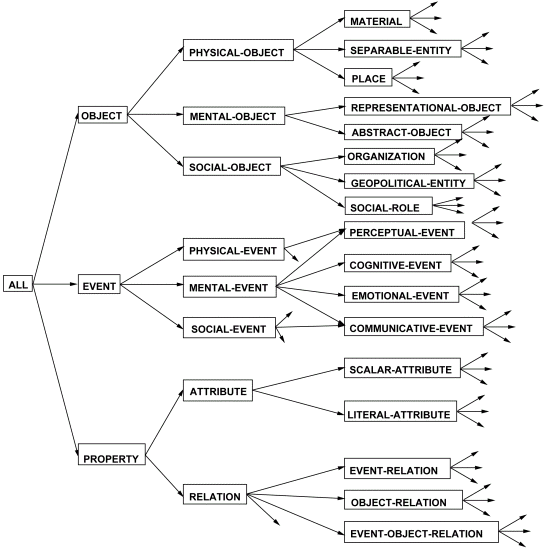
Figura 17: Niveles superiores de la ontología de Mikrokosmos.
| ISSN: 1139-8736 Depósito Legal: B-39120-2002 Copyright: © Chantal Pérez |
Cuando nos propusimos usar una ontología de conceptos para la representación de la estructura conceptual del dominio del cáncer, la primera decisión a tomar atańía al tipo de ontología que queríamos crear (véase sección 5.3.1). Según nuestros planteamientos, para que esta ontología fuera de utilidad en la terminografía, debía permitirnos representar de modo explícito y formalizado, no sólo las características definitorias de los conceptos incluidos, sino también priorizar algunas de éstas características, para dar cuenta de las diferentes perspectivas desde las que puede verse un mismo concepto y, por tanto, debía permitirnos insertarlos en lugares diferentes de la ontología.91 Dada la transdisciplinaridad del ámbito de investigación en el que nos movemos, el cáncer y su tratamiento, la ontología debía reflejar una estructuración conceptual muy rica, en la que estuvieran incluidos conceptos bastante genéricos y de ramas del saber diferentes (como por ejemplo, las partes del cuerpo humano o las relaciones causa-efecto), puesto que, si nos ceńíamos sólo a los conceptos específicos del cáncer, muchas de las propiedades y relaciones de éstos conceptos no iban a poder representarse, al hacer referencia a conceptos de otros ámbitos de especialidad o más genéricos.
La tarea de construir una ontología de estas características, partiendo desde cero, es enorme, por lo que, después de analizar algunas iniciativas de construcción de ontologías con fines médicos ya existentes, decidimos adaptar a nuestras necesidades una ontología (no especializada) ya existente, a la que se ofrece libre acceso para fines académicos:92 la ontología del proyecto Mikrokosmos (mK). Conocíamos ya con bastante detalle la estructura y composición de dicha ontología, puesto que había sido usada anteriormente por un miembro del grupo de investigación en el desarrollo de un lexicón computacional para la traducción automática basada en el conocimiento (véase Moreno Ortiz 1997). Los magníficos resultados obtenidos en dicho proyecto hacían patente la utilidad de los niveles superiores y medios de la ontología de Mikrokosmos para otras aplicaciones de procesamiento del lenguaje natural.
El proyecto Mikrokosmos (mK), del que la ontología es el componente central, es un sistema de KBMT interlingüe desarrollado por el Computing Research Laboratory (CRL) de la New Mexico State University (NMSU), EE.UU., financiado por el Ministerio de Defensa de este país (Beale, Nirenburg & Mahesh 1995, Mahesh & Nirenburg 1995ab). A diferencia de otros proyectos de KBMT anteriores, de dimensiones más reducidas, mK es un sistema práctico a gran escala, enfocado en principio a traducir entre los idiomas inglés y espańol, y que actualmente está siendo expandido para dar cabida a otros idiomas.
mK comenzó siendo un proyecto derivado de Pangloss; de hecho, se inició con el objetivo de superar las deficiencias mostradas por el motor de KBMT de este sistema (Nirenburg et al. 1995). En la actualidad, mK traduce artículos periodísticos espańoles e ingleses sobre adquisiciones y fusiones empresariales sin restricciones de input. Para ello utiliza una serie de lexicones específicos para cada lengua y una ontología de conceptos independiente de cualquiera de las lenguas. Estos dos recursos son utilizados para generar las denominadas TMRs (Text Meaning Representations) que constituyen las representaciones interlingües propiamente. Además del analizador sintáctico, que es el mismo que el utilizado en el proyecto Pangloss, en mK se están desarrollando una serie de algoritmos específicos para problemas concretos, denominados microteorías; se contemplan, por ejemplo, teorías específicas para el aspecto, el tiempo, el género, etc.
A pesar de que mK fuera diseńado para traducir un tipo específico de textos (sobre fusiones y adquisiciones empresariales), el hecho de que no se impusiera restricción alguna en el contenido de los textos de entrada obligó a los creadores de mK a construir una ontología en la que se incluyera un gran número de conceptos generales, y a representar muy variados objetos del mundo, las propiedades de dichos objetos y los eventos en los que dichos objetos se relacionan entre sí o con sus propiedades, es decir, una ontología genérica. La ontología original de mK cuenta con unos 4.700 conceptos, los cuales están conectados con una media de otros 14 conceptos, a través de la asignación de atributos y relaciones.
Para dar una idea de su estructura, la Figura 17 muestra gráficamente la estructuración algunas de las ramas de los niveles superiores de la jerarquía:
Figura 17: Niveles superiores de la ontología de Mikrokosmos.
Como se puede observar existen tres entidades superiores, OBJECT, EVENT y PROPERTY, a partir de las cuales se desarrollan todas las demás. La jerarquía es una red semántica de marcos (véase sección 5.2.3); cada uno de estos marcos posee una rica estructura interna que le permite una gran expresividad. La ontología puede ser considerada como una entidad autónoma en el sentido de que se define a sí misma. Por ejemplo, todas las propiedades adscritas a los objetos o eventos están a su vez definidas en algún punto de la rama PROPERTY (a su vez, las propiedades están dividas en ATTRIBUTEs y RELATIONs).93
Por otra parte, las propiedades de los objetos y eventos se heredan a lo largo de los sucesivos niveles de la jerarquía. Por ejemplo, todos los EVENTs heredan por omisión la propiedad de tomar la propiedad de requerir un AGENT. Si especificamos esta característica al nivel EVENT, todos los conceptos hijos de éste heredarán esta propiedad. Además, la herencia puede ser no monotónica, también llamada herencia negativa, es decir, ha de ser posible especificar que algún elemento no herede alguna propiedad. Por ejemplo, los PASSIVE-COGNITIVE-EVENTs y los INVOLUNTARY-PERCEPTUAL-EVENTs no requieren un agente.94 En cuanto a la profundidad (número de conceptos hijo sucesivos) de las ramas de las diferentes jerarquías, la ontología llega a poseer diez niveles o más en un buen número de ramas.
La creación de una ontología de estas características es una labor enormemente compleja y costosa en recursos técnicos, humanos y tiempo. El principal problema con la construcción de ontologías es, obviamente, la enorme dificultad y esfuerzo que conlleva. Los intentos de generar ontologías de forma automática o semi-automática han dado siempre escasos frutos, imponiéndose la realización manual de la misma. En mK se optó por desarrollar una serie de herramientas que facilitasen la construcción manual de la ontología. Estas herramientas se encargaban de comprobar la consistencia de la información introducida y de generar el código (Lisp) necesario a partir de la información que el operador introduce mediante la interfaz gráfica. De todos modos, se trató de una ardua labor, porque supone la estructuración del conocimiento humano partiendo no desde un dominio determinado sino desde el nivel más alto.
Un problema ańadido es la inexistencia de una metodología definida para la creación de ontologías, es decir, no existe un algoritmo que permita la adquisición de conceptos. Lo que sí existen son una serie de líneas maestras desarrolladas a partir de la experiencia acumulada por los investigadores en el campo. Una ontología de este tipo se adquiere de forma incremental, a través de una interacción continua con otras fuentes de conocimiento, lo que en el caso de mK, dio lugar a un desarrollo en paralelo de ontología y lexicón.95
Para guiar la labor de los ontólogos y los lexicógrafos del proyecto, los investigadores de ?K propusieron una serie de recomendaciones para guiar la inclusión de nuevos conceptos en la ontología (Mahesh & Nirenburg 1995a, 1995b, Mahesh 1996). Como estos autores afirman, esta lista no está cerrada, sino que sigue aumentando y refinándose con la experiencia acumulada. Las recomendaciones más importantes son las siguientes:
La mayoría de las recomendaciones para la compilación hechas por los creadores de mK nos resultaron muy útiles cuando comenzamos el proceso de extender y completar las ramas de la ontología en la que debían insertarse los conceptos específicos de la oncología. Por otra parte, el estudio de otros proyectos de representación del conocimiento médico reforzó la decisión de reutilizar la ontología de mK para el proyecto OncoTerm, puesto que esto nos permitiría (i) integrar en ella información obtenida de otras fuentes de conocimiento disponibles (sobre todo sistemas de clasificación de enfermedades, como el ICD y organizaciones conceptuales ya existentes, como el Semantic Network del UMLS, véase sección 4.3.3.3); (ii) integrar la información extraída del estudio del corpus textual informatizado.
Además, el empleo de la ontología de mK presentaba, además, otras ventajas adicionales que, a nuestro juicio, la hacían más adecuada para su uso en el proyecto OncoTerm que otros sistemas existentes o en desarrollo, fundamentalmente:
Sin embargo, nos habría sido virtualmente imposible aprovechar ninguna de las características de la estructura y composición de la ontología de mK si no hubiéramos contado con el sistema gestor de ontologías que mostramos en el apartado siguiente, desarrollado por el Dr. Moreno Ortiz. Como ya hemos mencionado, la ontología de mK se ofrece al público en código LISP por lo que, sin contar con un programa específicamente diseńado para tal fin, habría sido imposible realizar ni la más simple de las consultas en la ontología. Gracias a la interfaz gráfica de usuario del gestor de ontologías, nos ha sido posible realizar, de forma muy sencilla, las tareas de consulta, modificación y entrada de conceptos en la ontología.
Además, dicho gestor de ontologías, ha sido integrado en un sistema gestor de base de datos terminológica basado en el conocimiento. La aplicación en su conjunto, denominada OntoTerm®, hace posible relacionar de forma directa conceptos de la ontología con términos contenidos en una o varias bases de datos terminológicas. Las ventajas de este tipo de estructuración de la información terminológica, así como la filosofía de diseńo de dicha base de datos serán expuestas en el apartado 5.5 y siguientes; pasamos ahora a mostrar el funcionamiento del otro componente de OntoTerm: el gestor de ontologías.
Notas
91 Por ejemplo, algunos tipos de quimioterapia pueden verse como un tratamiento para combatir el cáncer y como un carcinógeno, puesto que como efecto secundario pueden también provocar determinados tipos de cáncer.
92 Hay que aclarar que lo que el proyecto mK pone a disposición de la comunidad académica es la ontología en formato Lisp, pero no los programas que facilitan la consulta, edición y modificación de la ontología. Información sobre el proyecto mK y su ontología puede obtenerse en su sede web en http://crl.mnsu.edu/users/mahesh/onto-intro-page.htm
93 En esta figura no aparece el mencionado ONTOLOGY-SLOT, que es un concepto hijo de PROPERTY. En general, está sección de meta-categorías podemos ignorarla, ya que no representa una estructuración conceptual real, sino tan sólo una serie elementos necesarios para calificar a la ontología de autónoma.
94 Esto se consigue en la ontología de mK mediante el operador *NOTHING*.
95 El método ideal de desarrollo de ontologías para su uso en KBMT contempla el desarrollo en paralelo de una ontología y dos o más lexicones (Mahesh 1996); de este modo se facilita la independencia de la lengua de los conceptos contenidos en la ontología, y se garantiza que se cubren las necesidades de representación de las lenguas descritas en los lexicones.
96 Información extensa sobre el proyecto GALEN puede obtenerse a través de su sede web en la dirección http://www.cs.man.ac.uk./mig/galen/index.htm Este proyecto, finalizado en diciembre del1994, ha tenido su continuación en el proyecto denominado GALEN-IN-USE, en el que se quiere desarrollar un modelo europeo de común referencia para los procedimientos médicos.
| ISSN: 1139-8736 Depósito Legal: B-39120-2002 Copyright: © Chantal Pérez |