Figura 16: Ejemplo de red IS-A
| ISSN: 1139-8736 Depósito Legal: B-39120-2002 Copyright: © Chantal Pérez |
Los responsables de los primeros esquemas de representación formalizados fueron Quillian (1968) y Shapiro & Woddmansee (1971). Los elementos básicos que invariablemente encontramos en todos los esquemas de redes, comúnmente denominados redes semánticas, son:
Básicamente, podemos distinguir tres tipos tradicionales de redes semánticas:
En general, cuando se habla de redes semánticas se suele hacer referencia a uno de estos esquemas, normalmente a las redes IS-A o a los esquemas basados en marcos, que comparten ciertas características fundamentales, mientras que los grafos conceptuales presentan diferencias importantes. De entre estas características compartidas destacamos la herencia por defecto (default inheritance). En una red semántica, los conceptos (estructuras, clases, marcos, dependiendo del esquema concreto) están organizados en una red en la que existe un nodo superior (top: T) al que se le asigna uno o varios nodos hijos, que a su vez tienen otros conceptos hijos y así sucesivamente hasta que se alcanza el final (bottom), cuyos nodos pueden ser o bien conceptos, o bien instancias.
De los tres tipos de redes semánticas, el esquema basado en marcos es el que permite una mayor flexibilidad, y el que ha recibido mayor atención por parte de los investigadores de ciencia cognitiva y lingüística. Los grafos conceptuales también siguen recibiendo en la actualidad mucha atención por parte de algunos investigadores, aunque cuentan con muchos detractores.
Sin duda el tipo de red semántica por excelencia es el de redes IS-A; de hecho, muchas veces se menciona este tipo como sinónimo de red semántica, y los restantes tipos también incorporan este tipo de enlaces o arcos (links). Una red IS-A es una jerarquía taxonómica cuya espina dorsal está constituida por un sistema de enlaces de herencia entre los objetos o conceptos de representación, conocidos como nodos. Las redes IS-A son el resultado de la observación de que gran parte del conocimiento humano se basa en la adscripción de un subconjunto de elementos como parte de otro más general. Las taxonomías clásicas naturales son un buen ejemplo: un perro es un cánido, un cánido es un mamífero, un mamífero es un animal.
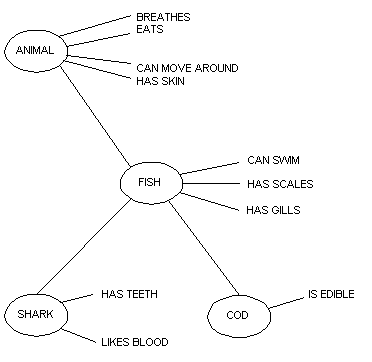
La representación mediante la lógica de predicados es suficiente para expresar las relaciones entre los elementos, pero la estructuración jerárquica facilita que la adscripción de propiedades a una determinada categoría se reduzca a aquellas que son específicas a la misma, heredando aquellas propiedades de las categorías superiores de la jerarquía, tradicionalmente de una forma monotónica, es decir sin excepciones. El siguiente ejemplo de red IS-A (Figura 16), tomado de (Brachman 1983: 31) ejemplifica una red semántica típica con herencia de propiedades.
Figura 16: Ejemplo de red IS-A
El concepto de herencia es fundamental para entender el funcionamiento de las redes semánticas. Siguiendo a Shastri (1988), definimos la herencia como el sistema de razonamiento que lleva a un agente a deducir propiedades de un concepto basándose en las propiedades de conceptos más altos en la jerarquía.
Como Brachman (1983) recuerda, los nodos de las estructuras IS-A se han usado para representar muchas cosas, pero la división más importante es la interpretación genérica o específica de los nodos, es decir, si éstos representan un sólo individuo o varios. Los nodos situados en lo más bajo de la jerarquía y que denotan individuos concretos o instancias, son llamados tokens, mientras que los nodos superiores, que denotan clases de individuos son considerados types.84
Puesto que en una misma jerarquía podemos obtener nodos de ambos tipos, se debe hacer explícita una distinción de los tipos de enlaces. Por un lado existen enlaces que conectan categorías (genéricas) con otras categorías, y por otro, enlaces entre categorías e individuos. Las primeras pueden expresar relaciones como por ejemplo: subconjunto/ superconjunto, generalización/ especificación, AKO, es decir, a kind of, contenido conceptual, restricción de valores y tipo característico del conjunto. Las relaciones genérico/individuales también pueden ser de varios tipos: pertenencia al conjunto, predicación, contenido conceptual y abstracción.
Las redes IS-A son muy flexibles, pero los investigadores de IA han puesto de manifiesto algunos problemas y desventajas importantes, entre los que cabe destacar los siguientes:
Esto llevó a idear otros esquemas de representación con una estructura más compleja que simples nodos y arcos, que fuesen capaces de dar cabida a éstas y otras situaciones. Concretamente, John Sowa (1984) propuso los grafos conceptuales, aunque el esquema de representación basado en marcos (frames) es el que ha tenido mayor aceptación.
Además de las redes ISA y los grafos conceptuales existe otro esquema de representación del conocimiento muy usado en los últimos ańos: los esquemas de marcos. El primer proponente de la noción de marco (frame) fue el psicólogo cognitivo Marvin Minsky, quien resume su esencia de este modo:
Here is the essence of frame theory: When one encounters a new situation (or makes a substantial change in one’s view of a problem), one selects from memory a structure called a frame. This is a remembered framework to be adapted to fit reality by changing details as necessary. Minsky (1975: 211)
La fundamentación psicológica de los marcos es parecida a la de los scripts de Schank (Schank et al. 1977): cuando nos enfrentamos con una situación determinada, intentamos ajustarla a otra parecida de la que ya tenemos experiencia previa y esperamos que aparezcan un número de elementos comunes y se sucedan algunas situaciones. Por ejemplo, si entramos en una habitación de hotel, esperamos encontrar una cama, un armario, un bańo, etc. Nuestra mente reconocerá las instancias específicas de la nueva habitación y los acomodará al estereotipo que ya poseemos. La base de la teoría la conforman, por tanto, las situaciones estereotipadas.
Informalmente, un marco es una estructura de datos compleja que representa una situación estereotipada, por ejemplo hacer una visita a un enfermo o acudir a una fiesta de cumpleańos. Cada marco posee un número de casillas (slots) donde se almacena la información respecto a su uso y a lo que se espera que ocurra a continuación. Al igual que las redes semánticas, podemos concebir un marco como una red de nodos y relaciones entre nodos (arcos). Una base de conocimiento basada en marcos es una colección de marcos organizados jerárquicamente, según un número de criterios estrictos y otros principios más o menos imprecisos tales como el de similitud entre marcos. A nivel práctico, podemos considerar los marcos como una red semántica con un número de posibilidades mucho mayor, entre las que destacan especialmente, la capacidad de activación de procesos (triggering) y de herencia no-monotónica mediante sobrecontrol (overriding), en la que un nodo hijo hereda todos los slots de su padre a menos que se especifique lo contrario.
Como es evidente, la representación de conocimiento basada en marcos debe mucho a las redes semánticas. Sin embargo, los esquemas de representación basados en marcos insisten en una organización jerárquica de éstos, mientras que las redes semánticas no requieren tal organización. La estructura de nodos de los marcos es también mucho más rica que la de las redes semánticas, conteniendo sistemas de activación de procesos (triggering). Esto ocurre cuando en lugar de llenar un slot con un valor determinado, se indica un procedimiento que será el encargado de devolver un determinado valor.
Podemos resumir las principales características de los marcos en las siguientes (Minsky 1975; Winograd 1975):
El potencial de estas características puede verse, por ejemplo, en los mecanismos de razonamiento que son capaces de llevar a cabo: el razonamiento en un esquema basado en marcos se lleva a cabo mediante dos mecanismos básicos: el reconocimiento (recognition o pattern-matching) y la herencia. En el entorno de los marcos el proceso de reconocimiento de patrones se centra en encontrar el lugar más apropiado para un nuevo marco dentro de la jerarquía de marcos. Esto requiere que el mecanismo de reconocimiento sea capaz de recibir información sobre la situación existente (en forma de marco) y lleve a cabo una búsqueda del marco más adecuado de entre todos contenidos en la base de conocimiento.
Desde la formulación teórica de Minsky han existido diversas implementaciones de este sistema representacional, entre los que cabe destacar los ya considerados clásicos KRL, OWL y, sobre todo, KL-ONE (Brachman & Schmolze 1985). Este último es sin duda el más relevante, en cuanto que a partir de él han surgido numerosos sistemas de representación del conocimiento que se están desarrollando o usando hoy en día. De hecho, se suele hacer referencia a los lenguajes de programación /representación basados en marcos mediante el calificativo "al estilo de KL-ONE". KL-ONE es el producto de muchos ańos de investigación de algunos de los que se pueden considerar como padres de la representación del conocimiento, entre los que destacan Ronald Brachman, Rusty Bobrow, Hector Levesque, Jim Schmolze o William Woods.
Como es habitual en las implementaciones de marcos, una taxonomía de KL-ONE comprende conceptos, con un número de propiedades atribuidas y una serie de relaciones entre conceptos. Más concretamente, un nodo (concepto) de KL-ONE consiste en un conjunto de roles (generalizaciones de las nociones de atributo, parte, constituyente, rasgo, etc.) y un conjunto de condiciones estructurales que expresan relaciones entre esos roles. Los conceptos están enlazados a conceptos más generales en una relación especial llamada SUPERC. El concepto más general en la taxonomía es denominado superconcepto, y subsume (es más general que) todos los demás.
De lo que no cabe ninguna duda es que el sistema de representación basado en marcos es el que ha contado con mayor aceptación ya que es enormemente flexible e impone un número muy reducido de restricciones en lo que respecta a su implementación.85 Las modernas ontologías de conceptos (véase § 5.3) se basan en mayor o menor medida en un modelo de marcos, aunque, en general, no emplean sistemas de activación de procesos por tratarse de representaciones con un marcado carácter estático, enfocadas a surtir de información a otras aplicaciones que contienen los procedimientos.
Cabe preguntarse si en realidad es necesario emplear un complejo sistema de representación del conocimiento para la gestión terminológica.86 En la práctica, sólo es indispensable un sistema que permita la creación de jerarquías conceptuales, la asignación de atributos y características a los conceptos y la explicitación de relaciones entre conceptos, garantizando la coherencia interna del conjunto de conceptos: por ejemplo, que no existan conceptos repetidos, se anule la posibilidad de crear estructuras circulares, además, por supuesto, de permitir la asignación de términos a estos conceptos.
Después de estudiar los esquemas de representación más destacados de los que podemos servirnos para la representación del conocimiento especializado, la opción adoptada en ese sentido ha sido bastante práctica: pensamos que sería adecuado contar con un sistema de representación conceptual compatible con sistemas de representación más complejos con los que acabamos de describir, pero que no presentara una complejidad inherente que, en vez de facilitar, dificultara el trabajo terminográfico.
Lo ideal sería contar con un sistema de representación conceptual que impusiese muy pocas restricciones en cuanto al modo de trabajo básico del terminólogo moderno, facilitándole la tarea en cuanto a organización conceptual se refiere y, al mismo tiempo, estuviese basado en esquema conceptual válido y aceptado como sistema de representación del conocimiento. Evidentemente, un sistema así abre un número de posibilidades que van más allá del trabajo terminográfico, permitiendo su integración con sistemas computacionales de Inteligencia Artificial en general, sistemas expertos, Traducción Automática, etc.
Además, debemos pensar que un sistema de estas características nos ofrece un valor ańadido considerable puesto que, aunque no saquemos partido de características procedimentales avanzadas, tales como el reconocimiento de patrones, sí que nos puede ser muy útil la herencia de valores por defecto. Ésta, además de ahorrar trabajo y tiempo, nos ayuda a validar una estructura conceptual determinada: si, por ejemplo, un número considerable de valores heredados han de ser sobrecontrolados (negados), entonces puede ser que nuestra jerarquía conceptual sea errónea.
Una herramienta de este tipo permitiría al terminógrafo comprobar que la estructura conceptual del ámbito de especialidad cuya terminología ha de sistematizar se ajusta a sus necesidades y es lo suficientemente completa y coherente. Por supuesto que la adopción de tal sistema va a suponer una serie de restricciones e imposiciones metodológicas, ya que, por ejemplo, el sistema no nos va a permitir introducir un término sin antes especificar el concepto al que se debe asignar y para introducir un concepto va a ser necesario especificar el lugar que éste ocupa en la jerarquía (de qué concepto es hijo). Sin embargo, pensamos que las ventajas que se obtienen compensan con creces este trabajo adicional ya que este tipo de sistema nos va a imponer un método de trabajo estricto que va redundar en una base terminológica altamente estructurada y con todas las garantías en cuanto a coherencia interna.
Exponemos a continuación la fundamentación teórica, el funcionamiento y la filosofía de diseńo de un sistema gestor de base de datos terminológica que posee todas las características mencionadas anteriormente, puesto que permite representar la información terminológica de forma sistemática, completa y modular.
Notas
84 Como ya vimos, estos dos términos hacen referencia a cosas muy distintas en el discurso de la lingüística de corpus (§ 2.6).
85 Un buen ejemplo de esto es el sistema de representación del conocimiento denominado Loom, un proyecto del Information Science Institute de la University of Southern California que se encuentra disponible para usos académicos (http://www.isi.edu/isd/LOOM/LOOM-HOME.htm implementado en Common Lisp y que requiere un compilador de este lenguaje para su funcionamiento. Loom consiste básicamente en un conjunto de conceptos y funciones predefinidos, junto con una extensa biblioteca de funciones, macros y métodos que suman un total de casi 250. El conocimiento declarativo en Loom se expresa mediante definiciones, reglas, hechos y reglas por defecto. Posee un motor de deducción denominado "clasificador", encargado de mantener y compilar el conocimiento declarativo en una red diseńada para el procesamiento de consultas que impliquen capacidad de deducción a partir de los hechos y reglas contenidos en la base de conocimiento.
86 Skuce & Lethbridge (1995) y Moreno Ortiz (1997) resumen algunos de los más destacados sistemas de representación de conocimiento.
| ISSN: 1139-8736 Depósito Legal: B-39120-2002 Copyright: © Chantal Pérez |