos primarios y secundarios desaparecen; citamos algunos ejemplos tomados de Menéndez Pidal (1968): cappa > capa; gutta > gota; bucca > boca; ipse > ese; captare > catar; tectu > techo; ligna > leña. Tan extranjerismo es atleta como déficit, eclipsar como stop, acción como bistec. Existen testimonios en la lengua antigua de palabras que la Academia ha fijado en su forma culta, con oclusiva en la distensión silábica interior de palabra, en las que esa consonante había desaparecido: efecto - efeto, concepto - conceto, digno - dino (cf. Martínez de Sousa, 1991: 196-152). En la lengua actual existen dobletes formados por formas cultas (con conservación de la oclusiva) y populares (donde la oclusiva ha desaparecido): captar - catar; variantes ortográficas: septiembre - setiembre; y formas cultas y populares en una misma familia léxica: leche, lácteo. Si en posición final de palabra coinciden las realizaciones de /p/ y /b/, de /t/ y /d/, y de /k/ y /g/, las oclusivas sordas y sonoras se neutralizan en ese contexto; la distinta distribución en la palabra sólo ha de ser tenida en cuenta para observar si las realizaciones son idénticas en ambas posiciones.
5.4.1.2.2. Alófonos de los fonemas oclusivos.
Hemos asumido que los alófonos aproximantes son las realizaciones marcadas por el debilitamiento de la distensión silábica; pero debemos determinar si se realizan en todos los contextos. La bibliografía (por ejemplo: Navarro Tomás, 1918; Martínez Celdrán, 1989; y Quilis, 1993) describe una gran variación en las realizaciones de los fonemas oclusivos; ésta depende, principalmente, del estilo de habla, pero está provocada por las dificultades articulatorias de estos sonidos en la posición final de sílaba. La reciente tesis de Machuca (1997) muestra que en el habla espontánea de los hablantes cultos existe una importante variedad de realizaciones. En el DEFE debemos sistematizar la variación de un modo objetivo analizando el proceso alofónico de debilitamiento. En los siguientes apartados discutiremos la transcripción de los distintos grados de debilitamiento mencionados en la bibliografía, los contextos en que éste actúa y la aplicación de otros procesos alofónicos concurrentes.
5.4.1.2.2.1. Grados de debilitamiento.
Hemos situado los alófonos aproximantes en una escala de debilitamiento que recoge una situación ideal y simplificada, con sólo tres realizaciones: oclusivas sordas, oclusivas sonoras y aproximantes. Creemos que estas tres categorías están perfectamente definidas y distanciadas entre sí dentro de una gradualidad, y describen el proceso de un modo suficientemente adecuado; pero además de esas variantes se pueden realizar otras más o menos sonorizadas y más o menos relajadas. El problema es determinar si tales realizaciones están verdaderamente marcadas por el contexto o dependen de aspectos particulares de los hablantes, del mayor o menor énfasis que impriman a su pronunciación. En el DEFE no tendremos en cuenta los distintos grados de debilitamiento que puedan producirse y sólo consideraremos otros alófonos, además de los citados, en el caso de que dependan claramente de la variación contextual. Así, no constarán en la transcripción los sonidos aproximantes relajados que describe Navarro Tomás:
(1) En las palabras formadas por las partículas ab-, ob-, sub- seguidas de [s] y otras consonantes (obstinación, obstáculo, obstrucción, abstinencia, abstemio, abstracto) la realización de la aproximante bilabial resulta frecuentemente más débil y relajada que en otros contextos. Aunque en la pronunciación enfática suele reforzarse hasta convertirse en [p], en el habla corriente suele ser un sonido breve y suave, con tendencia a ser elidido (cf. Navarro Tomás, 1918: § 84).
(2) En posición final absoluta la aproximante dental se pronuncia particularmente débil y relajada: la punta de la lengua toca perezosamente el borde de los incisivos superiores, las vibraciones laríngeas cesan casi al mismo tiempo que se forma el contacto linguodental y la corriente aspirada, preparando la pausa siguiente, suele ser tan tenue, que la articulación resulta casi muda (cf. Navarro Tomás, 1918: § 102).
(3) El grupo ortográfico cc (dirección, acción, instrucción,
selección, dicción) se pronuncia ordinariamente [![]()
![]() ], con una velar débil y relajada. En
formas fuertes o enfáticas este grupo se pronuncia [
], con una velar débil y relajada. En
formas fuertes o enfáticas este grupo se pronuncia [![]()
![]() ]; en el habla vulgar se reduce elidiéndose la velar
(cf. Navarro Tomás, 1918: § 108).
]; en el habla vulgar se reduce elidiéndose la velar
(cf. Navarro Tomás, 1918: § 108).
(4) La letra x intervocálica (examen, eximio, éxito,
exótico, exención, máxima, existencia) se pronuncia[![]()
![]() ], con una velar débil y relajada. En el
habla vulgar la x intervocálica se pronuncia como [
], con una velar débil y relajada. En el
habla vulgar la x intervocálica se pronuncia como [![]() ] (cf. Navarro Tomás, 1918: §
129).
] (cf. Navarro Tomás, 1918: §
129).
Aunque determinados contextos, y también el carácter átono de la sílaba, favorezcan un debilitamiento mayor, el grado máximo que representaremos será el de las realizaciones aproximantes, porque con ellas se indica un punto de la escala que podemos establecer claramente mediante la presencia, «+», o ausencia, «-», de los gestos articulatorios con los que hemos definido el proceso.
D'Introno et al. (1995: 266 y 269) también proponen una escala de debilitamiento, distinta a la que hemos presentado, para situar los alófonos de los fonemas oclusivos sordos. Está formada por las siguientes realizaciones (la ilustramos con /p/, pero es generalizable a /t/ y /k/)12:
Figura 5: Escala de debilitamiento de las oclusivas sordas en la distensión silábica, según D'Introno et al. (1995). Representación lineal.
+ ------------------------------------------------------------------> -
|
Esta escala puede ser representada también mediante los ejes de abscisas y ordenadas, que indicarían la tensión y la sordez, respectivamente, pues son dos los rasgos afectados por el proceso, [oclusiva] y [sorda]:
Figura 6: Escala de debilitamiento de las oclusivas sordas en la distensión silábica, según D'Introno et al. (1995). Representación axial.
|
La propuesta de estos autores tiene como objetivo formular el conjunto de reglas que permitan derivar los distintos alófonos de /p/, /t/ y /k/ de un modo descriptivamente adecuado. El enfoque es muy interesante y tiene indudables similitudes con el nuestro, puesto que utilizamos la escala de debilitamiento para formalizar un proceso alofónico que nos permita establecer los segmentos marcados por la variación contextual que han de constar en la transcripción del DEFE; pero tenemos que presentar algunas objeciones.
Aunque D'Introno et al. (1995: 274-280) también mencionen el debilitamiento en la descripción de los alófonos de los fonemas oclusivos sonoros, no lo integran como un fenómeno unitario común para todas las consonantes oclusivas. Desde nuestro punto de vista, este proceso no puede ser tratado atendiendo únicamente a las sordas porque también concierne a las sonoras: las realizaciones de ambas coinciden en determinados contextos y se sitúan en la misma escala; en ella debería incluirse la oclusiva bilabial sonora [b]. Además, se observa que es una gradación ad hoc, establecida a partir de unos alófonos concretos (tomados en parte de la descripción de Navarro Tomás), lo que es contradictorio con el enfoque teórico que domina en su trabajo. Creemos que primero se debe establecer una hipótesis sobre la gradualidad del debilitamiento, definir aquello que sería posible, y después situar los sonidos en ella; esta metodología ha de permitir observar qué segmentos quedan fuera de la escala preestablecida, para modificarla porque la hipótesis sea incorrecta o para detectar la existencia de otros fenómenos en la realización de los alófonos.
De hecho, dudamos de que todos los segmentos que constan en su escala puedan ser justificados desde el debilitamiento. La oclusiva asimilada a la consonante siguiente C (de modo que se convierte en una consonante idéntica a C, copiando todos sus rasgos) representa, según los autores, "un segmento sin su propia tensión y sordez/sonoridad" (cf. D’Introno et al., 1995: 269). Es cierto que el proceso de asimilación implica la pérdida de determinados rasgos (lo que puede ser interpretado como debilitamiento), pero para adquirir otros, y el alófono resultante no tiene por qué reflejar necesariamente relajación; lo observamos en los ejemplos que citan:
(i) En hipnosis ---> hi[n]nosis, existe debilitamiento sólo si tenemos en cuenta la entrada [p] y la salida [n], en cuanto que la nasal, como segmento sonoro, es más relajado que la oclusiva sorda; pero dentro de la escala, una nasal, que también se realiza con un cierre total de los órganos articulatorios, presenta una mayor tensión que la aproximante.
(ii) En septiembre ---> se[t]tiembre y aktor ---> a[t]tor, el alófono resultante [t], oclusivo sordo, tiene la misma tensión que [p] y [k].
En hi[n]nosis, se[t]tiembre y a[t]tor también se modifican los rasgos que hacen referencia al punto de articulación, y en el primer ejemplo, la nasalidad, por lo que estos fenómenos quedan sin ser explicados dentro del proceso de debilitamiento, descrito por los autores en términos de [oclusión] y [sordez]. Este hecho parece indicar que el problema no ha sido abordado adecuadamente. En los casos que hemos mencionado se está aplicando realmente un proceso de asimilación. La debilidad articulatoria de la distensión silábica favorece la asimilación de los rasgos de la consonante siguiente (es allí donde se producen los casos de asimilaciones descritos para el español), pero el alófono resultante no depende del debilitamiento en sí, sino que está condicionado por dicha consonante. Creemos que ambos procesos —debilitamiento y asimilación— han de ser formalizados separadamente para no perder capacidad descriptiva y explicativa. La independencia entre ambos queda de manifiesto si observamos los contextos en que se producen: la asimilación de las consonantes sólo tiene lugar en la distensión silábica; el debilitamiento también puede realizarse en la posición de ataque, como hemos considerado en el caso de los fonemas oclusivos sonoros. Desde nuestro punto de vista, esa consonante asimilada no debe constar en la escala propuesta.
Finalmente, hay una diferencia entre nuestra concepción del debilitamiento y el que proponen estos autores. En la representación axial se observa que identifican la tensión con la oclusión, al tiempo que la disocian de la sordez. Nosotros hemos definido la tensión en términos de ausencia de vibración de las cuerdas vocales ([sordez]) y cierre de los órganos articulatorios ([oclusión]). Posiblemente sea una imprecisión por parte de los autores, o nuestra concepción sea incorrecta. No entraremos en una polémica que implicaría revisar todo el sistema de rasgos distintivos porque queda fuera de los objetivos de nuestro trabajo: en la transcripción del DEFE no constan matrices de rasgos y hemos asumido una definición de los segmentos en términos articulatorios tradicionales por comodidad. No obstante, creemos que debe diferenciarse entre los rasgos que hacen referencia a la vibración de las cuerdas vocales [sonoridad / sordez] y al modo de articulación [oclusivo / no oclusivo] (o [no continuo / continuo]), que también utilizan los autores), y la concurrencia de ambos en la caracterización de los segmentos como [tensos] o [relajados] y su intervención en el proceso de debilitamiento.
5.4.1.2.2.2. Aplicación y restricciones del proceso de debilitamiento.
La pronunciación descrita por Navarro Tomás no recoge todos los contextos de aparición de las consonantes oclusivas en la distensión silábica; se refiere a la palabra aislada y no contempla el enlace entre palabras, donde las combinaciones de fonemas son más numerosas que en posición interior (en ésta, no hemos registrado ejemplos para todos los casos). De hecho, la única consonante que no aparece como inicial absoluta es la vibrante simple, por lo que todas las demás combinaciones fonemáticas formadas por /oclusiva final + consonante inicial/ son posibles, aunque a veces sea difícil encontrar ejemplos apropiados: salvo /d/, las oclusivas finales sólo aparecen en extranjerismos y cultismos, y el número de estas palabras es limitado. Si nuestro sistema ha de ser capaz de transcribir todo el léxico del español, como palabras aisladas y en la oración, debemos hacer las generalizaciones pertinentes a partir de la pronunciación descrita para abarcar todos los contextos. Nuestro propósito es establecer las leyes generales que rigen el proceso de debilitamiento y las restricciones que puedan existir en su aplicación.
En principio, las oclusivas sordas presentarán una mayor resistencia al debilitamiento que las sonoras, puesto que en su realización se han de modificar los dos gestos articulatorios descritos: cierre y vibración de las cuerdas vocales; las sonoras sólo han de modificar uno; pero creemos que el proceso de debilitamiento ha de estar condicionado por las relaciones que se establecen entre la tensión propia de la oclusiva y la tensión de la consonante siguiente. Podemos establecer una escala de tensión en la que situar las distintas clases de consonantes:
- Una consonante será [+tensa] si se realiza con un cierre de los órganos articulatorios y sin vibración de las cuerdas vocales (las oclusivas sordas y la africada palatal sorda).
- Una consonante será [±tensa] si en su realización interviene uno de los dos gestos articulatorios mencionados: o cierre o vibración las cuerdas vocales (oclusivas sonoras, nasales, laterales, vibrantes y fricativas sordas).
- Una consonante será [-tensa] si en su realización no se produce el cierre de los órganos articulatorios y vibran las cuerdas vocales. Esta caracterización quedaría restringida a la fricativa palatal sonora, si se acepta la definición tradicional de esta consonante (nosotros la consideramos oclusiva), y a la aproximante labiovelar /w/, si se incluye entre los fonemas del español, como hacemos en este trabajo (lo justificaremos más adelante).
En la Tabla 15 representamos la tensión de las consonantes del español, referida a las especificaciones (« + », « - ») de los gestos articulatorios con los que la hemos definido13.
Tabla 15: Especificaciones de la tensión consonántica.
TENSIÓN
|
A F R I C A D A
S O R D A |
O C L U S I V A
S O R D A |
F R I C A T I V A
S O R D A |
O C L U S I V A
S O N O R A |
N A S A L |
L A T E R A L |
V I B R A N T E |
A P R O X I M A N T E |
ausencia de vibración de las cuerdas vocales |
+ |
+ |
+ |
- |
- |
- |
- |
- |
cierre articulatorio |
+ |
+ |
- |
+ |
+ |
+ |
+ |
- |
En el grupo consonántico formado por una oclusiva –sorda o sonora– en la distensión silábica y una consonante en el ataque de la sílaba siguiente, pueden existir tres tipos de relaciones en cuanto a la tensión de ambas:
(i) Ambas consonantes tienen el mismo grado de tensión, ya sea un grado máximo: [+tensa] - [+tensa], o un grado no máximo: [±tensa] - [±tensa].
(ii) La tensión consonántica del grupo es decreciente, de modo que se den tres combinaciones: [+tensa] - [±tensa], [+tensa] - [-tensa], [±tensa] - [-tensa].
(iii) Existe un aumento de la tensión en el grupo, pasándose de una consonante [±tensa] a otra [+tensa].
Para determinar el conjunto de alófonos que derivan del proceso de debilitamiento formularemos un conjunto de hipótesis sobre los tres tipos de relaciones descritas, que contrastaremos con los datos de Navarro Tomás (1918) y con nuestra propia competencia14.
Relación 1: Igualdad en la tensión consonántica.
(1.1) Oclusiva [+tensa] - consonante [+tensa]
En una situación articulatoria en la que ambas consonantes estén caracterizadas por la máxima tensión no se producirá debilitamiento. Es el caso de una oclusiva sorda ante otra oclusiva sorda o una africada, cuyo primer tiempo también es oclusivo.
(1.1.1) /oclusiva sorda/ - /oclusiva sorda/ (no homorgánicas)
/oclusiva sorda X/ - /oclusiva sorda Y/ -----> [oclusiva sorda X] - [oclusiva sorda Y]
Tabla 16: Ejemplos de las realizaciones de los fonemas oclusivos sordos ante consonantes oclusivas sordas no homorgánicas.
|
Consideramos que la realización de dos articulaciones oclusivas sordas contiguas no favorece el debilitamiento porque se mantiene la tensión articulatoria del cierre sin vibración de las cuerdas vocales. Navarro Tomás (1918: §§ 79 y 125) sólo registra ejemplos, en el interior de palabra, para /p/ - /t/ (apto, concepto, reptil, inepto, adoptar) y /k/ - /t/ (actor, doctor, pacto, efecto, perfecto). Añadimos otro para /t/ - /p/, el del extranjerismo output, pero todas las combinaciones son posibles en el enlace entre palabras. Proponemos un tratamiento unitario para todos los casos.
Navarro Tomás indica que la pronunciación de la consonante situada en la distensión silábica es variable: se puede realizar como oclusiva explosiva (sólo lo menciona para el contexto /k/ - /t/), como oclusiva implosiva y como aproximante15. Consideramos que los alófonos aproximantes pertenecen al habla familiar y relajada, que no transcribimos, y los alófonos explosivos requieren un mayor énfasis en la pronunciación, que tampoco tenemos en cuenta. La realización implosiva está exenta de énfasis y de una excesiva relajación: se produce un cierre de los órganos articulatorios sin que tenga lugar la explosión, al contrario de lo que sucede en la segunda oclusiva, situada en el ataque silábico, cuya explosión queda asegurada como tránsito al sonido siguiente, una vocal o una líquida.
(1.1.2) /oclusiva sorda/ - /oclusiva sorda/ (homorgánicas):
/oclusiva sorda X/ - /oclusiva sorda X/ -----> Ø - [oclusiva sorda X]
Tabla 17: Ejemplos de las realizaciones de los fonemas oclusivos sordos ante consonantes oclusivas sordas homorgánicas.
|
Debemos diferenciar entre la combinación formada por dos oclusivas sordas contiguas no homorgánicas, a la que correspondería la descripción de (1.1.1), y la formada por dos oclusivas sordas homorgánicas. Este contexto, no mencionado por Navarro Tomás, es poco frecuente, pero existen algunos casos en el léxico del español (en extranjerismos) y es posible en el enlace entre palabras.
Según Navarro Tomás (1918: § 155), "Dos consonantes iguales, en contacto, se pronuncian como si se tratase de una sola consonante relativamente larga y repartida entre las dos sílabas inmediatas; la intensión de esta consonante, con alguna parte de su tensión, corresponde a la sílaba precedente, y el resto a la siguiente, hallándose, por tanto, el límite de ambas sílabas hacia el centro de la tensión de dicha consonante larga. La duración de ésta no es, pues, igual precisamente a la suma de dos consonantes simples; pero a falta de otro medio mejor empleamos en la escritura fonética una consonante doble para representarla". Consideramos que, en la realización de dos consonantes sordas adyacentes con el mismo punto de articulación, el tiempo implosivo de la primera consonante se prolonga con el de la segunda, por lo que en realidad se realizaría una sola oclusiva con un silencio más largo de lo habitual. Se trata, por tanto, de un proceso de coalescencia, cuyo resultado es la realización de una sola consonante, la de la segunda sílaba, como hemos transcrito en la Tabla 17.
(1.1.3) /oclusiva sorda/ - /africada sorda/.
/oclusiva sorda/ - /africada sorda/ -----> [oclusiva sorda] - [africada sorda]
Tabla 18: Ejemplos de las realizaciones de los fonemas oclusivos sordos ante la consonante africada.
|
En la articulación de la africada el predorso de la lengua forma primero una oclusión con la zona alveoloprepalatal, seguida inmediatamente por una constricción, en la misma zona articulatoria (cf. Quilis, 1988: 259, y 1993: 291); por tanto, no existiría homorganicidad con cualquier oclusiva sorda que la preceda.
(1.2) Oclusiva [±tensa] - consonante [±tensa]
En una situación articulatoria en la que ambas consonantes tienen la misma tensión pero no están caracterizadas con el grado máximo, se producirá debilitamiento; sería el caso de una oclusiva sonora ante una consonante [±tensa] (oclusiva sorda, nasal, lateral, vibrante, fricativa sorda). Creemos que la ausencia de máxima tensión en la consonante siguiente favorece la relajación de la oclusiva sonora, que además ha de presentar menos restricciones a la realización del proceso en la medida en que también carece de la máxima tensión.
(1.2.1) /oclusiva sonora/ - /oclusiva sonora/.
/oclusiva sonora/ - /oclusiva sonora/ -----> [aproximante] - [aproximante]
Tabla 19: Ejemplos de las realizaciones de los fonemas oclusivos sonoros ante consonante oclusiva sonora.
|
Dos fonemas oclusivos sonoros contiguos se realizan como aproximantes: la relajación del primero, situado en la distensión silábica, crea un contexto de debilitamiento para el fonema situado en el ataque siguiente; así lo describe Navarro y Tomás (1918: §§ 81 y 100): abdicar, subyugar, advertencia. En el habla enfática también puede articularse una oclusiva sonora. Cuando las dos oclusivas sonoras son homorgánicas no se produce elisión en el habla culta no rápida. Se pronunciarían como una consonante geminada con una duración breve de la primera. Navarro Tomás (1918: § 155) cita los ejemplos de edad dichosa, juventud dorada.
Si el fonema clasificado habitualmente como fricativo palatal sonoro es oclusivo (así lo consideramos en este trabajo), su comportamiento en el proceso será igual al de /b/, /d/ y /g/. En posición final de sílaba, está en distribución defectiva: no está citado en la bibliografía ni hemos registrado ejemplos.
(1.2.2) /oclusiva sonora/ - /nasal/.
/oclusiva sonora/ - /nasal/ -----> [aproximante] - [nasal]
(+nasalización)Tabla 20: Ejemplos de las realizaciones de los fonemas oclusivos sonoros ante consonante nasal.
|
Navarro Tomás (1918: §§ 80 y 127) describe
realizaciones aproximantes en los contextos [![]() ] - [n], abnegación; [
] - [n], abnegación; [![]() ] - [m], admirar;
[
] - [m], admirar;
[![]() ] -
[n], signo. Generalizaremos la aplicación del proceso de debilitamiento para los
casos de /oclusiva sonora/ - /
] -
[n], signo. Generalizaremos la aplicación del proceso de debilitamiento para los
casos de /oclusiva sonora/ - /![]() / en el interior de palabra, aunque no hayamos
registrado ejemplos; de hecho, la nasal palatal no aparece agrupada con ninguna otra
consonante (cf. Harris, 1991: 103, n. 19).
/ en el interior de palabra, aunque no hayamos
registrado ejemplos; de hecho, la nasal palatal no aparece agrupada con ninguna otra
consonante (cf. Harris, 1991: 103, n. 19).
Para el grupo bifonemático [![]() ] - [m] Navarro
Tomás menciona una doble pronunciación: oclusiva sonora implosiva muy débil [sub.ma.'
] - [m] Navarro
Tomás menciona una doble pronunciación: oclusiva sonora implosiva muy débil [sub.ma.'![]() i.no] o nasal
bilabial por asimilación a la consonante siguiente [sum.ma.'
i.no] o nasal
bilabial por asimilación a la consonante siguiente [sum.ma.'![]() i.no]. En el
DEFE transcribiremos el alófono nasal (aunque en una representación no relajada:
[sum.ma.'
i.no]. En el
DEFE transcribiremos el alófono nasal (aunque en una representación no relajada:
[sum.ma.'![]() i.no])
porque consideramos que se dan las condiciones necesarias en el contexto para que se
aplique el proceso de nasalización, como indicamos en la Figura 7, y es una
pronunciación posible en la lengua culta.
i.no])
porque consideramos que se dan las condiciones necesarias en el contexto para que se
aplique el proceso de nasalización, como indicamos en la Figura 7, y es una
pronunciación posible en la lengua culta.
Figura 7: Nasalización de la oclusiva bilabial sonora.
/b/ /m/ oclusivo = oclusivo bilabial = bilabial sonoro = sonoro oral <--------------- nasal
|
La asimilación de los rasgos de la consonante siguiente justifica la nasalización: se han de realizar dos sonidos que comparten la sonoridad y el mismo punto de articulación, y que se articulan con un cierre total (las nasales también son oclusivas); la única diferencia entre ambos es la posición del velo del paladar. Como indica Navarro Tomás (1918: 178), la oclusiva oral queda "absorbida" por la nasal. No tendremos en cuenta otros casos en los que las consonantes oclusiva y nasal adyacentes no sean homorgánicas: es el ejemplo de hi[n]nosis, citado por D'Introno et al. (1995). Tampoco extenderemos la aplicación de este proceso al contexto [oclusiva bilabial sorda - nasal bilabial] porque, además de diferir en la nasalidad, estas consonantes poseen distinta sonoridad y se han de modificar dos rasgos (no hemos registrado este contexto en el léxico del español, pero es posible en el enlace entre palabras: eslip marrón). Es cierto que una oclusiva puede nasalizarse siempre que esté seguida por una nasal, pero el único caso descrito por Navarro Tomás es el de las consonantes homorgánicas y sonoras /b/ - /m/. Creemos que en otras condiciones la nasalización no correspondería a la pronunciación esmerada de la lengua culta.
(1.2.3) /oclusiva sonora/ - /líquida/.
/oclusiva sonora/ - /líquida/ -----> [aproximante] - [líquida]
Tabla 21: Ejemplos de las realizaciones de los fonemas oclusivos sonoros ante consonante líquida.
|
No es un contexto frecuente en la lengua; la combinación /oclusiva sonora + líquida/ suele formar un grupo tautosilábico. Navarro Tomás cita los ejemplos de tomadlo y subrayar, con debilitamiento. Creemos que la líquida no pone restricciones a este proceso, pero ante vibrante se tiende a reforzar: se daría una realización situada en cuanto al debilitamiento entre la oclusiva y la aproximante, que no transcribiremos.
(1.2.4) /oclusiva sonora/ - /fricativa sorda/.
/oclusiva sonora/ - /fricativa sorda/ -----> [aproximante
ensordecida] - [fricativa sorda]Tabla 22: Ejemplos de las realizaciones de los fonemas oclusivos sonoros ante consonante fricativa sorda.
|
Navarro Tomás (1918) también describe el
debilitamiento en este contexto, pero la realización es un alófono ensordecido, con
tendencia al refuerzo (obcecado, abjurar, objeto, ábside, absurdo, subsanar,
obsesión): en contacto con una articulación sorda siguiente, [![]() ] no siempre se
pronuncia plenamente sonora; en la conversación ordinaria la última parte de su
articulación suele ensordecerse; en formas relativamente fuertes suele ensordecerse
totalmente, y en una pronunciación claramente enfática puede llegar a realizarse una
oclusiva sorda17, [p] o [b] (ábside).
También [
] no siempre se
pronuncia plenamente sonora; en la conversación ordinaria la última parte de su
articulación suele ensordecerse; en formas relativamente fuertes suele ensordecerse
totalmente, y en una pronunciación claramente enfática puede llegar a realizarse una
oclusiva sorda17, [p] o [b] (ábside).
También [![]() ]
ante consonante sorda, suele ensordecerse parcialmente: adjetivo, adquirir, y en la
pronunciación fuerte puede llegar a realizarse como [d] oclusiva.
]
ante consonante sorda, suele ensordecerse parcialmente: adjetivo, adquirir, y en la
pronunciación fuerte puede llegar a realizarse como [d] oclusiva.
Navarro Tomás (1918: § 84) describe el mismo comportamiento en los grupos tautosilábicos de /oclusiva + s/ en la distensión silábica: en las palabras formadas por las partículas ab-, ob-, sub- seguidas de [s] y otras consonantes (obstinación, obstáculo, obstrucción, abstinencia, abstemio, abstracto) la realización de la oclusiva tampoco suele ser completamente sonora. Además, su articulación resulta frecuentemente más débil y relajada que en ninguno de los casos antes citados; en la pronunciación enfática suele reforzarse hasta convertirse en [p]; pero en el habla corriente suele ser un sonido breve y suave, con tendencia a ser elidido. De hecho, aunque se escriba, no se pronuncia la b en obscuro, subscribir, substraer, substancia, substituir, y en sus derivados.
Creemos que necesariamente se ha proponer una gradualidad en el proceso de ensordecimiento, de modo que la modificación articulatoria de las cuerdas vocales tenga lugar durante la realización como aproximante de la oclusiva: a un periodo de vibración de las cuerdas vocales (en la articulación de la vocal y parte de la aproximante) sigue otro de ausencia de vibración (en el resto de la aproximante y en la consonante sorda); de no ser así, y se tratara de un ensordecimiento total, el alófono resultante sería una oclusiva sorda, ya que no existen aproximantes sordas. En el siguiente cuadro se representa el proceso gradual descrito:
Figura 8: Ensordecimiento parcial de los alófonos aproximantes.
|
Relación 2: Tensión decreciente.
Cuando la tensión consonántica del grupo es decreciente, se pueden dar tres combinaciones:
(1) [+tensa] - [-tensa]: oclusiva sorda - aproximante /w/
(2) [±tensa] - [-tensa]: oclusiva sonora - aproximante /w/.
(3) [+tensa] - [±tensa]: oclusiva sorda - consonante sonora (oclusiva, nasal, líquida) y fricativa sorda.
En todas ellas, la tensión global decreciente del grupo consonántico ha de favorecer el debilitamiento. Los dos primeros casos son posibles en la lengua, pero sólo se dan en el enlace entre palabras; creemos que ante una articulación aproximante, muy relajada, las oclusivas sordas y sonoras se debilitan.
Al igual que hemos propuesto un ensordecimiento parcial de las oclusivas sonoras en la distensión silábica ante consonante sorda, también se podría proponer una sonorización parcial de la oclusiva sorda cuando está precedida por una consonante sonora. El proceso de sonorización sería gradual, de modo que la modificación articulatoria tenga lugar durante la realización de la oclusiva:
sonorización:
| fonema | [vocal] | + [oclusiva sorda] | - [consonante sonora] |
| realización | (sonora) | (sorda > sonora) |
(sonora) |
No obstante, la sonorización parcial de una oclusiva sorda presenta cierta dificultad articulatoria, puesto que las cuerdas vocales han de cesar la vibración presente en la vocal durante un breve instante para reiniciarla. Es lógico pensar que la sonorización de la oclusiva sorda sea total; así constará en nuestra transcripción. De hecho, Navarro Tomás no describe casos de sonorización parcial, sí de ensordecimiento; este proceso es más defendible, puesto que a un periodo de vibración de las cuerdas vocales (en la articulación de la vocal y parte de la oclusiva) sigue otro de ausencia de vibración (en el resto de la oclusiva y en la consonante sorda siguiente).
(2.1) Oclusiva [+tensa] - consonante [-tensa]
/oclusiva sorda X/ - aproximante /w/ -----> [aproximante X] - aproximante /w/
Tabla 23: Ejemplos de las realizaciones de los fonemas oclusivos sordos ante consonante aproximante labiovelar.
|
(2.2) Oclusiva [±tensa] - consonante [-tensa]
/oclusiva sonora X/ - aproximante /w/ -----> [aproximante X] - aproximante /w/
Tabla 24: Ejemplos de las realizaciones de los fonemas oclusivos sonoros ante consonante aproximante labiovelar.
|
(2.3) Oclusiva [+tensa] - consonante [±tensa]
(2.3.1) /oclusiva sorda/ - /oclusiva sonora/ (no homorgánicas)
/oclusiva sorda X/ - /oclusiva sonora Y/ -----> [aproximante X] - [aproximante Y]
Tabla 25: Ejemplos de las realizaciones de los fonemas oclusivos sordos ante consonante oclusiva sonora no homorgánica.
|
Navarro Tomás no describe específicamente este caso. De hecho, existen pocos ejemplos de estas combinaciones en el léxico del español, pero también es posible encontrarlos en el enlace entre palabras. Creemos que la situación articulatoria favorece el debilitamiento de la oclusiva sorda, inducido por la sonoridad de la consonante siguiente. No se trataría de un caso de asimilación de la sonoridad, cuyo resultado sería la realización del fonema oclusivo sordo como una oclusiva sonora: esta variante es enfática. En grupo difonemático /oclusiva sorda/ - /oclusiva sonora/, no homorgánicas, no se ha de producir elisión de la primera; ambas se realizarían como aproximantes.
(2.2) /oclusiva sorda/ - /oclusiva sonora/ (homorgánicas)
/oclusiva sorda X/ - /oclusiva sonora X/ -----> Ø - [oclusiva sonora X]
Tabla 26: Ejemplos de las realizaciones de los fonemas oclusivos sordos ante consonante oclusiva sonora homorgánica.
|
Este contexto tampoco fue descrito por Navarro Tomás y no hemos documentado ningún ejemplo de unidad léxica que lo contenga, pero es posible en el enlace entre palabras. En estos casos, el cierre de la segunda consonante coincidiría con el de la primera, formando una única oclusión, antes del periodo de vibración de las cuerdas vocales y de la explosión de la consonante sonora; tras el cierre, que equivaldría al de una pausa, ésta se ha de realizar como oclusiva. Si se da esta situación articulatoria, las oclusivas sordas implosivas se han de elidir; es la decisión que adoptamos.
(2.3) /oclusiva sorda/ - /nasal/
/oclusiva sorda X/ - /nasal/ -----> [aproximante] - [nasal]
Tabla 27: Ejemplos de las realizaciones de los fonemas oclusivos sordos ante consonante nasal.
|
Navarro Tomás (1918: § 98) indica que en posición
final de sílaba (ritmo, étnico), sobre todo en posición inacentuada (atmósfera,
etnología), el fonema oclusivo dental sordo /t/ se realiza como oclusiva sorda en la
pronunciación fuerte o enfática; en la conversación normal se reduce en estos mismos
casos a una aproximante [![]() ]. El grupo ortográfico cn (técnica, tecnicismo),
en la conversación ordinaria, se pronuncia generalmente [
]. El grupo ortográfico cn (técnica, tecnicismo),
en la conversación ordinaria, se pronuncia generalmente [![]()
![]() ]; no hay diferencia entre la articulación
de técnica y la de signo.
]; no hay diferencia entre la articulación
de técnica y la de signo.
(2.4) /oclusiva sonora/ - /líquida/
/oclusiva sonora/ - /líquida/ -----> [aproximante] - [líquida]
Tabla 28: Ejemplos de las realizaciones de los fonemas oclusivos sordos ante consonante líquida.
|
Estas combinaciones tampoco son frecuentes en la
lengua. En el léxico del español sólo existe /t/ - /l/; no forma un grupo
tautosilábico en la norma que hemos tomado como estándar. Navarro Tomás (1918: § 98)
indica que en posición final de sílaba (atlas), sobre todo en posición
inacentuada (atlántico), el fonema oclusivo dental sordo /t/ se realiza como
oclusiva sorda en la pronunciación fuerte o enfática; en la conversación normal se
reduce en estos mismos casos a una aproximante [![]() ].
].
(2.5) /oclusiva sorda/ - /fricativa sorda/
/oclusiva sorda/ - /fricativa sorda/ -----> [aproximante
ensordecida] - [fricativa sorda]Tabla 29: Ejemplos de las realizaciones de los fonemas oclusivos sordos ante consonante fricativa sorda.
|
Navarro Tomás describe una pronunciación variable en este contexto:
- Ante las fricativas [![]() ] y [s], se mantiene la oclusiva bilabial
sorda [p] en la pronunciación esmerada y fuerte, especialmente en sílaba acentuada: cápsula,
eclipse, inepcia; en cambio, en la pronunciación corriente, sobre todo en sílaba
inacentuada, se realiza normalmente una aproximante [
] y [s], se mantiene la oclusiva bilabial
sorda [p] en la pronunciación esmerada y fuerte, especialmente en sílaba acentuada: cápsula,
eclipse, inepcia; en cambio, en la pronunciación corriente, sobre todo en sílaba
inacentuada, se realiza normalmente una aproximante [![]() ]: concepción, excepción, recepción,
opción, adopción.
]: concepción, excepción, recepción,
opción, adopción.
- La oclusiva [p] del grupo ortográfico pc se pierde en algunas palabras cultas de uso frecuente: suscripción, transcripción.
- El grupo ortográfico cc (dirección, acción,
instrucción, selección, dicción) se pronuncia ordinariamente [![]()
![]() ], con una
velar débil y relajada que, bajo la influencia de la interdental siguiente, suele
resultar en parte ensordecida. En formas fuertes o enfáticas este grupo se pronuncia [k
], con una
velar débil y relajada que, bajo la influencia de la interdental siguiente, suele
resultar en parte ensordecida. En formas fuertes o enfáticas este grupo se pronuncia [k![]() ]; en el habla
vulgar se reduce, elidiéndose la velar.
]; en el habla
vulgar se reduce, elidiéndose la velar.
Consideramos que la realización oclusiva pertenece al habla enfática: se mantiene la tensión articulatoria, sin debilitamiento; con el proceso concurre el de asimilación, y el resultado es una aproximante ensordecida.
Entre los grupos tautosilábicos en la distensión
silábica, Navarro Tomás (1918: § 129) describe el grupo /ks/, correspondiente a la
pronunciación de la letra x, que muestra un mayor grado de debilitamiento, con
elisión de la oclusiva. En la conversación ordinaria, la letra x ante consonante (extraño,
explicación, exponer, excelente, excepción, exclamar, excursión, extensión) se
pronuncia como una simple [s]. Entre vocales (examen, eximio, éxito, exótico,
exención, máxima, existencia) se pronuncia [![]() s], con una velar débil y relajada que
también resulta parcialmente ensordecida; ante h se pronuncia como intervocálica.
En el habla vulgar la x intervocálica se pronuncia con el mismo valor de [s] de la
x final de sílaba. La pronunciación correcta admite, generalmente, la [s] en exacto,
auxilio y auxiliar. En este trabajo transcribiremos x como /ks/, pero no
reduciremos el grupo a [s] en ningún contexto, puesto que consideramos que el hablante
culto, en el habla cuidada, tiende a realizarlo.
s], con una velar débil y relajada que
también resulta parcialmente ensordecida; ante h se pronuncia como intervocálica.
En el habla vulgar la x intervocálica se pronuncia con el mismo valor de [s] de la
x final de sílaba. La pronunciación correcta admite, generalmente, la [s] en exacto,
auxilio y auxiliar. En este trabajo transcribiremos x como /ks/, pero no
reduciremos el grupo a [s] en ningún contexto, puesto que consideramos que el hablante
culto, en el habla cuidada, tiende a realizarlo.
Relación 3: Tensión creciente.
Son los casos de una oclusiva sonora ante otra oclusiva sorda o una africada (poco frecuente), por ejemplo, subprefecto, obtener, subcomisario, antigüedad perdida, bulldog perdiguero, zigzag trazado. Existen tres posibilidades de realización:
(1) Refuerzo (realización oclusiva sorda).
(2) Mantenimiento de la oclusiva (no relajación ni debilitamiento).
(3) Debilitamiento (realización aproximante, con ensordecimiento)
Navarro Tomás indica que la consonante oclusiva
bilabial sonora, seguida de la oclusiva dental sorda (obtener, obturador, subterráneo,
subteniente), se realiza como sorda [p] en la pronunciación lenta y esmerada, y como
aproximante [![]() ], más o menos sorda, en la pronunciación relajada y
en la conversación familiar.
], más o menos sorda, en la pronunciación relajada y
en la conversación familiar.
La pronunciación con oclusiva sorda implica la aplicación de un proceso de refuerzo, que consideraremos propio del habla enfática. Si no se aplica ningún proceso que afecte a la tensión (debilitamiento y refuerzo), se mantiene la oclusiva sonora. Asumiremos que las oclusivas sonoras se relajan siempre (no están sometidas a restricciones); en este contexto se aplican los procesos de debilitamiento y asimiliación a la sordez, por los que resulta una aproximante ensordecida. El comportamiento es el mismo para las combinaciones de oclusivas homorgánicas y no homorgánicas, y ante africada; aunque, en el primer caso, la coarticulación en un mismo punto tienda a ser más débil, con tendencia a la elisión.
(3.1) /oclusiva sonora/ - /oclusiva sorda/ (no homorgánicas)
/oclusiva sonora/ - /oclusiva sorda/ -----> [aproximante
ensordecida] - [oclusiva sorda]Tabla 30: Ejemplos de las realizaciones de los fonemas oclusivos sonoros ante consonante oclusiva sorda no homorgánica.
|
(3.2) /oclusiva sonora/ - /oclusiva sorda/ (homorgánicas)
/oclusiva sonora/ - /oclusiva sorda/ -----> [aproximante
ensordecida] - [oclusiva sorda]Tabla 31: Ejemplos de las realizaciones de los fonemas oclusivos sonoros ante consonante oclusiva sorda homorgánica.
|
(3.3) /oclusiva sonora/ - /africada sorda/.
/oclusiva sonora/ - /africada sorda/ -----> [aproximante
ensordecida] - [africada sorda]Tabla 32: Ejemplos de las realizaciones de los fonemas oclusivos sonoros ante la consonante africada.
|
Posición final absoluta.
1. /oclusiva sonora/ final ----> [aproximante]
2. /oclusiva sorda/ final ----> [oclusiva sorda]
Navarro Tomás (1918: § 125) señala la tendencia
al debilitamiento de las sonoras, que asumiremos en este trabajo. Las sordas también
pueden debilitarse; por ejemplo, la c final de algunas palabras de origen
extranjero se pronuncia también corrientemente implosiva y relajada, llegando a
realizarse a veces como una [![]() ] más o menos sorda: frac, coñac, vivac, bock, cok.
Sin embargo, creemos que en el habla culta se tendería a realizarlas, por lo que no se
aplicará el proceso de debilitamiento.
] más o menos sorda: frac, coñac, vivac, bock, cok.
Sin embargo, creemos que en el habla culta se tendería a realizarlas, por lo que no se
aplicará el proceso de debilitamiento.
Tabla 33: Ejemplos de las realizaciones de los fonemas oclusivos sordos y sonoros en posición final.
|
Resumiendo la exposición que hemos realizado, proponemos que el proceso de debilitamiento se aplicará sin restricciones en las oclusivas sonoras; las sordas también se debilitan excepto en posición final absoluta y ante una consonante con igual grado de tensión. Como consecuencia de la realización implosiva de las sordas en la distensión silábica, éstas se eliden ante oclusiva (sorda y sonora) homorgánica. Con el proceso de debilitamiento concurren fenómenos de asimilación de la sordez y de la nasalidad. En la Tabla 34 representamos la aplicación (« + ») o no (« - ») del proceso de debilitamiento de los fonemas oclusivos en la distensión silábica. En la fila izquierda se consignan las consonantes situadas en la posición final de sílaba y en las columna superior, el contexto siguiente:
Tabla 34: Contextos de debilitamiento de los fonemas oclusivos en la distensión silábica.
FINAL |
CONSONANTE [+tensa] |
CONSONANTE [±tensa] |
CONSONANTE [-tensa] |
|
OCLUSIVA SORDA: [+tensa] |
- |
- |
+ |
+ |
OCLUSIVA SONORA: [±tensa] |
+ |
+ |
+ |
+ |
La neutralización de los fonemas oclusivos sordos y sonoros en la distensión silábica está representada en la Tabla 35, siguiendo la definición expuesta al principio de este capítulo (cf. supra, § 5.1); marcamos con un recuadro en negro las realizaciones en un mismo contexto de cada par de fonemas.
Tabla 35: Neutralización de los fonemas oclusivos en la distensión silábica.
Contexto |
/p/ |
/b/ |
/t/ |
/d/ |
/k/ |
/g/ |
ante oclusiva sorda homorgánica |
Ø |
[ |
Ø |
[ |
Ø |
[ |
ante oclusiva sorda no homorgánica |
/p/ |
[ |
/t/ |
[ |
/k/ |
[ |
ante oclusiva sonora homorgánica |
Ø |
[b] |
Ø |
[d] |
Ø |
[g] |
ante oclusiva sonora no homorgánica |
[ |
[ |
[ |
[ |
[ |
[ |
ante africada sorda |
/p/ |
[ |
/t/ |
[ |
/k/ |
[ |
ante nasal /m/ |
[ |
[m] |
[ |
[ |
[ |
[ |
ante nasal /n/ y / |
[ |
[ |
[ |
[ |
[ |
[ |
ante líquida |
[ |
[ |
[ |
[ |
[ |
[ |
ante aproximante labiovelar |
[ |
[ |
[ |
[ |
[ |
[ |
ante fricativa sorda |
[ |
[ |
[ |
[ |
[ |
[ |
posición final ante pausa |
/p/ |
[ |
/t/ |
[ |
[k] |
[ |
5.4.2.1. Fonemas nasales en el ataque silábico.
En posición inicial de sílaba, absoluta e interior de grupo fónico, se realizan los tres fonemas nasales: bilabial /m/, alveolar /n/ y palatal /
5.4.2.2. Fonemas nasales en la distensión silábica.
5.4.2.2.1. Alófonos de los fonemas nasales.
(1) Fonema nasal bilabial /m/.
El fonema nasal bilabial /m/ en posición final de sílaba interior de palabra sólo aparece regularmente ante consonante bilabial (ortográficamente, b y p) y también ante /n/ (por ejemplo, alumna, amnesia, amnistía, columna, enmendar, enmohecer, enmudecer, gimnasia, himno, indemne, insomne, solemne, somnífero, etc.). En cualquier otro contexto los ejemplos son contados (véase Tabla 36). Tampoco es frecuente en posición final absoluta; sólo lo encontramos en algunos préstamos de lenguas modernas, grecismos y latinismos.
Navarro Tomás (1918) no describe la pronunciación de m en posición final de sílaba interior de palabra en otro contexto distinto al de la agrupación formada por nasal y bilabial, sólo se refiere a la posición final absoluta (cf. § 86). En su opinión, el español no admite la nasal bilabial ante pausa (harem, Abraham, máximum, mínimum, ultimátum, álbum), sustituyéndola por la alveolar. Esta sustitución también tiene lugar en el enlace entre palabras ante vocal: álbum hispanoamericano, el ultimátum había llegado inesperadamente. Incluso al silabear con cierta lentitud se prununcia [n] en palabras como em-pe-ra-dor, am-pa-ro y com-prar. De la misma opinión es Quilis (1993: 237), pues afirma que /m/ sólo tiene un alófono, [m], que se produce como tal en posición silábica prenuclear; también Canellada y Madsen (1987: 22) registran esa única distribución. En cambio, Seco (1986: 28), para la palabra álbum, recomienda que "Debe evitarse la pronunciación con /n/ final, /'al.bun/". Desde nuestra competencia, esta recomendación, que extendemos a todo el contexto, refleja la tendencia del hablante culto; en el habla rápida y en un registro familiar y relajado, se tendería a la realización de /m/ final como [n], no así en el habla cuidada. Alcina y Blecua (1975: 317-318) describen la pronunciación con nasal bilabial como una reacción cultista, causada por influjo ortográfico, que produce alternancias [-m] / [-n] en palabras como máximum y álbum, pero esa "reacción" correspondería al registro que transcribimos.
Las asimilaciones de las consonantes nasales al
punto de articulación de la consonante siguiente sólo han sido descritas en español
para la alveolar. Sin embargo, creemos que la nasal bilabial también se asimila ante
consonante labiodental, por la coincidencia del punto de articulación, resultando un
alófono nasal labiodental [![]() ]; en todos los demás contextos, /m/ se realiza como
[m]. La Figura 9 esquematiza el proceso de labiodentalización de la nasal bilabial:
]; en todos los demás contextos, /m/ se realiza como
[m]. La Figura 9 esquematiza el proceso de labiodentalización de la nasal bilabial:
Figura 9: Labiodentalización de /m/.
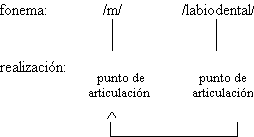 |
En la Tabla 36 mostramos ejemplos del fonema /m/ en la distensión silábica, con los pocos casos registrados en el interior de palabra.
Tabla 36: Ejemplos del fonema nasal bilabial /m/ en la distensión silábica.
|
combinación |
interior de palabra |
enlace entre palabras |
realización |
| 1. /m/ - /bilabial/ | /m/ - /p/ /m/ - /b/ /m/ - /m/ | campo bomba digamma |
réquiem perdido currículum vitae módem moderno |
[m] - [p] [m] - [b] [m] - [m] |
| 2. /m/ - /labiodental/ | /m/ - /f/ | (no registrado) |
ultimátum final |
[ |
| 3. /m/ - /interdental/ | /m/ - / |
circumcirca |
álbum ceniciento |
[m] - [ |
| 4. /m/ - /dental/ | /m/ - /t/ /m/ - /d/ | comto dumdum |
delírium trémens tedéum discordante |
[m] - [t] [m] - [d] |
| 5. /m/ - /alveolar/ | /m/ - /s/ /m/ - /l/ /m/ - /r/ /m/ - /n/ | (no registrado)19 (no registrado) (no registrado) alumno |
quórum suficiente réquiem lúgubre álbum roto vademécum nuevo |
[m] - [s] [m] - [l] [m] - [r] [m] - [n] |
| 6. /m/ - /palatal/ | /m/ - / |
(no registrado) (no registrado) (no registrado) (no registrado) |
referéndum yemení solárium chico álbum llamativo factótum ñoño |
[m] - [ |
| 7. /m/ - /velar/ | /m/ - /k/ /m/ - /g/ /m/ - /x/ /m/ - /w/ | (no registrado) (no registrado) (no registrado) (no registrado) |
tótem canadiense tándem ganador armónium japonés factótum huesudo |
[m] - [k] [m] - [g] [m] - [x] [m] - [w] |
(2) Fonema nasal alveolar /n/.
El fonema nasal alveolar /n/, en la distensión silábica, asimila su punto de articulación al de la consonante siguiente, en el interior de palabra y entre palabras. Consideraremos que cuando dicha consonante es una alveolar, también se produce asimilación, aunque el resultado sea la coincidencia con el alófono no marcado por la variación contextual, [n]. En la Figura 10 esquematizamos el proceso de asimilación. La Tabla 37 contiene los correspondientes ejemplos.
Figura 10: Proceso de asimilación del fonema nasal alveolar
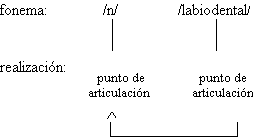 |
Tabla 37: Ejemplos de las asimilaciones del fonema nasal alveolar /n/.
combinación |
interior de palabra |
enlace entre palabras |
realización |
|
| 1. /n/ - /bilabial/ | /n/ - /p/ /n/ - /b/ /n/ - /m/ | imposible imborrable inmaduro |
un pato un beso un mero |
[m] - [p] [m] - [b] [m] - [m] |
| 2. /n/ - /labiodental/ | /n/ - /f/ | confuso |
un foso |
[ |
| 3. /n/ - /interdental/ | /n/ - / |
concierto |
un ciervo |
[ |
| 4. /n/ - /dental/ | /n/ - /t/ /n/ - /d/ | santo sándalo |
un tiesto un dado |
[ |
| 5. /n/ - /alveolar/ | /n/ - /s/ /n/ - /l/ /n/ - /r/ /n/ - /n/ | cansado enlace inri innecesario |
un santo un lazo un ruso un niño |
[n] - [s] [n] - [l] [n] - [r] [n] - [n] |
| 6. /n/ - /palatal/ | /n/ - / |
enyesar concha conlleva (no registrado) |
un yate un chorizo un llanto un ñame |
[nj] - [ |
| 7. /n/ - /velar/ | /n/ - /k/ /n/ - /g/ /n/ - /x/ /n/ - /w/ | cinco ingrato injertar enhuerar |
un coche un gato un jamón un hueso |
[ |
Coincidimos con Martínez Celdrán (1989) y Quilis
(1993) en considerar la realización de /n/ ante consonante palatal como un sonido nasal
palatalizado [nj] distinto a una nasal palatal [![]() ] (la palatalización de la
nasal es inevitable por la coarticulación con la consonante siguiente). Los datos
fonéticos que aportan corroboran la impresión auditiva de una clara diferencia entre
ambas realizaciones. Desde el punto de vista fonológico, se puede formular un principio
caracterizador del español: la nasal palatal no forma parte del paradigma de segmentos
posibles en la distensión silábica, bajo ninguna condición, ni como realización de un
fonema nasal palatal ni como resultado de una asimilación a una consonante palatal.
] (la palatalización de la
nasal es inevitable por la coarticulación con la consonante siguiente). Los datos
fonéticos que aportan corroboran la impresión auditiva de una clara diferencia entre
ambas realizaciones. Desde el punto de vista fonológico, se puede formular un principio
caracterizador del español: la nasal palatal no forma parte del paradigma de segmentos
posibles en la distensión silábica, bajo ninguna condición, ni como realización de un
fonema nasal palatal ni como resultado de una asimilación a una consonante palatal.
Tanto en posición final absoluta como en la resilabación ante vocal: un amigo ['u.na.'mi.go], el fonema nasal alveolar se realiza como la variante no marcada por el contexto, [n]; los casos documentados de velarización no pertenecen al habla estándar (cf. Alcina y Blecua, 1975: 356-359; Navarro Tomás, 1918: § 130; Quilis, 1993: § 7.8.1; y D'Introno et al., 1995: 309).
Navarro Tomás (1918: § 110) describe una pronunciación de [n] débil, breve y relajada en las sílabas ins, cons y trans, que "a veces se reduce a una pequeña nasalización de la vocal precedente, y a veces se pierde por completo; la conservación total de la n en dichas sílabas tiene un carácter afectadamente culto; su pérdida es constante en el habla popular; la pronunciación correcta, en este como en otros casos, se sirve [...] de variantes intermedias más o menos próximas a uno y otro extremo, según la ocasión y el tono en que se habla". La misma variante débil se realiza en posición final ante pausa: "la lengua suele quedar adherida a los alvéolos más tiempo del que duran la presión del aire espirado y las vibraciones vocálicas; la articulación en parte, acaba, por consiguiente, muda". En el DEFE no transcribiremos ningún grado de relajación.
Debemos resolver qué fonema transcribir, /m/ o /n/, ante consonante bilabial, en palabras como imposible o imborrable, en las que la segmentación de la palabra indica la presencia de una forma con fonema alveolar (en los ejemplos citados, el prefijo /in-/20).
Según la norma ortográfica, ante las consonantes b y p debe escribirse m y no n. Esta regla refleja la pronunciación: precediendo a un fonema bilabial siempre se realiza una nasal bilabial y no una alveolar, pero de modo imperfecto, ya que omite un grafema que representa otra consonante del mismo orden, m , y por razones etimológicas crea una disimetría con v, que también representa el fonema oclusivo bilabial, pues ante esta letra se escribe n y no m. La cuestión es qué fonemas representan las letras m y n de los grupos ortográficos mb, mp, nm y nv. Una lectura regular de la ortografía transcribiría m como /m/ y n como /n/, pero ya hemos mostrado que existen irregularidades en el sistema ortográfico. Allí donde siempre se realiza un sonido nasal bilabial debería transcribirse un fonema nasal bilabial, independientemente de su representación grafemática; así, no hay fundamento para defender la existencia de un fonema nasal alveolar en palabras como bomba, trompa, enmendar y anverso. El conflicto surge cuando es posible identificar formas internas con ese fonema21; citaremos algunos ejemplos:
(2) También el primer componente de balompié, balonmano, balonvolea y baloncesto, balón /ba.'lon/, se realizaría con alveolar en la palabra aislada, pero como el fonema /n/ se asimila al punto de articulación de la consonante siguiente (en el decurso y en interior de palabra), resulta en los tres primeros ejemplos un sonido nasal bilabial y en el último, uno nasal interdentalizado.
(3) En los parasintéticos formados a partir de un sustantivo, X, con el prefijo /en-/ y un sufijo verbalizador, y el significado general de 'meter en X', existen ejemplos para todos los casos de asimilación de la nasal al punto de articulación de la consonante siguiente: bilabial (embotellar), labiodental (enfrascar), interdental (encepar), dental (enterrar), alveolar (ensilar), palatal (enyugar) y velar (encapachar). Cuando el sustantivo empieza por vocal y la nasal no está marcada por el contexto consonántico siguiente, se realiza una nasal alveolar, por ejemplo: enaguar, enaceitar, enarenar.
Si atendemos a la forma interna de las palabras
complejas que hemos mencionado, deberíamos transcribirlas con fonema nasal alveolar,
puesto que así constan sus elementos componentes como formas simples; es lógico pensar
que la secuencia fonémica se mantiene. Sin embargo, en el DEFE no consta la
transcripción fonémica interna de las palabras, sino el resultado de aquellos procesos
morfofonológicos que hayan intervenido en la configuración de la forma fonémica final.
Así, en las segundas personas del plural de los imperativos con pronombre enclítico, por
ejemplo, callaos, en las que se elide sistemáticamente la /![]() / (callad),
la transcripción no reproduce la forma interna de la palabra, /
/ (callad),
la transcripción no reproduce la forma interna de la palabra, /![]()
![]() .'
.'![]()
![]()
![]() .
.![]()
![]() /, sino el
resultado fonológico de la formación, /
/, sino el
resultado fonológico de la formación, /![]()
![]() .'
.'![]()
![]() .
.![]()
![]() /. El plural balones no ha de ser transcrito
/ba.'lon.es/, sino /ba.'lo.nes/, con la resilabación correspondiente; y balonazo
será /
/. El plural balones no ha de ser transcrito
/ba.'lon.es/, sino /ba.'lo.nes/, con la resilabación correspondiente; y balonazo
será /![]()
![]() .
.![]()
![]() .'
.'![]()
![]() .
.![]()
![]() / y no /
/ y no /![]()
![]() .'
.'![]()
![]() .'
.'![]()
![]() .
.![]()
![]() /, con resilabación y pérdida del acento de la raíz22. Existen procesos morfofonológicos (elisiones,
resilabaciones y reacentuaciones) que afectan significativamente a la forma fonémica de
las palabras complejas, que están motivados por su complejidad, y que se reflejan en la
transcripción; creemos que es lícito incluir entre ellos la asimilación de la nasal
ante consonante bilabial: si en una palabra compleja se realiza siempre una nasal bilabial
y ésta tiene carácter de fonema, ha de constar en la transcripción (no constarían las
realizaciones que no tienen ese carácter). Un caso semejante es el de /'rei/ - /'
/, con resilabación y pérdida del acento de la raíz22. Existen procesos morfofonológicos (elisiones,
resilabaciones y reacentuaciones) que afectan significativamente a la forma fonémica de
las palabras complejas, que están motivados por su complejidad, y que se reflejan en la
transcripción; creemos que es lícito incluir entre ellos la asimilación de la nasal
ante consonante bilabial: si en una palabra compleja se realiza siempre una nasal bilabial
y ésta tiene carácter de fonema, ha de constar en la transcripción (no constarían las
realizaciones que no tienen ese carácter). Un caso semejante es el de /'rei/ - /'![]()
![]() .
.![]()
![]() s/, con
resilabación y consonantización: en la transcripción fonémica de la forma singular
constará el fonema vocálico palatal, en la transcripción fonémica de la forma plural,
el fonema consonántico homorgánico.
s/, con
resilabación y consonantización: en la transcripción fonémica de la forma singular
constará el fonema vocálico palatal, en la transcripción fonémica de la forma plural,
el fonema consonántico homorgánico.
Por tanto, en todas las palabras del DEFE transcribiremos los grupos ortográficos mb, mp, nm y nv como las secuencias fonémicas /mb/, /mp/, /mm/ y /mb/, respectivamente. Esta decisión tiene una ventaja para un sistema de transcripción fonética automática, que debemos mencionar: el sistema de reglas contextuales que aplicamos no podría diferenciar entre un fonema nasal alveolar y uno bilabial en estos casos a partir de la ortografía, sería necesario introducir un analizador morfológico –un instrumento de gran interés lingüístico, pero muy costoso para nuestros objetivos– que detectara los elementos integrantes de las palabras complejas:
| enmendar : n --> /m/ balonmano = balón + mano : n --> /n/ bomba : m --> /m/ embotellar : em + botella + ar : m --> /n/23 |
En la posición no marcada por el contexto
encontramos los dos fonemas laterales tradicionalmente clasificados en español: alveolar
/l/ y palatal /![]() /, tanto en el interior de palabra como en el enlace
entre palabras, sin variación alofónica. No transcribiremos la pronunciación yeísta,
que sustituye el fonema lateral palatal por el que clasificaremos como oclusivo palatal
sonoro; es un fenómeno ampliamente extendido, pero consideraremos que no corresponde a la
norma estándar. Entre las reglas de transcripción grafema-fonema podemos incluir una
opcional que dé cuenta de este fenómeno, pero no la aplicaremos en la generación del
diccionario.
/, tanto en el interior de palabra como en el enlace
entre palabras, sin variación alofónica. No transcribiremos la pronunciación yeísta,
que sustituye el fonema lateral palatal por el que clasificaremos como oclusivo palatal
sonoro; es un fenómeno ampliamente extendido, pero consideraremos que no corresponde a la
norma estándar. Entre las reglas de transcripción grafema-fonema podemos incluir una
opcional que dé cuenta de este fenómeno, pero no la aplicaremos en la generación del
diccionario.
La realización alveolar del fonema /l/ se da tembién en los grupos tautosilábicos formados con una obstruyente: oclusiva bilabial /p/ y /b/ (plaza, cable), oclusiva velar /k/ y /g/ (clon, globo) y fricativa /f/ (flaco); y en palabras como sublingual y sublunar, en las que el grupo de obstruyente /b/ y /l/ es heterosilábico.
Como en otras series de fonemas, se han de determinar los alófonos que se realizan en la distensión silábica y su neutralización.
5.4.3.2. Fonemas laterales en la distensión silábica. 5.4.3.2.1. Alófonos de los fonemas laterales.En esta posición sólo se realiza la lateral alveolar. Indica Navarro Tomás (1918: § 114) que "la l final de sílaba toma el punto de articulación de la consonante siguiente"; los contextos que describe son: ante interdental, ante dental y palatal. Esta descripción es común en la bibliografía del español; por ejemplo, en Alcina y Blecua (1975: 359-360), Canellada y Madsen, (1987: 22) y Quilis (1993: 310). La asimilación de la lateral excluye, por tanto, las zonas de articulación extrema: labial (bilabial y labiodental) y velar (velar y labiovelar). Puesto que el punto articulación alveolar queda dentro del área de asimilación, podemos admitir que también allí se realiza el proceso, aunque el resultado sea coincidente con el alófono no marcado por el contexto: las realizaciones del fonema lateral alveolar en la distensión silábica toman el punto de articulación de la consonante siguiente siempre que ésta sea interdental, dental, alveolar y palatal. La Figura 11 esquematiza ese proceso.
Figura 11: Proceso de asimilación del fonema lateral alveolar.
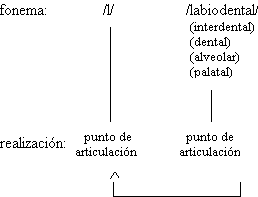 |
Como ya comentamos en la revisión bibliográfica,
no hay un total acuerdo sobre qué variante se realiza ante palatal. Desde nuestra
competencia, coincidimos con Martínez Celdrán (1989) y Quilis (1993) en que la
realización no es una lateral palatal [![]() ] como la que se realiza en el ataque silábico (llave
['
] como la que se realiza en el ataque silábico (llave
['![]() a.
a.![]() e]), sino una
lateral palatalizada [lj]. Al igual que sucede en la serie nasal, la lateral
palatal no forma parte del paradigma de segmentos posibles en la distensión silábica,
bajo ninguna condición, ni como realización de un fonema lateral palatal ni como
resultado de una asimilación a una consonante palatal. La Tabla 38 contiene ejemplos de
las realizaciones del fonema lateral alveolar en la distensión silábica24.
e]), sino una
lateral palatalizada [lj]. Al igual que sucede en la serie nasal, la lateral
palatal no forma parte del paradigma de segmentos posibles en la distensión silábica,
bajo ninguna condición, ni como realización de un fonema lateral palatal ni como
resultado de una asimilación a una consonante palatal. La Tabla 38 contiene ejemplos de
las realizaciones del fonema lateral alveolar en la distensión silábica24.
Tabla 38. Ejemplos de las realizaciones del fonema lateral alveolar /l/ en la distensión silábica.
combinación |
interior de palabra |
enlace entre palabras |
realización |
|
| 1. /l/ - /bilabial/ | /l/ - /p/ /l/ - /b/ /l/ - /m/ | alpaca alba alma |
el pato el beso el mero |
[l] - [p]
[l] - [ |
| 2. /l/ - /labiodental/ | /l/ - /f/ | alfabeto |
el foso |
[l] - [f] |
| 3. /l/ - /interdental/ | /l/ - / |
alce |
el ciervo |
[ |
| 4. /l/ - /dental/ | /l/ - /t/ /l/ - /d/ | alto aldea |
el tiesto el dado |
[ |
| 5. /l/ - /alveolar/ | /l/ - /s/ /l/ - /l/ /l/ - /r/ /l/ - /n/ | bolsa (no registrado) alrededor balneario |
el santo el lazo el ruso el niño |
[l] - [s] [l] - [l] [l] - [r] [l] - [n] |
| 6. /l/ - /palatal/ | /l/ - / |
(no registrado) colcha (no registrado) (no registrado) |
el yate el chorizo el llanto el ñame |
[lj] - [ |
| 7. /l/ - /velar/ | /l/ - /k/ /l/ - /g/ /l/ - /x/ /l/ - /w/ | alcón alga aljibe (no registrado) |
el coche el gato el jamón el hueso |
[l] - [k]
[l] - [ |
La realización alveolar del fonema /l/ será también la de los grupos tautosilábicos /ls/ en la distensión silábica (solsticio) y en la posición final absoluta (vals). Para este último contexto Navarro Tomás (1918: § 111) describe una pronunciación relajada que no transcribiremos.
5.4.3.2.2. Neutralización de los fonemas laterales.Si el fonema lateral palatal no se realiza en la distensión silábica, no puede neutralizarse con el alveolar. Es un caso análogo al de las consonantes nasales, como también señalaron Martínez Celdrán (1989) y Quilis (1993). Para nosontros, la alternancia entre las laterales alveolar y palatal en palabras emparentadas, como el / ella y docel / doncella, ha de ser explicada desde la alomorfia y no como variación contextual.
5.4.4. Consonantes vibrantes. 5.4.4.1. Fonemas vibrantes en el ataque silábico.Existe una asimetría en la distribución de los fonemas vibrantes en el ataque silábico
En los grupos tautosilábicos formados con oclusiva bilabial /p/ y /b/ (prado, comprar, brazo, fábrica), oclusiva dental /t/ y /d/ (trazo, pétreo, drama, nodriza), oclusiva velar /k/ y /g/ (cromo, concretar, gramo, agrónomo) y fricativa labiodental /f/ (frase, cofrade), se realiza siempre la vibrante simple (cf. Navarro Tomás, 1918: § 112). No transcribiremos la vocal esvarabática que suele intercalarse entre las dos consonantes de estos grupos (cf. Navarro Tomás, 1918: § 113, y Quilis, 1993: 337-342); lo consideraremos como un elemento de transición entre ambas.
En posición inicial de palabra
sólo aparece la vibrante múltiple (rosa /'ro.sa/). En posición inicial de
sílaba interior de palabra encontramos ambos fonemas, pero en contextos fonémicos
distintos: tras vocal, las dos vibrantes: caro /'ka.![]() o/, carro /'ka.ro/; tras
consonante, sólo la múltiple. En esos dos contextos, la vibrante múltiple puede
aparecer en palabras simples, o en palabras complejas —prefijadas o compuestas—
formadas por una simple que empieza por vibrante múltiple; en la Tabla 39, mostramos los
correspondientes ejemplos.
o/, carro /'ka.ro/; tras
consonante, sólo la múltiple. En esos dos contextos, la vibrante múltiple puede
aparecer en palabras simples, o en palabras complejas —prefijadas o compuestas—
formadas por una simple que empieza por vibrante múltiple; en la Tabla 39, mostramos los
correspondientes ejemplos.
Tabla 39: Ejemplos de la vibrante múltiple en posición inicial de sílaba interior de palabra.
Contexto |
Ejemplos |
Vocal - /r/ |
Formas simples: carro, gorro, perro Formas complejas: arrítmico, grecorromano, pararrayos |
Consonante - /r/ |
|
/l/ - /r/25 |
Formas simples: alrota Formas complejas: alrededor |
/n/ - /r/ |
Formas simples: honrar, inri, pinrel, runrún Formas complejas: enrejar, enrojecer, sinrazón |
/s/ - /r/ |
Formas simples: disruptivo, israelí, israelita26 Formas complejas: desrizar, posromántico, trasroscarse |
/ |
Formas simples: azre Formas complejas: (no registrado) |
/b/ - /r/ |
Formas simples: (no registrado) Formas complejas: subrayar, subrogar, subrepticio, abrogar |
Como podemos observar en la tabla de ejemplos, pocas son las
consonantes que preceden a una vibrante múltiple formando una agrupación heterosilábica
interior de palabra. En la bibliografía se mencionan las alveolares /l/, /n/ y /s/. Hemos
localizado un ejemplo para la fricativa interdental /![]() /, el sustantivo antiguo azre (arce:
'árbol de la familia de las aceráceas'); también existe el nombre propio extranjero Ezra.
La oclusiva /b/ sólo aparece en formas complejas en las que identificamos los
prefijos cultos /sub-/ y /ab-/. Que no existan otras combinaciones en posisión interior
no implica que no sean posibles: las tenemos en el enlace entre palabras; la única
restricción es la distribución defectiva de las palatales /
/, el sustantivo antiguo azre (arce:
'árbol de la familia de las aceráceas'); también existe el nombre propio extranjero Ezra.
La oclusiva /b/ sólo aparece en formas complejas en las que identificamos los
prefijos cultos /sub-/ y /ab-/. Que no existan otras combinaciones en posisión interior
no implica que no sean posibles: las tenemos en el enlace entre palabras; la única
restricción es la distribución defectiva de las palatales /![]() /, /
/, /![]() / y /
/ y /![]() /, de la labiovelar /w/ y de la
misma vibrante múltiple en la coda silábica.
/, de la labiovelar /w/ y de la
misma vibrante múltiple en la coda silábica.
La Tabla 40 contiene ejemplos de las combinaciones Consonante - /r/ en el enlace entre palabras:
Tabla 40: Ejemplos del fonema vibrante múltiple /r/ en el enlace entre palabras.combinación |
ejemplo |
|
| 1. /bilabial/ - /r/ | /p/ - /r/ /b/ - /r/ /m/ - /r/ | clip roto club romano álbum rojo |
| 2. /labiodental/ - /r/ | /f/ - /r/ | rosbif recalentado |
| 3. /interdental/ - /r/ | / |
antifaz rojo |
| 4. /dental/ - /r/ | /t/ - /r/ /d/ - /r/ | ballet ruso sed realistas |
| 5. /alveolar/ - /r/ | /s/ - /r/
/l/ - /r/
/ |
dos rosas el rosal mar rugiente corazón roto |
| 6. /palatal/ - /r/ | / |
sándwich rancio |
| 7. /velar/ - /r/ | /k/ - /r/ /g/ - /r/ /x/ - /r/ | anorak rojo bulldog rabioso reloj retrasado |
En la Tabla 41 resumimos la distribución de los fonemas vibrantes en el ataque silábico; modifica la que reelaboramos a partir de los datos de Martínez Celdrán (1989) (cf. supra, § 4.3.2).
Tabla 41: Distribución de los fonemas vibrantes en el ataque silábico.
/ |
/r/ |
Distribución |
- |
+ |
Inicial de palabra |
- |
+ |
Inicial de sílaba
interior de palabra tras consonante (/n/, /l/, /s/, / |
+ |
+ |
Inicial de sílaba interior de palabra intervocálica |
+ |
- |
Grupos consonánticos tautosilábicos con /p/, /t/, /k/, /b/, /d/, /g/ y /f/ |
5.4.4.2. Fonemas vibrantes en la distensión silábica.
En posición final de sílaba, la realización de
las vibrantes como simple o múltiple depende del énfasis que se imprima a la
pronunciación, al menos ante pausa (mar) y ante consonante, tanto en el
interior de palabra (marmota) como entre palabras (mar
tempestuoso). Cuando la vibrante precede a una vocal, en el decurso, y resilabea (mar
azul), se realiza como simple y no como múltiple. Este hecho nos hace considerar la
vibrante simple /![]() / como el único fonema de esta serie consonántica que
se realiza en posición implosiva. Cuando la vibrante resilabea ante vocal y pasa de la
posición de coda a la ataque silábico, deja de estar marcada por el contexto; si se
realiza como vibrante simple, el fonema es vibrante simple. Por tanto, en la distensión
silábica existe distribución defectiva de los fonemas vibrantes, como ocurre en la
posición de ataque, y no se produce neutralización.
/ como el único fonema de esta serie consonántica que
se realiza en posición implosiva. Cuando la vibrante resilabea ante vocal y pasa de la
posición de coda a la ataque silábico, deja de estar marcada por el contexto; si se
realiza como vibrante simple, el fonema es vibrante simple. Por tanto, en la distensión
silábica existe distribución defectiva de los fonemas vibrantes, como ocurre en la
posición de ataque, y no se produce neutralización.
La realización de una vibrante múltiple en la
distensión silábica es enfática, depende de la elección individual del hablante en una
situación comunicativa determinada, por eso siempre transcribiremos el alófono vibrante
simple en ese contexto (la variante que consideramos no marcada), incluyendo el grupo
tautosilábico /![]()
![]() / (perspicacia).
/ (perspicacia).
Existe un caso de elisión de la vibrante simple final de palabra que tendremos en cuenta. Este proceso se aplicará cuando en el decurso vaya seguida de una vibrante múltiple, inicial de la palabra siguiente (mar Rojo). Se trataría de dos consonantes homorgánicas, con el mismo modo de articulación y, aunque ambas son sonoras, su comportamiento es similar al de las oclusivas sordas, ya descrito (cf. supra, § 5.4.1.2.2.2):
/vibrante simple/ - /vibrante múltiple/ -----> Ø - [vibrante múltiple]
.En la articulación de la vibrante simple el ápice de la lengua realiza una breve oclusión en los alvéolos; cuando en el decurso le sigue una vibrante múltiple, esa breve oclusión coincide con la primera de las breves oclusiones con las que se articula la múltiple, resultando un único sonido.
La Tabla 42 recoge ejemplos de las realizaciones de la vibrante simple en la distensión silábica.
Tabla 42: Ejemplos de las realizaciones del fonema vibrante simple /
combinación |
interior de palabra |
enlace entre palabras |
realización |
|
| 1. / |
/ |
arpía árbol arma |
mar proceloso mar bravo mar Muerto |
[ |
| 2. / |
/ |
morfema |
ser feliz |
[ |
| 3. / |
/ |
marzo |
mar celeste |
[ |
| 4. / |
/ |
arte arder |
mar tranquilo amor divino |
[ |
| 5. / |
/ |
acartonarse aguachirle (no registrado) cuerno |
mar salado amor loco mar Rojo comer nueces |
[ |
| 6. / |
/ |
(no registrado) corcho (no registrado) (no registrado) |
comer yemas comer chorizo mar llameante amor ñoño |
[ |
| 7. / |
/ |
arca cargo alergia darwinismo |
ser querido ser goloso comer jamón comer huevo |
[ |
Navarro Tomás (1918: § 114) describe una vibrante
fricativa [ ],
producto de la relajación del habla familiar: "En la fricativa el movimiento de la
lengua es más lento y suave que en la vibrante; la tensión muscular es menor; la punta
de la lengua se aproxima a los alvéolos, sin llegar a formar con ellos un contacto
completo; la r fricativa es prolongable; la vibrante, momentánea". Los
contextos de realización de este alófonos son, principalmente, en posición
intervocálica (sustituyendo a la vibrante simple) y en posición final ante pausa, aunque
puede aparecer en cualquier otro contexto (cf. Navarro Tomás, 1918: § 114). Quilis (1981
y 1993) no menciona este alófono y Canellada y Madsen (1987: 23) lo clasifican como
aproximante, al igual que Martínez Celdrán (1989: 92-93). Este autor no lo integra en su
clasificación del sistema fonológico del español: "Teniendo en cuenta que este
alófono es una realización absolutamente esporádica, que no tiene un contexto fijo y
que, cuando se presenta, se trata de una variante aún más relajada que la laxa
correspondiente, lo mejor sería prescindir de ella por ser del todo ocasional. [...] No
conviene a la fonología descender a los detalles de la fonética ni tampoco tener en
cuenta fenómenos ocasionales. El hábito de transcribir esta variante [...] se debe a la
influencia de Navarro Tomás". En el DEFE tampoco tendremos en cuenta este alófono
como variante del fonema /
],
producto de la relajación del habla familiar: "En la fricativa el movimiento de la
lengua es más lento y suave que en la vibrante; la tensión muscular es menor; la punta
de la lengua se aproxima a los alvéolos, sin llegar a formar con ellos un contacto
completo; la r fricativa es prolongable; la vibrante, momentánea". Los
contextos de realización de este alófonos son, principalmente, en posición
intervocálica (sustituyendo a la vibrante simple) y en posición final ante pausa, aunque
puede aparecer en cualquier otro contexto (cf. Navarro Tomás, 1918: § 114). Quilis (1981
y 1993) no menciona este alófono y Canellada y Madsen (1987: 23) lo clasifican como
aproximante, al igual que Martínez Celdrán (1989: 92-93). Este autor no lo integra en su
clasificación del sistema fonológico del español: "Teniendo en cuenta que este
alófono es una realización absolutamente esporádica, que no tiene un contexto fijo y
que, cuando se presenta, se trata de una variante aún más relajada que la laxa
correspondiente, lo mejor sería prescindir de ella por ser del todo ocasional. [...] No
conviene a la fonología descender a los detalles de la fonética ni tampoco tener en
cuenta fenómenos ocasionales. El hábito de transcribir esta variante [...] se debe a la
influencia de Navarro Tomás". En el DEFE tampoco tendremos en cuenta este alófono
como variante del fonema /![]() / ya que no parece tener una realización sistemática,
a tenor de lo expresado por Martínez Celdrán; además, en el habla culta y cuidada se
tiende a pronunciar los alófonos vibrantes simple y múltiple, la realización relajada
no corresponde a ese registro. Sin embargo, creemos que la pronunciación de una vibrante
aproximante es mucho más sistemática, por no decir obligada, en el contexto /s.r/ (Israel),
pero lo discutiremos al analizar las consonantes fricativas (cf. infra, § 5.4.5.2).
/ ya que no parece tener una realización sistemática,
a tenor de lo expresado por Martínez Celdrán; además, en el habla culta y cuidada se
tiende a pronunciar los alófonos vibrantes simple y múltiple, la realización relajada
no corresponde a ese registro. Sin embargo, creemos que la pronunciación de una vibrante
aproximante es mucho más sistemática, por no decir obligada, en el contexto /s.r/ (Israel),
pero lo discutiremos al analizar las consonantes fricativas (cf. infra, § 5.4.5.2).
En este trabajo adoptaremos la clasificación
tradicional de español, para la que existen un fonema vibrante simple /![]() / y un fonema
vibrante múltiple /r/. Para Harris (1975 y 1991), en la representación subyacente sólo
consta un solo segmento /
/ y un fonema
vibrante múltiple /r/. Para Harris (1975 y 1991), en la representación subyacente sólo
consta un solo segmento /![]() /; la vibrante múltiple se deriva de una
representación /
/; la vibrante múltiple se deriva de una
representación /![]() -
-![]() /.
/.
Harris (1991: 87-88) parte del siguiente argumento:
la vibrante simple aparece en posición final de sílaba y en ese contexto tiene muy pocas
restricciones; la vibrante múltiple aparece libremente en posición inicial de sílaba:
"Es, por tanto, extraño que encontremos exactamente un hueco [...]: falta [![]()
A esa argumentación se le pueden presentar varias objeciones.
En primer lugar, el punto de partida es inexacto.
Tampoco existen otras combinaciones consonánticas [C - ![]() ]. El mismo Harris (1991: 103, n.
19) reconoce que "también falta [
]. El mismo Harris (1991: 103, n.
19) reconoce que "también falta [![]()
En segundo lugar, la justificación de Harris es
falsa: no se consigue llenar el hueco de [![]()
Finalmente, no entendemos por qué resulta
"natural" considerar que /![]()
La existencia de una vibrante geminada subyacente no
tiene una justificación empírica en la lengua española. Es una mera abstracción, que
puede derivar correctamente segmentos superficiales de segmentos subyacentes, pero está
desviculada de la pronunciación. Navarro Tomás (1918: 176) menciona que "En la
conversación rápida, la vibrante múltiple rr, intervocálica, reparte sus
vibraciones entre las dos sílabas contiguas [...]; pero en pronunciación lenta, toda
articulación de la rr se agrupa únicamente con la segunda vocal"; sin
embargo, esta afirmación no demuestra la existencia de /![]()
Nuestro concepto de fonema —que realiza una
abstracción de la pronunciación del hablante— es incompatible con la
representación subyacente /![]()
Por otro lado, según nuestro concepto de regla
fonológica, ésta ha de dar cuenta de un determinado hecho fónico de la lengua, regular
(de aplicación en todo el léxico que cumpla las condiciones establecidas por las reglas)
o idiosincrásico (que se aplica sólo en determinadas unidades). Puede referirse a la
variación alofónica causada por el contexto fónico, o por factores derivados de la
individualidad del hablante y de la situación comunicativa (que no contemplamos es este
trabajo). También puede referirse a la variación morfológica: las reglas de alomorfia
relacionarían las distintas palabras de una misma familia léxica o de un mismo paradigma
flexivo que presentan una variación formal; tomando casos estudiados por Harris (1975:
cap. 4, y 1991: 70-75), podemos aceptar reglas de diptongación que relacionen tener-tiene
y poder-puedo, y reglas de depalatalización de laterales y nasales que relacionen doncel-doncella
y desdén-desdeñar, porque en estos casos se vinculan formas existentes; sin
embargo, ese no es el caso de la relación /![]()
Si aplicamos el concepto de regla fonológica que seguimos a la representación de la vibrante geminada subyacente propuesta por Harris, el resultado podría ser la elisión de la primera consonante. Según la pronunciación descrita por Navarro Tomás (1918: 175-176), a la que ya hemos hecho referencia, dos consonantes iguales en contacto se realizarían como una sola, relativamente larga y repartida entre las dos sílabas adyacentes, con una menor duración en la primera. La tendencia general en el habla rápida o no cuidada sería la elisión de la primera consonante, simplificando el grupo; se trataría de una manifestación del proceso de debilitamiento característico del español en la distensión silábica. La realización de la vibrante múltiple a partir de la geminada implica un proceso de refuerzo, que no parece responder a la tendencia general de la lengua; la regla de refuerzo que propone el mismo Harris (Regla 2) se aplica en el habla enfática. Además, si la simple y la múltiple heterosilábicas no se suman, tampoco tienen por qué sumarse dos simples para formar una múltiple.
Las consecuencias ventajosas que observa Harris
(1991: 88-89 y 103, n. 21) en la representación de /![]()
Indica el autor que en la lengua española no existen palabras esdrújulas cuya última sílaba empiece por [r]. Además, los hablantes nativos consideran agramaticales palabras inventadas con dicha forma, y precisamente por la acentuación esdrújula:
| Acentuación grave | Acentuación esdrújula | ||
| [ |
[r] | [ |
*[r] |
| avá[ |
chamá[r]a | cáma[ |
*cáma[r]a |
| señó[ |
camó[r]a | víbo[ |
*víbo[r]a |
La agramaticalidad queda justificada si se asume que existe una vibrante geminada heterosilábica subyacente, pues el acento en la antepenúltima sílaba es sistemáticamente imposible en aquellas palabras cuya última sílaba tiene una rima ramificada:
R A
/\ |
k'am
a ![]()
![]() a
a
El problema es que nuestro juicio de gramaticalidad
no coincide con el de los informantes de Harris, tal vez por hablar variantes distintas
del español. Esas secuencias fónicas no existen como palabras de la lengua, pero pueden
ser pronunciadas, y ése es un criterio determinante para juzgar la gramaticalidad.
Evidentemente, si se comparan las palabras existentes cáma[![]() ]a y víbo[
]a y víbo[![]() ]a con
las inexistentes *cáma[r]a y *víbo[r]a, es fácil inducir a
la creencia de que éstas últimas son agramaticales.
]a con
las inexistentes *cáma[r]a y *víbo[r]a, es fácil inducir a
la creencia de que éstas últimas son agramaticales.
Finalmente, muchas palabras —nombres y
adjetivos— cuyo tema derivativo termina en un segmento [-silábico] siempre van
seguidos de uno de los elementos terminales -o, -a, -e, por ejemplo: bruto,
fruta, baile (cf. Harris, 1991: 54-55). En opinión de Harris, este hecho puede
explicar la ausencia de alternancias como amo[![]() ] / *amo[r]es y amo[
] / *amo[r]es y amo[![]() ] / *amo[r]oso:
"Un tema como amorr- requiere un elemento terminal para constituir una
palabra; por lo tanto, aunque las formas flexionadas y derivadas requieran amorr-,
esta forma no puede ser el tema de la palabra amor"; además, "si
supusiéramos que la [r] intervocálica proviene de un segmento simple": /r/,
"no se podría dar cuenta, de modo no estipulativo, de la ausencia de palabras como *amo/r/"
(Harris, 1991: 89). No acabamos de entender su razonamiento, pero no se pueden comparar
estas secuencias. La palabra amo/r/ no existe —evidentemente, tampoco sus
formas flexivas y derivadas— y en amo[
] / *amo[r]oso:
"Un tema como amorr- requiere un elemento terminal para constituir una
palabra; por lo tanto, aunque las formas flexionadas y derivadas requieran amorr-,
esta forma no puede ser el tema de la palabra amor"; además, "si
supusiéramos que la [r] intervocálica proviene de un segmento simple": /r/,
"no se podría dar cuenta, de modo no estipulativo, de la ausencia de palabras como *amo/r/"
(Harris, 1991: 89). No acabamos de entender su razonamiento, pero no se pueden comparar
estas secuencias. La palabra amo/r/ no existe —evidentemente, tampoco sus
formas flexivas y derivadas— y en amo[![]() ] no hay ninguna vibrante intervocálica
subyacente, ni simple ni múltiple; la vibrante es el elemento terminal, como en mujer,
un ejemplo del mismo Harris; no se puede representar ninguna geminada y el único fonema
que el autor reconoce es la vibrante simple: las formas flexivas y derivadas de esa
palabra, en las que se producirá una resilabación y que contendrán un contexto
intervocálico, también se han de representar con vibrante simple.
] no hay ninguna vibrante intervocálica
subyacente, ni simple ni múltiple; la vibrante es el elemento terminal, como en mujer,
un ejemplo del mismo Harris; no se puede representar ninguna geminada y el único fonema
que el autor reconoce es la vibrante simple: las formas flexivas y derivadas de esa
palabra, en las que se producirá una resilabación y que contendrán un contexto
intervocálico, también se han de representar con vibrante simple.
Creemos que el ejemplo de Harris
sólo demuestra que la representación subyacente de amor es /a.'mo![]() /. No menciona
que existe el par caro y carro (con el mismo elemento terminal: -o),
cuyos respectivos temas derivarivos son ca/
/. No menciona
que existe el par caro y carro (con el mismo elemento terminal: -o),
cuyos respectivos temas derivarivos son ca/![]() /- (carísimo) y ca/r/- (carreta).
Ambas palabras requieren el elemento terminal vocálico y sus formas flexivas y derivadas
mantienen la correspondiente vibrante. Si existieran palabras como ca/r/, sin
elemento terminal, con un tema derivativo ca/r/ que apareciera en sus formas
flexivas y derivadas, y se pronunciase ca[
/- (carísimo) y ca/r/- (carreta).
Ambas palabras requieren el elemento terminal vocálico y sus formas flexivas y derivadas
mantienen la correspondiente vibrante. Si existieran palabras como ca/r/, sin
elemento terminal, con un tema derivativo ca/r/ que apareciera en sus formas
flexivas y derivadas, y se pronunciase ca[![]() ] (manteniendo que esa vibrante es la
única posible en posición final en español), se debería cambiar la gramática de la
lengua con una regla de debilitamiento de la vibrante, similar a la de depalatalización
propuesta por el mismo Harris (1991: 70-75) para dar cuenta de variaciones como desdeñar-desdén;
obviamente, nos movemos en el terreno de lo especulativo.
] (manteniendo que esa vibrante es la
única posible en posición final en español), se debería cambiar la gramática de la
lengua con una regla de debilitamiento de la vibrante, similar a la de depalatalización
propuesta por el mismo Harris (1991: 70-75) para dar cuenta de variaciones como desdeñar-desdén;
obviamente, nos movemos en el terreno de lo especulativo.
En posición inicial de sílaba, tras pausa y en el
interior de palabra se realizan cuatro fonemas fricativos sordos, sin variación
alofónica: labiodental /f/, interdental /![]() /, alveolar /s/ y velar /x/. Consideramos
que el fonema clasificado tradicionalmente como fricativo palatal sonoro es oclusivo, pero
lo justificaremos en el apartado
5.4.7.3.
/, alveolar /s/ y velar /x/. Consideramos
que el fonema clasificado tradicionalmente como fricativo palatal sonoro es oclusivo, pero
lo justificaremos en el apartado
5.4.7.3.
En la distensión silábica, interior y final de palabra, la aparición de los fonemas fricativos es desigual: el interdental y el alveolar forman parte del paradigma de consonantes finales propio de la lengua española y tienen pocas restricciones, especialmente /s/, que es la terminación característica de los plurales; en cambio, el labiodental y el velar son extraños en el sistema y aparecen en muy pocas palabras (del velar sólo hay un ejemplo en posición interior, la palabra majzén, un término árabe sin vigencia actual). Esta desigualdad repercute en el tratamiento que la bibliografía dedica a los procesos a los que están sujetos estos fonemas.
(1) Asimilación de la sonoridad.
Este proceso se ha descrito para las fricativas interdental y alveolar: ante consonante sonora, se sonorizan: juzgar, luz dorada [
Figura 12: Sonorización de las fricativas /s/ y /![]() /.
/.
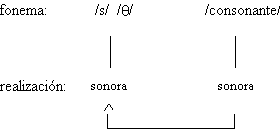 |
(2) Asimilación del punto de articulación.
La fricativa alveolar /s/ final de sílaba se
dentaliza en contacto con consonante dental siguiente, /t/ o /d/, del mismo modo que /l/ y
/n/ en circunstancias análogas; se forma con la punta de la lengua contra la cara
interior de los incisivos superiores, y no contra los alvéolos de estos mismos dientes.
Ante /d/ concurren los fenómenos de asimilación de la sonoridad y del punto de
articulación: desdén [![]() ] (cf. Navarro Tomás, 1918: § 105)29.
] (cf. Navarro Tomás, 1918: § 105)29.
Figura 13: Dentalización de /s/.
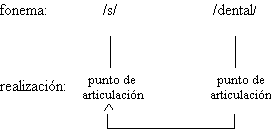 |
(3) Asimilación a la vibrante.
Ante vibrante /r/, la fricativa alveolar /s/ asimila el modo de
articulación vibrante, sin perder el de fricción: [![]() ]; ambas son homorgánicas. En el grupo
/s.r/ (israelita, los reyes), la /s/ se sonoriza como en los casos precedentes;
"pero la punta de la lengua, arrastrada por la enérgica articulación de la vibrante
siguiente, abandona la forma característica de la estrechez redondeada que la punta de la
lengua forma en la s, haciendo perder a ésta su timbre sibilante y produciendo
propiamente, en vez de la z ordinaria y regular, una r fricativa"
(Navarro Tomás, 1918: § 107). La realización de una fricativa sibilante requiere una
pequeña pausa entre ambos segmentos.
]; ambas son homorgánicas. En el grupo
/s.r/ (israelita, los reyes), la /s/ se sonoriza como en los casos precedentes;
"pero la punta de la lengua, arrastrada por la enérgica articulación de la vibrante
siguiente, abandona la forma característica de la estrechez redondeada que la punta de la
lengua forma en la s, haciendo perder a ésta su timbre sibilante y produciendo
propiamente, en vez de la z ordinaria y regular, una r fricativa"
(Navarro Tomás, 1918: § 107). La realización de una fricativa sibilante requiere una
pequeña pausa entre ambos segmentos.
Figura 14: Vibrantización y sonorización de /s/: [![]() ].
].
|
En la transcripción, no tenemos en cuenta variantes debilitadas en posición final absoluta; es un fenómeno general sujeto al énfasis. Navarro Tomás (1918: § 131) menciona el debilitamiento y pérdida de [x] final (reloj), pero consideraremos que en la lengua culta se tiende a su realización.
(5) Elisión.Dos consonantes fricativas homorgánicas en contacto tienden a realizarse como un solo sonido, un poco más largo que lo habitual, con elisión de la situada en posición de coda; seguiría el comportamiento habitual de las consonantes descrito por Navarro Tomás. Las fricativas se realizan sin cierre, por lo que el ruido de fricción puede ser prolongado:
/fricativa X/ - /fricativa X/ -----> Ø - [fricativa X]
En las Tablas 43, 44, 45 y 46 ejemplificamos las realizaciones de los fonemas fricativos en posición final de sílaba.
Tabla 43: Ejemplos de las realizaciones del fonema fricativo interdental
sordo // en la distensión silábica.
combinación |
interior de palabra |
enlace entre palabras |
realización |
|
| 1. / |
/ |
chozpo cabizbajo velozmente |
audaz paladín antifaz veneciano salaz mirada |
[ |
| 2. / |
/ |
(no registrado) |
actriz famosa |
[ |
| 3. / |
/ |
(no registrado) |
luz cenicienta |
Ø - [ |
| 4. / |
/ |
satisfazte mazdeísmo |
atroz tortura haz de espigas |
[ |
| 5. / |
/ |
(no registrado) guzla azre lezna |
pertinaz sequía actriz lituana luz radiante sencillez natural |
[ |
| 6. / |
/ |
(no registrado) (no registrado) (no registrado) (no registrado) |
haz yoga actriz checa tenaz llantina sandez ñoña |
[ |
| 7. / |
/ |
mezquino mayorazgo (no registrado) (no registrado) |
atroz calamidad antifaz granate veloz jinete faz huesuda |
[ |
Tabla 44: Ejemplos de las realizaciones del fonema fricativo alveolar sordo /s/ en la distensión silábica.
combinación |
interior de palabra |
enlace entre palabras |
realización |
|
| 1. /s/ - /bilabial/ | /s/ - /p/ /s/ - /b/ /s/ - /m/ | chispa anfisbena hedonismo |
los perros los barcos los monos |
[s] - [p]
[z] - [ |
| 2. /s/ - /labiodental/ | /s/ - /f/ | asfalto |
las fresas |
[s] - [f] |
| 3. /s/ - /interdental/ | /s/ - / |
ascenso |
las cerillas |
[s] - [ |
| 4. /s/ - /dental/ | /s/ - /t/ /s/ - /d/ | estar desde |
los tomates los dedos |
[ |
| 5. /s/ - /alveolar/ | /s/ - /s/ /s/ - /l/ /s/ - /r/ /s/ - /n/ | dossier isla israelí fresno |
las sábanas los lunes las ratas los niños |
Ø - [s]
[z] - [l]
[ |
| 6. /s/ - /palatal/ | /s/ - / |
desyemar (no registrado) (no registrado) (no registrado) |
las yemas las chicas las llaves los ñus |
[z] - [j]
[s] - [ |
| 7. /s/ - /velar/ | /s/ - /k/ /s/ - /g/ /s/ - /x/ /s/ - /w/ | mosca musgo desjarretar deshuesar |
los quesos las ganancias los gitanos los huevos |
[s] - [k]
[z] - [ |
Tabla 45: Ejemplos de las realizaciones del fonema fricativo labiodental sordo /f/ en la distensión silábica.
combinación |
interior de palabra |
enlace entre palabras |
realización |
|
| 1. /f/ - /bilabial/ | /f/ - /p/ /f/ - /b/ /f/ - /m/ | (no registrado) (no registrado) (no registrado) |
surf peligroso quif bereber quif mortífero |
[f] - [p]
[f] - [ |
| 2. /f/ - /labiodental/ | /f/ - /f/ | affaire |
rosbif frío |
Ø - [f] |
| 3. /f/ - /interdental/ | /f/ - / |
(no registrado) |
puf celeste |
[f] - [ |
| 4. /f/ - /dental/ | /f/ - /t/ /f/ - /d/ | difteria (no registrado) |
quif turco golf divertido |
[f] - [t]
[f] - [ |
| 5. /f/ - /alveolar/ | /f/ - /s/ /f/ - /l/ /f/ - /r/ /f/ - /n/ | (no registrado) (no registrado) (no registrado) rododafne |
rosbif salado quif letal puf rojo puf negro |
[f] - [s] [f] - [l] [f] - [r] [f] - [n] |
| 6. /f/ - /palatal/ | /f/ - / |
(no registrado) (no registrado) (no registrado) (no registrado) |
quif yemení puf chico pandantif llamativo almotazaf ñoño |
[f] - [j]
[f] - [ |
| 7. /f/ - /velar/ | /f/ - /k/ /f/ - /g/ /f/ - /x/ /f/ - /w/ | kafkiano afgano (no registrado) (no registrado) |
rosbif quemado rosbif grasiento rosbif gigantesco almotazaf huesudo |
[f] - [k]
[f] - [ |
Tabla 46: Ejemplos de las realizaciones del fonema fricativo velar sordo /x/ en la distensión silábica.
combinación |
interior de palabra |
enlace entre palabras |
realización |
|
| 1. /x/ - /bilabial/ | /x/ - /p/ /x/ - /b/ /x/ - /m/ | (no registrado) (no registrado) (no registrado) |
balaj persa borraj bebible almoraduj marchito |
[x] - [p]
[x] - [ |
| 2. /x/ - /labiodental/ | /x/ - /f/ | (no registrado) |
erraj fino |
[x] - [f] |
| 3. /x/ - /interdental/ | /x/ - / |
majzén |
troj cerrado |
[x] - [ |
| 4. /x/ - /dental/ | /x/ - /t/ /x/ - /d/ | (no registrado) (no registrado) |
cambuj torcido reloj digital |
[x] - [t]
[x] - [ |
| 5. /x/ - /alveolar/ | /x/ - /s/ /x/ - /l/ /x/ - /r/ /x/ - /n/ | (no registrado) (no registrado) (no registrado) (no registrado) |
troj sucio pedicoj largo carcaj roto reloj nuevo |
[x] - [s] [x] - [l] [x] - [r] [x] - [n] |
| 6. /x/ - /palatal/ | /x/ - / |
(no registrado) (no registrado) (no registrado) (no registrado) |
almoraduj yemení reloj chapeado reloj llamativo boj ñublino |
[x] - [j]
[x] - [ |
| 7. /x/ - /velar/ | /x/ - /k/ /x/ - /g/ /x/ - /x/ /x/ - /w/ | (no registrado) (no registrado) (no registrado) (no registrado) |
pedicoj corto erraj grueso boj jarameño boj hueteño |
[x] - [k]
[x] - [ |
El único fonema africado descrito para el español
estándar es el palatal sordo [![]() ], sin variación alofónica. Se realizaría como tal
en posición inicial de sílaba, su lugar habitual de aparición, y en la lectura a la
española de la representación de la ch final en extranjerismos: caparroch,
crónlech, kirsch, match, sándwich.
], sin variación alofónica. Se realizaría como tal
en posición inicial de sílaba, su lugar habitual de aparición, y en la lectura a la
española de la representación de la ch final en extranjerismos: caparroch,
crónlech, kirsch, match, sándwich.
Como hemos mostrado en la revisión bibliográfica, no existe un total acuerdo sobre qué sonidos consonánticos se realizan en la interpretación fónica de las grafías hi seguida de vocal e y (oclusivo, africado, fricativo o aproximante palatales sonoros) y de hu seguida de vocal (aproximante labiovelar; oclusiva, fricativa o aproximante labializadas sonoras). Es una cuestión que deberemos resolver antes de analizar de qué fonemas son alófonos.
5.4.7.1. Alófonos de la serie palatal.Los trabajos de Monroy Casas (1980) y Martínez Celdrán (1989) contradicen la descripción de Navarro Tomás (1918), tradicionalmente asumida en la bibliografía española. Desde nuestra competencia como hablantes, la pronunciación como africada [
] (en posición inicial de grupo
fónico e interior tras nasal o lateral) y como fricativa [] aparece en posición inicial
absoluta como manifestación de un reforzamiento por parte de algunos hablantes en una
pronunciación cuidada, pero es mucho más frecuente la realización como oclusiva [ No estamos de acuerdo con la distribución de los
alófonos presentada por Monroy Casas. No se realiza la variante oclusiva [![]() ] tras
consonante oclusiva (bilabial, dental y velar) porque en la distensión silábica se
realizan variantes relajadas, que a su vez relajan la palatal: coadyuvar [
] tras
consonante oclusiva (bilabial, dental y velar) porque en la distensión silábica se
realizan variantes relajadas, que a su vez relajan la palatal: coadyuvar [![]()
Creemos que en la pronunciación estándar culta se
diferencia perfectamente entre ['![]()
![]() .
.![]()
![]() ] y ['
] y ['![]()
![]()
![]() .
.![]()
![]()
![]() ]; en esto disentimos de Martínez Celdrán (1989). La
pronunciación de huevo como ['
]; en esto disentimos de Martínez Celdrán (1989). La
pronunciación de huevo como ['![]()
![]()
![]() .
.![]()
![]() ] o ['
] o ['![]()
![]()
![]() .
.![]()
![]() ] no pertenecen al habla culta y cuidada. Las puede
realizar el hablante, pero son propias del habla familiar y relajada, o dialectal. Desde
la perspectiva de una variedad lingüística de prestigio, no son realizaciones
aceptables; las consideraremos entre las realizaciones que no transcribimos en este
trabajo. Tampoco pertenecerían a la pronunciación estándar la realización de abuelo
como [
] no pertenecen al habla culta y cuidada. Las puede
realizar el hablante, pero son propias del habla familiar y relajada, o dialectal. Desde
la perspectiva de una variedad lingüística de prestigio, no son realizaciones
aceptables; las consideraremos entre las realizaciones que no transcribimos en este
trabajo. Tampoco pertenecerían a la pronunciación estándar la realización de abuelo
como [![]() .'
.'![]()
![]()
![]() .
.![]()
![]() ] y de agua
como [a.'wa].
] y de agua
como [a.'wa].
Consideraremos que en la pronunciación culta
cuidada, ['![]()
![]() .
.![]()
![]() ] se realiza siempre así: en posición inicial
absoluta, tras nasal, tras cualquier otra consonante o vocal. Puede producirse un mayor
cierre de los labios en los dos primeros contextos, pero en ese registro no se llega a
realizar una oclusiva o aproximante velar. También puede pronunciarse con una relajación
variable, hasta la realización de una glide, pero el comportamiento de [w] en los
procesos alofónicos es el de una consonante; su articulación es aproximante labiovelar:
los labios se acercan y se forma una cavidad de resonancia en la zona velar. En cambio, se
puede realizar ['
] se realiza siempre así: en posición inicial
absoluta, tras nasal, tras cualquier otra consonante o vocal. Puede producirse un mayor
cierre de los labios en los dos primeros contextos, pero en ese registro no se llega a
realizar una oclusiva o aproximante velar. También puede pronunciarse con una relajación
variable, hasta la realización de una glide, pero el comportamiento de [w] en los
procesos alofónicos es el de una consonante; su articulación es aproximante labiovelar:
los labios se acercan y se forma una cavidad de resonancia en la zona velar. En cambio, se
puede realizar ['![]()
![]()
![]() .
.![]()
![]()
![]() ], tras nasal y pausa, y ['
], tras nasal y pausa, y ['![]()
![]()
![]() .
.![]()
![]()
![]() ], en cualquier otro contexto; pero no ['wan.te], que
indicaría un grado de relajación no característico del habla estándar. Por tanto, las
realizaciones velares que debemos considerar para su caracterización fonemática son la
vocal [u], la glide [
], en cualquier otro contexto; pero no ['wan.te], que
indicaría un grado de relajación no característico del habla estándar. Por tanto, las
realizaciones velares que debemos considerar para su caracterización fonemática son la
vocal [u], la glide [![]() ] y la aproximante [w]. Los sonidos [g] y [
] y la aproximante [w]. Los sonidos [g] y [![]() ] constituyen
una serie diferenciada.
] constituyen
una serie diferenciada.
Para derivar el conjunto de segmentos de estas series tenemos tres opciones:
(1) Partir únicamente de dos segmentos vocálicos: /i/ y /u/. (2) Diferenciar en la representación subyacente entre los segmentos vocálicos /i/ y /u/ y las glides /(1) Vocales /i/ y /u/.
Las propuestas de Hockett (1955) y Macpherson (1975) son sumamente interesantes por la regularidad que imprimen al sistema fonológico del español: consideraríamos la existencia de dos fonemas vocálicos /i/ y /u/ que se realizarían como vocales silábicas, vocales no silábicas y consonantes, según el contexto. El trabajo de Morgan (1984), inscrito en el modelo generativista de la Fonología Léxica, adopta la misma postura, y formaliza un conjunto de reglas que dan cuenta de la variación alofónica, directamente relacionada con la estructura silábica en la que se realizan ambos fonemas. La ventaja evidente de estos enfoques es que permiten explicitar el parentesco entre los distintos sonidos vocálicos y consonánticos de las series palatal y velar; por ejemplo, las distintas realizaciones de la conjunción y, y las variantes de la flexión verbal: comieron / leyeron. Sin embargo, existe un inconveniente que no debe ser obviado: para derivar el conjunto de segmentos no sólo se necesita información contextual, también es necesario conocer la silabicidad, por ejemplo, para diferenciar entre [
(2) Vocales /i/ y /u/ - Glides /![]() / y /
/ y /![]() /.
/.
La silabicidad de los segmentos es determinante para su realización, por lo que ha de estar representada de algún modo, bien a través de un segmento glide, bien mediante mecanismos específicos que diferencien entre lo segmental, [+vocal], y lo prosódico, [±silábico]. Harris (1975, 1989a, 1989b y 1991), Hualde (1991) y Roca (1991) representan las glides en el nivel subyacente: no son predecibles, y es necesario para la correcta asignación del acento. Las variantes consonánticas derivarían de éstas a través de una regla de consonantización.
Para Harris (1991), tanto la glide prevocálica como la postvocálica forman parte de la rima:
Figura 15: Representación de las glides según Harris (1991).
|
En la representación de Hualde (1991), la glide prevocálica forma inicialmente parte de la unidad que recibe el acento, el núcleo, y allí permanece si no está en posición inicial de sílaba (prieto, rabia), pues de lo contrario, se consonantizaría, trasladándose al ataque (cf. la Figura 16, donde se ejemplifican las palabras hielo y mayo). La glide postvocálica forma parte de la rima, pero no del núcleo. Aunque Hualde no lo menciona, si está en posición final, este segmento también entraría en un proceso de consonantización y resilabación (hay un). La consonantización ha de preceder a la resilabación, dada la formulación de la regla que se ha de aplicar (cf. Harris: 1991: 61; y Hualde, 1991: 486):
Resilabación:
[+cons] |
--> |
[+cons] |
/ ____ # V |
| |
| |
||
R |
O |
Figura 16: Consonantización de la glide prevocálica (Hualde, 1991: 481).
|
Harris (1989b: 163) señala una paradoja en una formalización como la anterior: una glide no puede convertirse en consonante mientras esté en la rima y no puede trasladarse de la rima mientras sea glide. Propone que aquellas glides iniciales que no pertenecen a la rima en ningún estadio de la derivación se inserten desde el principio en el ataque. La regla de consonantización de las glides en posición inicial cambia radicalmente: en lugar de reestructurar sílabas, describiría la realización consonántica con el apropiado detalle fonético que corresponda al dialecto transcrito. Como el ataque silábico es una posición reservada inicialmente a las consonantes, Harris ha de modificar su formulación anterior (1991: 22-24. Original inglés de 1983) para que también las glides se puedan insertar en dicha posición.
Al igual que Hualde, Harris no menciona qué sucede con la glide postvocálica final de palabra ante otra que empieza en vocal. Tiene el mismo comportamiento que la prevocálica, por lo que también ha de constituirse como ataque desde el inicio de la representación.
(3) Consonantes /j/ y /w/ - Vocales [±silábicas].
La representación con glide subyacente tiene el valor de la
regularidad: permite mostrar, por ejemplo, la relación formal entre las agrupaciones /'![]()
![]() / de hielo
y cielo y /'
/ de hielo
y cielo y /'![]()
![]() / de hueso y duelo; también, la
semejanza en la desinencia verbal de comieron / leyeron, a pesar de la variación
glide-vocal con que se realizan. Son relaciones y variaciones formales relacionadas con
aspectos morfológicos del léxico. Es conveniente que en algún estadio de la derivación
las glides se sitúen en una misma posición silábica, como en la representación de
Hualde; de otro modo, se pierde una información de la que ha de dar cuenta la gramática
de la lengua española. Es lo que sucede con la propuesta de Harris, aunque tiene el
mérito de reflejar la realidad fónica: en el caso presentado esa glide siempre se
realiza como consonante en el ataque silábico.
/ de hueso y duelo; también, la
semejanza en la desinencia verbal de comieron / leyeron, a pesar de la variación
glide-vocal con que se realizan. Son relaciones y variaciones formales relacionadas con
aspectos morfológicos del léxico. Es conveniente que en algún estadio de la derivación
las glides se sitúen en una misma posición silábica, como en la representación de
Hualde; de otro modo, se pierde una información de la que ha de dar cuenta la gramática
de la lengua española. Es lo que sucede con la propuesta de Harris, aunque tiene el
mérito de reflejar la realidad fónica: en el caso presentado esa glide siempre se
realiza como consonante en el ataque silábico.
Por otro lado, debemos diferenciar los ejemplos mencionados de casos
como mayo, mayor, yeso, cayado o coyote. Así como las
variaciones ['![]()
![]() ] - ['je] y [
] - ['je] y [![]()
![]() ] - ['we] forman parte de la alomorfia de algunas
familias léxicas: [e] - ['
] - ['we] forman parte de la alomorfia de algunas
familias léxicas: [e] - ['![]()
![]() ] - ['je]: helar - hielo, celeste - cielo;
[o] - ['
] - ['je]: helar - hielo, celeste - cielo;
[o] - ['![]()
![]() ] - ['we]: óseo
- hueso, doler - duelo, palabras como mayo, mayor, yeso, cayado
o coyote no se relacionan formalmente con otras con las que se pueda establecer el
mismo paradigma de variación. Representar una glide subyacente en esas palabras no deja
de ser una convención motivada por economía del repertorio de segmentos: de las glides
se pueden derivar las correspondientes consonantes. Desde nuestro punto de vista, si
pretendemos formalizar la realidad fónica, no tiene sentido transcribir como fonema una
vocal no silábica en aquellos contextos en los que siempre se realiza una consonante.
] - ['we]: óseo
- hueso, doler - duelo, palabras como mayo, mayor, yeso, cayado
o coyote no se relacionan formalmente con otras con las que se pueda establecer el
mismo paradigma de variación. Representar una glide subyacente en esas palabras no deja
de ser una convención motivada por economía del repertorio de segmentos: de las glides
se pueden derivar las correspondientes consonantes. Desde nuestro punto de vista, si
pretendemos formalizar la realidad fónica, no tiene sentido transcribir como fonema una
vocal no silábica en aquellos contextos en los que siempre se realiza una consonante.
Los procesos alofónicos en los que concurre el sonido inicial de hielo y hueso demuestran su carácter consonántico, por ejemplo, la sonorización de la fricativa /s/ y la no resilabación: deshielo [z.j]; deshuesar [z.w].
La tendencia a la consonantización de las glides en posición inicial ha sido descrita tradicionalmente en la bibliografía del español (Navarro Tomás, 1918: 49), pero corresponde a un comportamiento general de la lenguas. En la fonología generativa, Itô (1988) ha formulado el Principio del Ataque (Onset Principle; en adelante, OP), que rige la asignación de la estructura silábica y afecta a los fenómenos de silabación y resilabación para garantizar la existencia de sílabas con abertura. Se basa en la observación de que todas las lenguas tienen sílabas con abertura y algunas sólo las tienen de ese tipo; en cambio, ninguna lengua presenta la misma exigencia para las rimas.
El OP se formula comoEvite
s[VSe considera que todas las lenguas observan este principio y cada una usa los medios de los que dispone para satisfacerlo. Se formula como "evítese" y no como "se prohíbe" porque hay lenguas que aceptan sílabas sin abertura cuando no hay ninguna consonante disponible (por ejemplo, el español, el catalán, el japonés y el inglés); en cambio, algunas no admiten sílabas que empiecen por vocal. Para Palmada (1991) el OP actúa no sólo como principio guía de la silabación, sino que ha de ser considerado como un principio activo que desencadena o bloquea la aplicación de reglas.
La realización como consonante de los sonidos iniciales de hielo y hueso puede ser explicada como un ejemplo de la actuación del OP:
En hielo y hueso, ninguna consonante ocupa el ataque. Las vocales no silábicas /i/ y /u/, asociadas al núcleo, pueden consonantizarse. El OP activaría este proceso para preservar el ataque silábico. Es un proceso obligatorio, asociado a la silabación, y se aplica en cualquier estadio: en la palabra, como demuestran las realizaciones consonánticas de deshielo y deshueso, que bloquean la reestructuración silábica, y en el decurso: hay uno [a.'ju.no], con reestructuración y consonantización.
El DEFE contiene palabras ya formadas: formas flexivas de distinta complejidad formal. Aunque en una representación morfológica puedan constar las glides (vocales no silábicas), desde nuestro concepto de fonema, en aquellos contextos en los que se consonantiza siempre, la representación de esos segmentos ha de ser como consonantes. A pesar de la paradoja presentada por Harris, debemos asumir que existe un traslado de la glide hasta el ataque silábico cuando no hay otro segmento que ocupe su lugar, con la consiguiente consonantización.
Por tanto, en estas series de segmentos palatales y velares, diferenciaremos entre fonemas vocálicos (silábicos y no silábicos) y consonánticos. Allí donde siempre se realiza una consonante (aproximante u oclusiva), transcribiremos un fonema consonántico, diferenciado de la vocal no silábica, que se realiza como glide (discuteremos los aspectos concernientes a las vocales en el apartado 5.5.2).
El representante fonémico de los sonidos [j] y [![]() ] ha de ser el
oclusivo, siendo coherentes con nuestra propuesta para /b/, /d/ y /g/. Es cierto que
existe una tendencia a la relajación por la que llega a realizarse una glide inicial en hielo
y hueso, indudablemente por influencia ortográfica (cf. Navarro Tomás, 1918: §
49), porque no ocurre así en yate; pero no consideraremos que existen dos fonemas
palatales sino que son dos realizaciones más entre la variedad descrita en la lengua
estándar y dialectal (cf. Alcina y Blecua, 1975: § 2.5.14). La influencia ortográfica
provoca una pronunciación relajada del grupo ortográfico hi, frente a una
pronunciación fuerte de y, de ahí que podamos suponer la existencia de un par
mínimo hierro /j/ - yerro /
] ha de ser el
oclusivo, siendo coherentes con nuestra propuesta para /b/, /d/ y /g/. Es cierto que
existe una tendencia a la relajación por la que llega a realizarse una glide inicial en hielo
y hueso, indudablemente por influencia ortográfica (cf. Navarro Tomás, 1918: §
49), porque no ocurre así en yate; pero no consideraremos que existen dos fonemas
palatales sino que son dos realizaciones más entre la variedad descrita en la lengua
estándar y dialectal (cf. Alcina y Blecua, 1975: § 2.5.14). La influencia ortográfica
provoca una pronunciación relajada del grupo ortográfico hi, frente a una
pronunciación fuerte de y, de ahí que podamos suponer la existencia de un par
mínimo hierro /j/ - yerro /![]() /. Sin embargo, los dobletes ortográficos,
como hiedra - yedra, también se pronunciarían del mismo modo, pero no forman un
par mínimo.
/. Sin embargo, los dobletes ortográficos,
como hiedra - yedra, también se pronunciarían del mismo modo, pero no forman un
par mínimo.
En la serie velar consideraremos que no existe variación alófonica: el fonema es /w/.
Desde nuestro punto de vista, se comete un error
metodológico al analizar conjuntamente las realizaciones velares pertenecientes a
distintos registros. Si en la pronunciación estándar diferenciamos entre las
realizaciones de [w] y [g] - [![]() ], debemos proponer dos fonemas distintos. Existen
variantes comunes en las realizaciones de ambos, pero son el resultado de la aplicación,
en dos direcciones distintas, de un proceso de refuerzo-debilitamiento.
], debemos proponer dos fonemas distintos. Existen
variantes comunes en las realizaciones de ambos, pero son el resultado de la aplicación,
en dos direcciones distintas, de un proceso de refuerzo-debilitamiento.
Realización estándar |
----> |
(debilitamiento) |
[' |
[' |
|
[' |
[' |
|
(refuerzo) |
<------------ |
Realización estándar |
Aguilar (1994) encuentra una gran variación en las
realizaciones de esta serie de sonidos, pero están en distribución complementaria: [![]()
![]() ] y [
] y [![]()
![]() ] aparecen
ante [a] y [o], mientras que [w], aparece ante [e] e [i]; la autora también propone
diferenciar entre los fonemas aproximante labiovelar y oclusivo velar, con realizaciones
alofónicas que se sitúan en ese eje.
] aparecen
ante [a] y [o], mientras que [w], aparece ante [e] e [i]; la autora también propone
diferenciar entre los fonemas aproximante labiovelar y oclusivo velar, con realizaciones
alofónicas que se sitúan en ese eje.
Las alternancias [![]()
![]() ]-[
]-[![]() ] y [
] y [![]()
![]() ]-[
]-[![]() ] del habla no estándar: abuelo [
] del habla no estándar: abuelo [![]() .'
.'![]()
![]()
![]() .
.![]()
![]() ] -
[
] -
[![]() .'
.'![]()
![]() .
.![]()
![]() ] y agua
['
] y agua
['![]() .
.![]()
![]()
![]() ] - ['
] - ['![]() .
.![]()
![]() ] han sido
explicadas convincentemente, en nuestra opinión, por Monroy Casas (1980) (cf. supra,
§ 4.3.8.2).
] han sido
explicadas convincentemente, en nuestra opinión, por Monroy Casas (1980) (cf. supra,
§ 4.3.8.2).
No podemos eludir el problema de la conjunción u. Ésta siempre se realiza como un sonido consonante labiovelar, puesto que ha de preceder obligatoriamente a una vocal [o]. Según nuestro razonamiento debería transcribirse un fonema /w/. Sin embargo, también puede ser pronunciada aisladamente, como vocal [u], lo comentamos en el apartado 5.1 con el siguiente ejemplo: La conjunción disyuntiva «u» es una variante de «o» ante palabras que empiezan por vocal «o». Consideraremos que se trata de un fonema vocálico que se realiza como consonante en su contexto habitual de aparición. En cuanto a la conjunción y, transcribiremos las realizaciones descritas por Alarcos (1965: 154), a las que ya hemos hecho referencia (cf. supra, § 4.3.7.3).
5.5. Fonemas y alófonos vocálicos. 5.5.1. Carácter fonemático de los diptongos.Alarcos (1965) y Martínez Celdrán (1989) han rebatido convincentemente el carácter monofonemático de los diptongos propuesto por Navarro Tomás (1946); queremos añadir que los argumentos presentados por este autor no demuestran que los diptongos sean fonemas:
(i) Los pares de palabras presentados como ejemplos (celo / cielo, vente / veinte, tuerca / terca / turca) sólo pueden ser considerados pares mínimos asumiendo que los diptongos constituyen unidades monofonemáticas, nunca en el caso de que los concibamos como combinaciones de dos fonemas. Ésa es la justificación que hemos aducido para diferenciar entre lo que el fonema es y lo que el fonema hace. Siguiendo el argumento de Navarro Tomás, los grupos de consonantes formados por /obstruyente/ + /líquida/ también deberían ser grupos monofonemáticos, puesto que es posible encontrar pares mínimos con esas combinaciones: brazo / bazo; prado / vado; madre / mate; traje / paje; craso / caso; gramo / gamo; plato / pato; habla / haba; clavo / cabo; globo / bobo.
(ii) Navarro Tomás describe la falta de independencia fonética de las glides en términos distribucionales: no tienen una individualidad definida porque no pueden aparecer aisladas en posición intervocálica o interconsonántica; pero esta falta de independencia no implica necesariamente que los diptongos deban ser considerados unidades monofonemáticas. Consonantes, vocales y glides poseen propiedades distribucionales distintas, puesto que forman paradigmas diferenciados que ocupan lugares distintos en la sílaba. La independencia fonética de los segmentos no puede ser formulada con el criterio de la aislabilidad: las consonantes, aunque aparezcan en posición intervocálica, tampoco pueden aparecer aisladas, comparten esa propiedad con las glides; si aparecen en esa posición es porque necesitan apoyarse en una vocal.
(iii) La relación existente entre palabras emparentadas (puerta-portero, tiene-tenía) es el resultado de un proceso histórico en la formación de la lengua: la diptongación de las vocales medio-abiertas acentuadas latinas. La fonología generativa explicaría estas formas fónicas alternantes mediante una regla de diptongación que actuaría sobre las vocales acentuadas ['e] y ['o] de las formas subyacentes al generarse la representación superficial (cf. Harris, 1975: 194-196). Desde una perspectiva diacrónica puede defenderse que estos diptongos son unidades monofonemáticas, puesto que provienen de un único fonema; también sería el caso de los diptongos de las palabras cultas con un doblete popular en el que se produjo una monoptongación: causa / cosa. Sin embargo, no podemos sostener esta postura en el estudio sincrónico de la lengua: la evolución histórica no forma parte del conocimiento que el hablante tiene de su lengua.
La propuesta de Navarro Tomás complica innecesariamente el análisis fonológico. Todos sus ejemplos se refieren a la palabra, pero no nos dice nada de los diptongos formados por el enlace entre palabras; es lógico pensar que no son fonemas sino combinaciones de dos unidades, ya que en las palabras a las que pertenecen son fonemas independientes. La fonología ha de explicar por qué los miembros de una unidad monofonemática se dividen en el decurso y justificar la existencia de diptongos monofonemáticos (los que existen en la palabra) y diptongos difonemáticos (los que se forman en el enlace entre palabras). También complica la representación de los enunciados de la lengua mediante un alfabeto de signos fonéticos: si los diptongos son unidades monofonemáticas, ha de quedar reflejado en la transcripción. Las convenciones del AFI prevén un signo de enlace "^" para simbolizar los sonidos que se realizan con una doble articulación, como los africados. Si con dicho símbolo se indica que [
En nuestro trabajo consideraremos que los diptongos son combinaciones de dos fonemas. La Regla 1º de Trubetzkoy presentada por Alarcos formaliza una intuición absolutamente coherente: una unidad fonemática no puede dividirse en el decurso:
| Palabras aisladas | Decurso | |
| si hay algún... | [ |
[' |
En este ejemplo, podemos observar que el diptongo ['![]()
![]() ] entra en un
proceso de resilabación que divide sus miembros en dos sílabas: la vocal [
] entra en un
proceso de resilabación que divide sus miembros en dos sílabas: la vocal [![]() ] se agrupa con
la sílaba precedente [
] se agrupa con
la sílaba precedente [
Debemos decidir si las glides son fonemas independientes; en tal caso, han de aparecer representados en la transcripción fonémica. Si las glides son alófonos de fonemas vocálicos o consonánticos, se derivarán mediante reglas.
La propuesta de Martínez Celdrán sobre el carácter fonemático de las glides guarda total coherencia con un modelo fonológico que posee un solo nivel de análisis, sin reglas, y en el que todo el peso de la representación descansa en los rasgos segmentales.
La distinción fonémica de las glides en el estructuralismo y en los inicios de la fonología generativa se establece a través de sus rasgos distintivos. En el sistema de rasgos de Jakobson y Halle (1956) las glides se caracterizan por ser segmentos [-vocálicos] y [-consonánticos], es decir, vocales no silábicas, variantes distribucionales de /i/ y /u/. Esta caracterización no está exenta de problemas. El comportamiento de la conjunción y del español lo ejemplifica: se puede realizar como vocal [+vocal, -consonante], como glide [-vocal, -consonante] y como consonante [-vocal, +consonante]; según los presupuestos funcionalistas, un fonema no puede ser definido mediante rasgos distintivos que contradigan los de sus variantes, de ahí que las glides no puedan ser alófonos de fonemas vocálicos o consonánticos y sea lícito plantear su independencia fonemática. El punto de partida de la argumentación de Martínez Celdrán (1989) es coherente con ese principio.
Si se quiere mantener la vinculación fonológica entre vocales y glides, se han de revisar los rasgos de Jakobson y Halle. Ya Ferguson (1962) (citado en Deligiorgis, 1988) señaló que debería establecerse una clasificación que reconozca la similitud entre glides y vocales en sus rasgos distintivos, y Shaumian (1968) (citado en Deligiorgis, 1988), que la especificación [-vocálico, -consonántico] implica que no existe relación entre ambos tipos de segmentos, a pesar de que se haya propuesto que las glides son vocales no silábicas. En sustitución del rasgo [±vocálico], Hála (1961) había propuesto el rasgo [sonante] y McCawley (1967), el rasgo [silábico]. Ambos forman parte del repertorio de rasgos distintivos propuesto por Chomsky y Halle (1968: 302-303 y 353-355): los rasgos de clase mayor [±silábico], [±consonante] y [sonante / obstruyente]30 permiten distinguir tres grandes clases de segmentos: vocales, glides y consonantes, al tiempo que se mantiene la relación entre vocales y glides:
silábico |
consonante |
sonante |
|
| vocales | + |
- |
+ |
| glides | - |
- |
+ |
| consonantes | - |
+ |
- |
El rasgo [+silábico] caracteriza a aquellos segmentos que actúan como núcleo de la sílaba (las vocales), en oposición a [-silábico], con el que se hace referencia a los segmentos que ocupan los márgenes (glides y consonantes). En la articulación de los sonidos consonánticos (oclusivas, fricativas, africadas, nasales y líquidas) se produce una constricción en el tracto vocal que no existe en los no consonánticos (vocales y glides). Los sonidos sonantes son que se realizan con una configuración articulatoria que permite la sonoridad espontánea (vocales, glides, nasales y líquidas); mientras que los obstruyentes son aquellos cuya articulación no permite dicha sonoridad (oclusivas, fricativas y africadas)31. Vocales y glides comparten los rasgos [+sonante, -consonante] y se diferencian por la especificación del rasgo [±silábico]: las vocales son [+silábicas]; las glides, [-silábicas]. Este rasgo es compartido por consonantes y glides, que se diferencian por las especificaciones de los rasgos [±sonante] y [consonante / obstruyente]: las glides son [+sonante, -consonante]; y las consonantes, [-sonante, +consonante].
Esos mismos rasgos son los que adopta Martínez Celdrán (1989: 97-98), pero aplicados desde una perspectiva funcionalista y modificando su caracterización: los rasgos [consonántico] y [sonántico] —términos que también utiliza el autor— no hacen referencia a propiedades articulatorias y acústicas de los sonidos en los que se realizan los fonemas, sino a la posición que pueden ocupar en la sílaba, al igual que el [silábico]. Como los rasgos de clase mayor atienden a la distribución de los fonemas, Martínez Celdrán ha de diferenciar cuatro clases naturales de segmentos: vocales, glides, consonantes y líquidas, dada la configuración de la sílaba en español:
silábico |
consonante |
sonante |
|
| vocales | 0 |
- |
+ |
| glides | - |
0 |
0 |
| consonantes | - |
+ |
- |
| líquidas | - |
+ |
0 |
El rasgo [consonántico] caracteriza a los segmentos que aparecen en las ramas marginales: consonantes, líquidas y glides, aunque para esta última clase no es pertinente, puesto que pueden tener variantes marginales y seminucleares; la especificación de este rasgo es negativa para las vocales porque nunca aparecen en dicha posición. El rasgo [silábico] caracteriza a los segmentos que obligatoriamente han de aparecer como núcleo de la sílaba: las consonantes, las líquidas y las glides, que nunca se sitúan en ese lugar, están especificadas negativamente; para las vocales es un rasgo redundante, por la tendencia que manifiestan a perder su silabicidad; las vocales /i/ y /u/ forman diptongos en los procesos de resilabación en el decurso (me irrita [
La propuesta de Martínez Celdrán presenta un serio inconveniente: modifica las definiciones de los rasgos de clase mayor [sonante] y [consonante], comúnmente aceptadas, para adaptarlas a la situación particular del español, con lo que invalida el carácter universal de estos elementos mínimos, concebidos para poder definir el conjunto de fonemas de todas las lenguas. No obstante, lo que se pone de manifiesto es la necesidad de diferenciar entre las propiedades articulatorias y acústicas de los segmentos fónicos, de las que darían cuenta los rasgos distintivos (en el caso que nos ocupa, [consonante] y [sonante]), y sus propiedades sintagmáticas en las constitución de la sílaba, a las que se referiría la silabicidad; son aspectos distintos de la representación fonológica, por lo que deberían ser tratados separadamente. De hecho, este tema ya ha sido abordado por la fonología en formulaciones posteriores a la de Chomsky y Halle (1968).
Existen argumentos para considerar en el análisis fonológico varios niveles o planos (cf. D'Introno et al., 1995: 348 y ss.):
(1) El propiamente segmental, que a su vez puede estar subdivido en
otros niveles o planos para representar los distintos mecanismos que intervienen en la
producción del sonido: sonoridad, modo de articulación y punto de articulación. Estas
subdivisiones permiten explicar de modo más adecuado los procesos fonológicos. Por
ejemplo, si atendemos a la descripción tradicional del español, la neutralización de
las nasales y de las laterales sólo afecta al punto de articulación; la
aproximantización de /b/, /d/ y /g/, al modo; la sonorización de /s/ y /![]() /, a la
sonoridad: los procesos se aplican sobre un subconjunto de rasgos específicos. Entre las
propuestas teóricas de las últimas décadas, la fonología autosegmental (Goldsmith,
1976) reconoce una estructura interna en los segmentos —que dejan de ser considerados
como un conjunto no ordenado de rasgos— y la existencia de dominios mayores que el
segmento en la aplicación de las reglas fonológicas32.
Los trabajos ya citados de Clements (1985), Sagey (1986) y McCarthy (1988) parten de esta
propuesta (cf. supra, §
4.1).
/, a la
sonoridad: los procesos se aplican sobre un subconjunto de rasgos específicos. Entre las
propuestas teóricas de las últimas décadas, la fonología autosegmental (Goldsmith,
1976) reconoce una estructura interna en los segmentos —que dejan de ser considerados
como un conjunto no ordenado de rasgos— y la existencia de dominios mayores que el
segmento en la aplicación de las reglas fonológicas32.
Los trabajos ya citados de Clements (1985), Sagey (1986) y McCarthy (1988) parten de esta
propuesta (cf. supra, §
4.1).
(2) El silábico, que daría cuenta de cómo los distintos segmentos se agrupan en sílabas. La sílaba, en la primera formulación generativa, no tenía una entidad propia, puesto que no posee un correlato fonético concreto. El rasgo silábico, incluido entre los rasgos segmentales, representaba la silabicidad de los elementos fónicos. Trabajos posteriores, como los de Kahn (1976) (citado en Durand, 1990: 200, y D'Introno et al., 1995: 384 y 386) y Selkirk (1982), defienden la entidad fonológica de la sílaba: es un dominio natural que permite explicar muchos contrastes fonéticos. Citando ejemplos del español, los procesos de neutralización y de asimilación sólo afectan a los segmentos situados en la distensión silábica, y las restricciones fonotácticas sobre los grupos de consonantes son distintas según se refieran al inicio o al final de sílaba. La silabicidad de los segmentos no se ha de especificar en la matriz de los rasgos distintivos sino a través de otros mecanismos, puesto que da cuenta de una propiedad sintagmática. Por ejemplo, en el Modelo CV (Clements y Keyser, 1983; y Clements, 1985) se asume que la sílaba tiene una estructura formada por tres niveles: cada segmento (representado por una matriz de rasgos distintivos) está asociado a un nudo C o V, con el que se representa la silabicidad; el conjunto de nudos C y V conforman el denominado Nivel CV ('CV tier') o 'esqueleto', que a su vez está conectado a un nivel superior, el de la sílaba. Las vocales que actúan como núcleo silábico están asociadas a un nudo V; las consonantes y las glides, a un nudo C. Así se mantiene la caracterización segmental común entre vocales y glides, al tiempo que se diferencia la distinta capacidad de constituir un núcleo silábico. Dos tipos de reglas darían cuenta de los procesos de resilabación por los que las vocales pierden su carácter silábico (V -> C) y las glides lo adquieren (C -> V)33.
Figura 17: Representación de la sílaba en el Modelo CV.
|
(3) El prosódico. Goldsmith (1976) observa que, en las lenguas tonales, los tonos son independientes de los segmentos a los que se asignan, por lo que la descripción fonológica ha de tener en cuenta un nivel en el que representar la prosodia. Debemos aclarar que la bibliografía se refiere a un nivel tonal en lugar de uno prosódico (cf. D'Introno et al., 1995: 351), siguiendo indudablemente la propuesta de Goldsmith (1976). Este nivel sólo sería válido en las lenguas donde el tono es distintivo; en cambio, un nivel prosódico también permitiría la representación del acento en las lenguas no tonales.
La estructura del fonetizador que genera el DEFE
muestra una concepción del análisis fonológico que asume la necesidad de describir los
tres niveles señalados: la representación fonológica de la palabra ha de dar cuenta de
la secuencia de segmentos, de la organización silábica y de la acentuación porque son
aspectos que forman parte de la competencia del hablante, del conocimiento sobre la
pronunciación de su lengua. Es evidente que se ha de representar la silabicidad de las
vocales, por ser una característica no predecible y porque incide en la asignación del
acento, como señalan Mel'cuk (1976), Harris (1969 y 1971), Martínez Celdrán (1989) y
Hualde (1991). Las glides han de constar como fonemas en una transcripción sin marcas de
división silábica, propia de un modelo fonológico en el que la silabicidad no tiene una
representación independiente y ha de ser incluida entre los rasgos segmentales: desviar
/desbiá![]() /
y cambiar /kamb
/
y cambiar /kamb![]() á
á![]() /. En cambio, la representación de las glides es
redundante, porque se pueden derivar mediante reglas, en una transcripción que incluya
dichas marcas, indicadoras de la silabicidad, lo que implicaría un modelo fonológico que
distingue entre las características acústicas o articulatorias de los segmentos y sus
propiedades sintagmáticas en la constitución de unidades superiores.
/. En cambio, la representación de las glides es
redundante, porque se pueden derivar mediante reglas, en una transcripción que incluya
dichas marcas, indicadoras de la silabicidad, lo que implicaría un modelo fonológico que
distingue entre las características acústicas o articulatorias de los segmentos y sus
propiedades sintagmáticas en la constitución de unidades superiores.
Partiendo del concepto de fonema que hemos
establecido, las glides han de ser consideradas alófonos de las vocales /i/ y /u/: son
variantes combinatorias que dependen de su caracterización como [+silábicas] o
[-silábicas]. Esta información puede ser deducida del contexto: los principios de
organización de la sílaba en el español nos dicen que son glides las vocales /i/ y /u/
adyacentes a cualquier otra vocal o combinadas entre sí (en cualquier posición) cuando
entre ellas no existe una marca de división silábica. Si atendemos a este principio,
podemos diferenciar en la representación fonémica, por ejemplo, entre desviar
/des.bi.á![]() /
y cambiar /kam.biá
/
y cambiar /kam.biá![]() /. En desviar, el límite silábico entre /i/ y
/a/ indica que el primer segmento es silábico; en cambio, la ausencia de límite en cambiar
indica que /i/ es un segmento no silábico. Las vocales /a/, /e/ y /o/ siempre son
silábicas, y consideraremos que en la lengua estándar no se producen fenómenos de
sinéresis por los que pierdan su silabicidad; por supuesto, en español las consonantes
siempre son no silábicas. Las reglas acentuales han de tener en cuenta la
caracterización segmental y la silabicidad de los segmentos, de modo que el acento sólo
pueda ser asignado a las vocales silábicas.
/. En desviar, el límite silábico entre /i/ y
/a/ indica que el primer segmento es silábico; en cambio, la ausencia de límite en cambiar
indica que /i/ es un segmento no silábico. Las vocales /a/, /e/ y /o/ siempre son
silábicas, y consideraremos que en la lengua estándar no se producen fenómenos de
sinéresis por los que pierdan su silabicidad; por supuesto, en español las consonantes
siempre son no silábicas. Las reglas acentuales han de tener en cuenta la
caracterización segmental y la silabicidad de los segmentos, de modo que el acento sólo
pueda ser asignado a las vocales silábicas.
Hemos definido las glides como alófonos de fonemas
vocálicos, y debemos justificar esta afirmación recurriendo a la realidad fónica. Las
características articulatorias y acústicas de estos segmentos indican que no son
consonantes: se articulan sin constricción en el tracto vocal y poseen una estructura
formántica definida (cf. Aguilar, 1994). Los casos de consonantización en leyendo
/le.'jen.do/ y hay acelgas /'a.ja.'![]() el.gas/ —frente a comiendo
/ko.'m
el.gas/ —frente a comiendo
/ko.'m![]() en.do/
y hay patatas /'a
en.do/
y hay patatas /'a![]() .pa.'ta.tas/— han de ser explicados mediante la
aplicación de un proceso alofónico motivado por causas morfológicas y sintácticas; los
consideraremos como realizaciones de /i/ marcadas por el contexto: inicial de sílaba.
Nuestra principal objeción a las propuestas de Bowen y Stockwell (1955) y Hara (1973) es
que anteponen otras consideraciones a la formalización de las realizaciones fonéticas
que, desde nuestro punto de vista, ha de acometer la fonología, independientemente del
enfoque teórico en que se sustente.
.pa.'ta.tas/— han de ser explicados mediante la
aplicación de un proceso alofónico motivado por causas morfológicas y sintácticas; los
consideraremos como realizaciones de /i/ marcadas por el contexto: inicial de sílaba.
Nuestra principal objeción a las propuestas de Bowen y Stockwell (1955) y Hara (1973) es
que anteponen otras consideraciones a la formalización de las realizaciones fonéticas
que, desde nuestro punto de vista, ha de acometer la fonología, independientemente del
enfoque teórico en que se sustente.
Si aceptamos que las glides son alófonos de fonemas consonánticos, debemos contar con una regla de vocalización para la realización glide en comiendo (un ejemplo de Bowen y Stockwell, 1955) y otra de consonantización para hay acelgas; sin embargo ambos casos son la manifestación del mismo fenómeno. Tampoco debe identificarse [no silábico] con [consonante] y [silábico] con [vocal], como hace Hara (1973). Esta propuesta puede ser válida en la representación fonológica de la palabra, pero no explica los casos en que una vocal /i/ o /u/ pierde su silabicidad en el decurso. Se ha de diferenciar entre la caracterización segmental y la silábica. Desde una perspectiva universalista, la silabicidad es independiente del carácter vocálico o consonántico del segmento. Cada lengua tendrá sus propias restricciones en la combinación de ambas propiedades. Existen lenguas con consonantes silábicas (por ejemplo, el inglés), a diferencia de lo que ocurre en español. En nuestra lengua, las vocales /i/ y /u/ pueden ser silábicas y no silábicas, pueden perder su silabicidad y pueden consonantizarse. La separación entre lo propiamente segmental y lo silábico describe de modo más adecuado los procesos alofónicos en los que intervienen estos segmentos.
Finalmente, las razones fonotácticas a las que alude Martínez Celdrán para demostrar que las glides no son alófonos de fonemas consonánticos pueden ser discutidas: si se demuestra que las glides son la realización de una consonante, se han de admitir las estructuras silábicas que rechaza para el español: /s/ inicial + /consonante/ y /r/ inicial + /consonante/, y los grupos consonánticos finales; se puede explicar como un caso de distribución defectiva el hecho de que la única consonante que aparece en esos contextos sea una glide. La misma crítica se ha de extender al contraargumento fonotáctico que presenta Saporta (1956) a la propuesta de Bowen y Stockwell (1955): los tres esquemas silábicos presentados (/consonante/ + /líquida/, /consonante/ + /glide/, /consonante/ + /líquida/ + /glide/) formarán parte de la lengua española si se demuestra que la glide es un alófono de un fonema consonántico, aunque muestren irregularidades en el sistema. Consideramos que las estructuras silábicas de una lengua se han de definir a partir de la caracterización de los segmentos que las integran; no se puede determinar el carácter fonemático de un segmento atendiendo a estructuras silábicas prefijadas.
5.5.3. Diptongos crecientes y decrecientes. Hemos considerado que los diptongos son
combinaciones bifonemáticas. El repertorio tradicional de diptongos del español se ha
establecido a partir de la clasificación de Navarro Tomás (1918: § 66), para quien
existen ocho diptongos crecientes: [![]() a], [
a], [![]() e], [
e], [![]() o], [
o], [![]() u], [
u], [![]() a], [
a], [![]() e], [
e], [![]() i], [
i], [![]() o]; y seis decrecientes: [a
o]; y seis decrecientes: [a![]() ], [a
], [a![]() ], [e
], [e![]() ], [e
], [e![]() ], [o
], [o![]() ], [o
], [o![]() ]. La asimetría se produce por
el comportamiento de las vocales altas agrupadas: "En los grupos iu, ui
predomina siempre como principal elemento del diptongo la segunda vocal, reduciéndose la
primera a semiconsonante". Sobre el grupo [
]. La asimetría se produce por
el comportamiento de las vocales altas agrupadas: "En los grupos iu, ui
predomina siempre como principal elemento del diptongo la segunda vocal, reduciéndose la
primera a semiconsonante". Sobre el grupo [![]() i], indica el autor (p. 65, n. 1) que en
algunas partes de España se pronuncia cuida ['ku
i], indica el autor (p. 65, n. 1) que en
algunas partes de España se pronuncia cuida ['ku![]() .
.![]() a], cuidado [ku
a], cuidado [ku![]() .'
.'![]() a.
a.![]() o], cuita
['ku
o], cuita
['ku![]() .ta],
muy ['mu
.ta],
muy ['mu![]() ], con preponderancia de la [u]; pero en resto del
país la pronunciación da preponderancia a la [i]: cuida ['k
], con preponderancia de la [u]; pero en resto del
país la pronunciación da preponderancia a la [i]: cuida ['k![]() i.
i.![]() a], cuidado
[k
a], cuidado
[k![]() i.'
i.'![]() a.
a.![]() o], cuita
['ku
o], cuita
['ku![]() i.ta],
muy ['m
i.ta],
muy ['m![]() i].
i].
Otras obras que siguen esa
tradición son, por ejemplo, las de Fernández Ramírez (1986: § 23), Alcina y Blecua
(1975: 414-415) y Alarcos (1965: 150-151), aunque el último (p. 157) también menciona la
alternancia, incluso en un mismo hablante, de los diptongos tónicos [![]() í] / [ú
í] / [ú![]() ] y [
] y [![]() ú] / [í
ú] / [í![]() ]: cuida
['k
]: cuida
['k![]() i.
i.![]() a] / ['ku
a] / ['ku![]() .
.![]() a], ruido
['r
a], ruido
['r![]() i.
i.![]() o] / ['ru
o] / ['ru![]() .
.![]() o], viuda
['b
o], viuda
['b![]() u.
u.![]() a] / ['bi
a] / ['bi![]() .
.![]() a], muy mal
['m
a], muy mal
['m![]() i.'mal]
/ ['mu
i.'mal]
/ ['mu![]() .'mal];
además, cuando están en sílaba átona no siempre es posible decidir cuál de los dos
elementos es el silábico, dada la brevedad y poca energía de la realización: se suelen
articular vocales centralizadas y más o menos deslabializadas. Fernández Ramírez (1986:
§ 23) cree que el predominio de los diptongos crecientes en español explica la tendencia
a fijar el acento en el segundo elemento de los grupos [
.'mal];
además, cuando están en sílaba átona no siempre es posible decidir cuál de los dos
elementos es el silábico, dada la brevedad y poca energía de la realización: se suelen
articular vocales centralizadas y más o menos deslabializadas. Fernández Ramírez (1986:
§ 23) cree que el predominio de los diptongos crecientes en español explica la tendencia
a fijar el acento en el segundo elemento de los grupos [![]() u] y [
u] y [![]() i] tónicos,
aunque haya razones etimológicas que la contradigan: así, el acento, etimológico, de la
palabra viuda (lat. vi-du-am) recaía sobre la [i]
i] tónicos,
aunque haya razones etimológicas que la contradigan: así, el acento, etimológico, de la
palabra viuda (lat. vi-du-am) recaía sobre la [i]
Quilis (1993: § 5.9.1) describe
las realizaciones como diptongos crecientes o decrecientes de los grupos formados por /i/
+ /u/ y /u/ + /i/ en términos semejantes a Alarcos: por ser ambas vocales altas, con el
mismo grado de abertura, constituirá núcleo silábico la que posea mayor intensidad,
aunque la diferencia sea mínima: viuda ['b![]() u.
u.![]() a] / ['bi
a] / ['bi![]() .
.![]() a], fui ['f
a], fui ['f![]() i] / ['fu
i] / ['fu![]() ]; la
elección del segmento que actúa como núcleo depende del hablante, de la situación o
del dialecto. Canellada y Madsen (1987: 50) difieren de la posición tradicional: en la
lengua estándar culta, no existe el diptongo decreciente [i
]; la
elección del segmento que actúa como núcleo depende del hablante, de la situación o
del dialecto. Canellada y Madsen (1987: 50) difieren de la posición tradicional: en la
lengua estándar culta, no existe el diptongo decreciente [i![]() ], pero sí el creciente [u9i],
aunque no abunden los ejemplos: "la tan discutida palabra 'muy' se pronuncia [múi],
lo cual se prueba en la pronunciación enfática 'muy bien, pero que MUY bien' [mú:i
ßién] y no [muí: ßién]".
], pero sí el creciente [u9i],
aunque no abunden los ejemplos: "la tan discutida palabra 'muy' se pronuncia [múi],
lo cual se prueba en la pronunciación enfática 'muy bien, pero que MUY bien' [mú:i
ßién] y no [muí: ßién]".
Aguilar (1994) encuentra una gran variación en las realizaciones de sus informantes, pero la tendencia general es que los grupos átonos formados por /i/ + /u/ y /u/ + /i/ formen diptongos crecientes, en los que la primera vocal actúa como elemento de transición entre la consonante que precede al grupo y la segunda vocal, el núcleo.
En este trabajo consideraremos
que en los diptongos átonos formados por dos vocales altas son crecientes: /![]() u/, /
u/, /![]() i/; la glide
palatal o velar sería el elemento de transición entre el máximo cierre de la consonante
en ataque y la máxima abertura de la vocal núcleo. En cuanto a los diptongos tónicos
formados por esas mismas vocales, la tendencia general de la lengua es a que recaiga el
acento en la segunda vocal; serían crecientes (piure, cuídalo). No existen
ejemplos del diptongo decreciente tónico /í
i/; la glide
palatal o velar sería el elemento de transición entre el máximo cierre de la consonante
en ataque y la máxima abertura de la vocal núcleo. En cuanto a los diptongos tónicos
formados por esas mismas vocales, la tendencia general de la lengua es a que recaiga el
acento en la segunda vocal; serían crecientes (piure, cuídalo). No existen
ejemplos del diptongo decreciente tónico /í![]() /; pero, desde nuestra competencia la
pronunciación de muy es /mú
/; pero, desde nuestra competencia la
pronunciación de muy es /mú![]() /, como indican Canellada y Madsen. Es cierto que en
el habla puede haber alternancia entre /mú
/, como indican Canellada y Madsen. Es cierto que en
el habla puede haber alternancia entre /mú![]() / y /m
/ y /m![]() í/, incluso desacentuación
(por ejemplo, entre dos sílabas tónicas: son muy altos ['som.m
í/, incluso desacentuación
(por ejemplo, entre dos sílabas tónicas: son muy altos ['som.m![]() i.'a
i.'a![]() .tos]),
pero la forma que consideramos estándar es la antes indicada.
.tos]),
pero la forma que consideramos estándar es la antes indicada.
Navarro Tomás (1918: 44-45) señala la tendencia al debilitamiento de las vocales inacentuadas, aunque reconoce la dificultad para determinar el grado de relajación y las circunstancias en que se produce el fenómeno. El timbre de las vocales inacentuadas depende del esmero o del descuido con que se hable y del grado relativo de fuerza espiratoria con que se produzca el sonido: en la pronunciación lenta o enfática se mantiene un timbre claro y diferenciado para cada vocal, mientras que en el lenguaje rápido y familiar, se relaja la articulación y el timbre vocálico es menos definido y preciso. También influye en la relajación la mayor o menor altura de la voz; la favorece el tono grave. En general, la vocal átona y grave situada al final de grupo fónico ante pausa es relajada; también, la vocal penúltima de las palabras esdrújulas, con un grado de debilitamiento mayor al que se produce en la vocal final de esas mismas palabras y de las llanas. Otro factor de debilitamiento es la estructura rítmica del conjunto. No obstante, la relajación de las vocales inacentuadas del español no llega al grado de las vocales relajadas del inglés, de la e muda francesa y la e final de alemán.
Otros autores no reconocen la existencia de alófonos relajados en el sistema vocálico del español. Por ejemplo, Quilis (1993: 150-151) limita el contexto en que se realizan a la posición final de grupo fónico ante pausa, pero incluso allí suelen conservar su timbre. Los análisis experimentales de Monroy Casas (1980: 54-55) indican que las vocales átonas y tónicas poseen una estructura espectral casi idéntica: las vocales átonas en posición interna aparecen perfectamente señaladas en términos acústicos y se identifican con las realizaciones que presentan bajo acento primario; sólo las vocales inacentuadas finales de grupo fónico, muestran una centralización y una relajación originada por la pérdida de intensidad de la corriente de aire exhalado.
Por tanto, si bien es cierto que el carácter átono de la vocal influye en la relajación, la variedad de factores descritos y la ausencia de una clara sistematicidad nos hace considerar el fenómeno como un caso de variación libre, dependiente de las particularidades del hablante y de la situación comunicativa, y no del contexto fónico. En la representación fonética del DEFE señalaremos la diferencia entre vocales átonas y tónicas (marcadas éstas por el acento), y no transcribiremos los alófonos relajados —uno para cada fonema— que describe Navarro Tomás (1918: §§ 47, 53, 57, 60 y 63).
5.5.5. Vocales abiertas y cerradas.Navarro Tomás (1918: §§ 45, 46, 51, 52, 55, 56, 58, 59, 61 y 62) también describió distintos grados de abertura en las realizaciones de los cinco fonemas vocálicos, que configurarían un conjunto de alófonos abiertos y cerrados en distribución complementaria. Sin embargo, estudios posteriores cuestionan la existencia de tales variantes.
Monroy Casas (1980: cap. 3) no registra en sus trabajos experimentales los alófonos descritos por Navarro Tomás; señala la enorme amplitud de márgenes que la realización de cada fonema vocálico despliega en cada individuo, pero establecer distintas variantes alofónicas supone algo más que la mera variación fonética individual. Quilis (1993: 145) indica que en español se producen realizaciones más o menos abiertas de las vocales, pero el número de esas realizaciones para cada fonema es más bien reducido, con grados de abertura o cierre no muy grandes; además, en condiciones normales, las distintas variantes no se producen en distribución complementaria. También Martínez Celdrán (1984: 288 y ss.) menciona que, para los fonemas /e/ y /o/, los contextos de aparición de los alófonos abiertos y cerrados no son tan sistemáticos como había descrito Navarro Tomás34.
En el DEFE no transcribiremos los alófonos abiertos o cerrados de los fonemas vocálicos. Teniendo en cuenta la crítica de los autores citados, la falta de sistematicidad nos hace concebir las variaciones en la abertura de las vocales como un fenómeno no dependiente del contexto, al igual que sucede con la relajación. Por otro lado, consideramos que en el habla culta dichas variaciones se han de realizar dentro de un área articulatoria que no sobrepasará el límite permitido para cada vocal (por ejemplo, la máxima abertura de la vocal /i/ no sobrepasará el límite articulatorio de /e/); no sucede lo mismo en algunas hablas dialectales, según la descripción de Alcina y Blecua (1975: 282-289, n. 60-69).
5.5.6. Vocales orales y nasales.Otro fenómeno descrito por Navarro Tomás (1918: § 38) que afecta a las vocales es la nasalización en contacto con consonante nasal, aunque no tenga en español la importancia que en francés y portugués. Una vocal entre dos consonantes nasales resulta, en general, completamente nasalizada (nunca, monte); también es frecuente la nasalización de la vocal en posición inicial absoluta seguida de nasal (infeliz, ánfora); a veces, la consonante final de sílaba nasaliza la vocal precedente (donde). Quilis (1993: 145 y 166) clasifica cinco alófonos vocálicos orales y cinco nasales en distribución complementaria; las variantes nasales, según Quilis, se realizarían en los dos primeros contextos citados por Navarro Tomás. En el DEFE tampoco transcribiremos esta variación alofónica, para lo que seguimos la diferencia que establece Monroy Casas (1980: 54) entre 'alófono extrínseco' y 'alófono intrínseco'. El primero exige el conocimiento de la lengua y es la manifestación de un fenómeno generalizado, por ejemplo, los alófonos oclusivos y aproximantes de las consonantes sonoras /b/, /d/ y /g/. Dichas condiciones no se dan en el alófono intrínseco; como ejemplo cita el autor la nasalización de las vocales ante nasal, un fenómeno que se produce en todas las lenguas.
5.6. Repertorio de fonemas en la transcripción del DEFE.Tabla 47: Fonemas vocálicos.
anterior |
central |
posterior |
|
cerrada |
i |
u |
|
media |
e |
o |
|
abierta |
a |
Tabla 48: Fonemas consonáticos.
Bilabial |
Labiodental |
Interdental |
Dental |
Alveolar |
Palatal |
Velar |
||||||||
sor. |
son. | sor. |
son. | sor. |
son. | sor. |
son. | sor. |
son. | sor. |
son. | sor. |
son. | |
| Oclusiva | p |
b |
|
|
t |
d |
|
|
k |
g | ||||
| Nasal |
|
m |
|
|
|
|
n |
|
|
|||||
Vibrante simple |
|
|
|
|
|
|
|
|||||||
| Vibrante múltiple |
|
|
|
|
|
r |
|
|
||||||
| Fricativa |
|
f |
|
|
s |
|
x |
|||||||
| Lateral |
|
|
|
|
|
l |
|
|
||||||
| Además:
w Aproximante
labiovelar
|
NOTAS
1. Daniel Jones distingue entre "sonido concreto", definido como indicamos arriba, y "sonido abstracto", al que no define (cf. Jones, 1950: 7, n. 12), aunque se refiere a él en los siguientes términos: "An abstract sound may be said to be that which is common to, or can be abstracted from, a number of utterances of what we call the same sound". Luis J. Prieto en su prólogo a la edición española de Principios de fonología, de Trubetzkoy, interpreta dicho concepto (p. XVIII): "[...] nos parece posible decir sin traicionar su pensamiento, que el sonido abstracto de Jones es el sonido concreto del empirismo -es decir, el sonido tal como aparece cuando se lo reconoce como miembro del producto lógico de todas las clases a las que pertenece con las que el sujeto es capaz de operar- una vez que se ha hecho abstracción en él de las particularidades que dependen de la manera de pronunciar del locutor".
2. También Recasens (1993: § 4.4) distingue entre las posiciones no marcada y marcada por el contexto para establecer los fonemas del catalán y sus correspondientes alófonos.
3. Nótese que los términos 'representación fonológica' y 'representación fonémica' son usados como sinónimos.
4. Cuando nos referimos a "propiedad idiosincrásica", no queremos decir que sea "exclusiva" de una unidad léxica sino que no se aplica en todo el léxico; por ejemplo, la diptongación de /'e/ en /'
/ no es general en todas las palabras del español, sólo en el conjunto de palabras que comparten esa propiedad. Toda propiedad idiosincrásica es, evidentemente, impredecible.
5. Entre los modelos de la fonología generativa, la Fonología Léxica estudia la interacción entre la morfología y la fonología (cf. Mohanan, 1986). El lexicón, como componente central de la gramática, contiene no sólo las propiedades idiosincrásicas de las palabras y de los morfemas (como en la formulación inicial de Chomsky y Halle, 1968), sino también la información sobre los procesos regulares de formación de palabras, sobre la morfología flexiva y las reglas fonológicas asociadas a dichos procesos y a la flexión. El lexicón se organiza en niveles –o 'estratos'– y las reglas morfológicas y fonológicas se aplican cíclicamente en ellos, de modo que la salida de una regla morfológica del nivel 1 es la entrada de una regla fonológica de ese mismo nivel, y la salida de ésta, la entrada de una regla morfológica del nivel 2, cuya salida es, a su vez, la entrada de una regla fonológica de ese otro nivel; y así, sucesivamente. La salida final constituye la representación fonológica de la palabra, que se inserta en las estructuras sintácticas y sobre la que se aplican las reglas fonológicas que dan cuenta de los fenómenos no ligados a la morfología. Existen, por tanto, dos tipos de reglas fonológicas: las léxicas, asociadas a la formación de palabras, y las postléxicas, que se aplican en la sintaxis. Las primeras tienen acceso a la estructura interna de las palabras, preservan su estructura, no actúan a través de la frontera entre palabras, se aplican cíclicamente y tienen excepciones; las reglas postléxicas no poseen ninguna de esas propiedades. Las reglas que se pueden aplicar tanto en el interior de palabra como a través de la frontera entre palabras son postléxicas.
No entraremos en una discusión detallada del modelo de la Fonología Léxica generativista en la medida en que no nos centramos en los procesos fonológicos ligados a la complejidad formal de la palabra: transcribimos un diccionario de palabras ya formadas; pero, generalizando, las reglas que hemos denominado 'condicionadas morfológicamente' serían reglas léxicas, y las reglas no condicionadas morfológicamente, reglas postléxicas.
6. Señalan Canellada y Madsen (1987: 43) que la juntura funciona en una lengua como el inglés, puesto que se puede obtener un cambio de significado moviendo la frontera silábica (night rate / nitrate), pero no en español estándar. No obstante, hay indicios de este fenómeno en algunos dialectos, como indica Malmberg (1967), especialmente en aquellos en los que se aspira la /s/ final o se velariza la /n/ final:
las alas: [lah.'a.lah] / las salas: [la.'sa.lah]; en ojo: [e
.'o.xo] / enojo: [e.'no.xo].
En Alcina y Blecua (1975: 437, n. 186) puede encontrarse una bibliografía sobre la juntura en español.
7. La fonología generativa ha desarrollado el concepto de la subespecificación, por el que determinados rasgos de los segmentos no estarían especificados en la representación subyacente (en este caso, el rasgo [±continuo], que afectaría a su clasificación como oclusivos o aproximantes). La especificación completa del segmento se realizaría en la representación superficial, mediante la asimilación a los rasgos del segmento precedente. D'Introno et al. (1995: 383-384) exponen esta hipótesis para el tratamiento del problema que nos ocupa, pero reconocen su limitación para explicar que tras [l] la dental se realiza como oclusiva, mientras que la bilabial y la velar se realizan como aproximantes. La teoría de la subespecificación es incompatible con el concepto de fonema del que hemos partido: los segmentos de la representación fonémica del DEFE han de estar especificados en las características fonéticas que empleamos para definirlos.
8. Menéndez Pidal se inscribe en la tradición de considerar como fricativos los sonidos aproximantes [
], [
] (cf. supra, § 4.3.3, n. 16).
9. Estamos refiriéndonos a un concepto de tensión que no corresponde exactamente al del rasgo distintivo [tenso / laxo], perteneciente a los repertorios estructuralista (Jakobson y Halle, 1956) y generativista (Chomsky y Halle, 1969). Su definición articulatoria, semejante en ambas propuestas, hace referencia a cómo la musculatura supraglotal realiza un determinado sonido. Según Jakobson y Halle (1963) (citado en Quilis, 1993: 116), en la producción de los segmentos laxos el aparato fonador se comporta del mismo modo que en la producción de los correspondientes tensos, pero con una atenuación notable, la cual se manifiesta en una presión de aire más baja en la cavidad (con un cierre total de la glotis), en una deformación más leve del aparato fonador respecto a la posición de reposo y en un relajamiento más rápido de la constricción. El rasgo [tenso / laxo] es independiente del [sordo / sonoro], y existen lenguas en las que ambos tienen una función distintiva (por ejemplo, en francés, inglés y alemán). La validez fonológica del rasgo [tenso / laxo] ha sido cuestionada. Indican Halle y Clements (1983:7) (citado en Katamba, 1989: 48) que las vocales tensas se articulan con una configuración de la masa de la lengua, o de la raíz de la lengua, que requiere una mayor constricción que en las correspondientes laxas; suele ir acompañado de una mayor duración (en inglés, las vocales largas y diptongos son tensos y las vocales breves, laxas). No se conoce ninguna lengua en la que este rasgo y [Raíz de la lengua avanzada] concurran con valor distintivo, por lo que pueden ser variantes de una misma categoría de rasgos. También se discute la validez de los términos fonéticos en que se ha formulado; lo resume Gil (1988: 85-86): «la llamada "posición neutra" es una cuestión controvertida; autores, como Lass (1976) y Catford (1977) consideran que no es universal; además, no se ha medido con exactitud el esfuerzo muscular mayor que requieren las vocales tensas, ¿dónde se sitúa el límite?, cuál es la mínima cantidad de esfuerzo muscular que permite catalogar un sonido como tenso?».
10. Si atendemos al conjunto de realizaciones que describe Navarro Tomás (1918), el proceso gradual ha de constar de los siguientes pasos:
oclusiva sorda > oclusiva sonora > aproximante > vocal > elisión
En nuestro trabajo sólo consideraremos los tres primeros, puesto que las últimas partes del proceso, la vocalización (por la que se pierde la constricción consonántica) y la elisión (como manifestación máxima del debilitamiento), no forman parte de la pronunciación estándar, sino que están relacionadas con el habla dialectal o no culta. Nos referimos a las elisiones que dependen de la elección del hablante, no a las determinadas por el contexto fónico, como es el caso, por ejemplo, de las oclusivas sordas homorgánicas en contacto, que trataremos en este capítulo.
11. Caracterizamos los procesos fonológicos en términos articulatorios para ser coherentes con nuestras definiciones de fonemas y alófonos.
12. Recordamos que estos autores tampoco mencionan alófonos aproximantes sino fricativos. Nosotros preferimos referirnos a ellos como aproximantes porque esa es su realización (cf. supra, § 4.3.3, n. 16).
13. En el repertorio de rasgos distintivos de Chomsky y Halle (1968), el par [±continuo] corresponde esencialmente a lo que hemos denominado "cierre articulatorio": los segmentos [+continuos] se caracterizan porque se realizan con una constricción que no es suficientemente estrecha para bloquear la salida del aire; mientras que en los [-continuos] hay constricción. La clasificación de las consonantes líquidas también es controvertida (cf. Durand, 1990: 52 y D'Introno et al., 1995: 332-333, n. 11 y 12). Nosotros consideramos que las laterales se realizan con un cierre articulatorio, aunque la salida del aire no se produzca por el lugar de la constricción; también hay cierre en la articulación de las vibrantes.
14. Aunque Navarro Tomás denomine a /
15. Navarro Tomás también cita casos de elisión de la oclusiva en estos contextos. Algunos pertenecen al habla vulgar (la velar del grupo ortográfico ct: ator, que puede experimentar otras modificaciones: caráiter, aspeuto, aztor, fastor), pero también se produce en el habla correcta, en algunas palabras de uso corriente: la [p] de septiembre, suscriptor, séptimo y en el grupo ortográfico pc: suscripción, transcripción; y la bilabial en obscuro, subscribir, substraer, substancia, substituir (ejemplos en los que la Academia ya ha ajustado la ortografía a la pronunciación suprimiendo la b, aunque mantenga las variantes cultas). En el DEFE no transcribiremos estas elisiones; en el caso de dobletes ortográficos (también los tienen septiembre, suscriptor y séptimo), reflejaremos una interpretación fónica regular de la ortografía para ambas formas.
16. Desde una interpretación fónica regular de la ortografía, consideraremos que en extranjerismos como kappa, tutti frutti, hobby, dossier, affaire, con consonantes (ortográficas) dobles, existe un grupo fonológico subyacente de consonantes geminadas. El sistema de transcripción fonética automática que genera el DEFE ha de realizar la misma interpretación fónica que realizaría el hablante, y creemos que cualquier hablante de español consideraría que en los ejemplos citados existen dos pes (dos oclusivas bilabiales sordas), dos tes (dos oclusivas dentales sordas), dos bes (dos oclusivas bilabiales sonoras), dos eses (dos fricativas alveolares sordas) y dos efes (dos fricativas labiodentales sordas), puesto que esas consonantes dobles no constituyen un dígrafo con un único valor fónico (como ll y rr). En este trabajo resolveremos cuál ha de ser la pronunciación de esos grupos consonánticos y si deben ser representados o no en la transcripción fonémica.
17. Navarro Tomás (1918: 100) menciona literalmente "ante fricativa sorda"; sin embargo, incluye el ejemplo de adquirir, de ahí que hayamos indicado "ante consonante sorda".
18. En la adaptación ortográfica del anglicismo slip, no registrado en el DRAE, seguimos las indicaciones de Seco (1986: 346).
19. Existe la palabra hámster, pero es un ejemplo de grupo final tautosilábico, /ms/. En posición final absoluta este grupo puede aparecer en algunos plurales, por ejemplo, módems y tótems. La pronunciación ha de ser [ms].
20. Asumiremos que la forma fonológica de este prefijo es /in-/, puesto que las variantes que tradicionalmente se le asignan, [i-] (ante líquida) e [im-] (ante bilabial), están marcadas por el contexto fónico siguiente (cf. Seco, 1986: 229); en la resilabación ante vocal, se realiza [in-]: inadaptado [i.na.
21. La gramática léxica no reconoce la morfología como un componente gramatical independiente. Para esta escuela lingüística, las palabras se crean en la sintaxis, a través de un proceso de transformación que gramaticaliza los significados léxicos; por ejemplo: "que se puede creer" --> creíble, "no creíble" = increíble, "que se puede comparar" = comparable, "no comparable" = incomparable, "golpe de puerta" = portazo, "golpe de balón" = balonazo. Sin embargo, la sintaxis no explica la forma de las palabras complejas: la variación formal /'a.ble/ - /'i.ble/ está motivada por la distinta vocal de temática del verbo al que se adjunta el sufijo /ble/, y la alternacia /o/ - /'
e/ de portazo y puerta es un caso de alomorfia en la raíz léxica dependiente de la distinta posición del acento. Es preciso, por lo tanto, considerar la existencia de una morfología que explique los aspectos formales de las palabras complejas, así como de las variaciones que se den en la flexión. Las transformaciones sintácticas crean las palabras complejas, pero la morfología explica la forma que éstas adquieren. No entraremos en un análisis detallado del tema en la medida en que no es esencial en nuestro trabajo y merece, por su complejidad, un estudio exhaustivo; asumiremos que las palabras complejas tienen una forma interna (siguiendo las clasificaciones de la gramática tradicional, serán palabras derivadas o compuestas) y trataremos aquellos aspectos fonológicos que necesitemos para llevar a cabo la transcripción del DEFE.
22. Consideraremos que los sufijos tienen información sobre el acento de las palabras derivadas de las que forman parte. Por ejemplo, en todas las palabras formadas con /'a.
23. Realizamos una segmentación secuencial porque lo que nos interesa analizar en nuestro trabajo es la concatenación de fonemas en la palabra, pero no negamos que ésta tenga una estructura, como se observa conforme aumenta su complejidad: creíble, increíble, increíblemente.
24. Las combinaciones /l/ - /l/ y /l/ - /
/ en el interior de palabra no son posibles en castellano: no existen eles geminadas (l.l) y la representación ortográfica lll resultaría extraña.
25. Para la lateral /l/ los ejemplos que constan en la tabla son las dos únicas palabras que hemos documentado con esta combinación.
26. Morfológicamente, israelí e israelita son derivados de Israel, pero estamos registrando formas complejas en las que un componente empieza por vibrante múltiple, lo que no es el caso de estas palabras. Los tres ejemplos que constan en la tabla son las únicas formas simples (en el sentido que usamos aquí) con /s/ - /r/.
27. El mismo Harris (1991: 103, n. 20) menciona la reticencia de algunos autores a las pruebas que implican llenar huecos, por ejemplo, Chomsky y Halle (1968: 191 y ss.); pero defiende su posición respecto a la vibrante geminada alegando que no es necesario postular un nuevo segmento subyacente ni nuevas reglas.
28. Ya comentamos el experimento de estos autores en el apartado 5.2 de este trabajo.
29. Según Navarro Tomás, en contacto con una interdental siguiente la [s] es atraída hacia los bordes, un poco más que ante la consonante [t], llegando a ser en parte absorbida por la fricación de dicha [
30. La palabra inglesa sonorant ha sido traducida al español como sonorante (p. ej., en Canellada y Madsen, 1987, y D'Introno et al., 1995) y sonante (p. ej. en Martínez Celdrán, 1989); nosotros adoptamos este último término, que también consta en la traducción española de Chomsky y Halle (1968).
31. En el cuadro anterior hemos especificado todas las consonantes como [-sonante], para simplificar la exposición; sin embargo, como hemos señalado, se establece una distinción entre nasales y líquidas [+sonante] y el resto de segmentos de esa clase.
32. La representación autosegmental, a diferencia de la representación fonémica tradicional y generativa clásica, consiste en dos o más niveles paralelos de segmentos, que se conectan mediante líneas de asociación. La representación fo