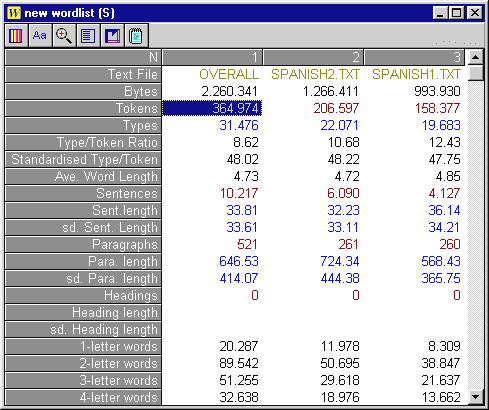
Figura 3: Índices de frecuencia de dos ficheros realizado con WordSmith Tools.
| ISSN: 1139-8736 Depósito Legal: B-39120-2002 Copyright: © Chantal Pérez |
Casi todos los programas mencionados en el apartado anterior nos ofrecen las herramientas básicas de manejo de corpus, como por ejemplo la capacidad de realizar listados de las formas (types) que aparecen en un corpus, ordenados de diferentes maneras, ya sea por orden alfabético, frecuencia, o en algunos casos por orden alfabético inverso, e índices estadísticos sobre el número de palabras, oraciones o párrafos y la longitud de éstos.
Estos listados pueden ser de gran utilidad lexicográfica, ya que ayudan a decidir la lista de voces que han de incluirse en un diccionario, teniendo en cuenta su frecuencia de uso o, por ejemplo, para decidir qué vocabulario básico debe incluir un diccionario escolar. También pueden ofrecernos índices de frecuencia en los que muestre la ratio palabras/formas (type/token), es decir, el número total de palabras de un texto frente al número de palabras diferentes que a parecen en el mismo o comparar los índices en varios ficheros de texto. En la Figura 3, mostramos una captura de pantalla tomada del programa WordSmith Tools en el que se compara la lista de palabras y la ratio palabra/forma de dos ficheros de texto diferentes. Este tipo de cálculo puede ser fundamental para establecer el grado de representatividad del corpus que estamos usando. Sánchez & Cantos (1997), por ejemplo, desarrollan un procedimiento estadístico para predecir la relación entre formas y palabras en un corpus, de forma que éste puede subdividirse en secciones más pequeńas o subcórpora (ver sección 2.3.2), que son más fáciles de manipular y analizar pero que guardan la estructura y la consistencia interna del corpus completo y que son similares en lo que respecta a variación lingüística.
Figura 3: Índices de frecuencia de dos ficheros realizado con WordSmith Tools.
Tanto WordSmith Tools como TACT cuentan con una serie de herramientas para preprocesar el texto antes del análisis. Estas herramientas nos permiten ańadir etiquetas morfosintácticas (tags) al texto a partir de un diccionario creado con las formas extraídas del texto, lematizar el texto, asignando diferentes formas a una misma forma canónica, o crear una lista de palabras que, por ejemplo, dada su alta frecuencia no queremos incluir en nuestra búsqueda (StopWord Lists).
Otra de las herramientas de manejo de corpus más importante y versátil para el estudio lingüístico son los programas que proporcionan de forma automática líneas de concordancia de una palabra. Una concordancia, normalmente llamada KWIC (Key Word in Context) es una colección que recoge todas las apariciones de una palabra en un texto o conjunto de textos, junto con un número determinado (normalmente por el lexicógrafo) de caracteres de co-texto anterior y posterior (la palabra que se está estudiando o nodo, suele aparecer en medio, resaltada en pantalla con un formato o color diferente).
De esta forma es posible visualizar a la vez una gran cantidad de ejemplos de uso de una palabra o un grupo de palabras. Las posibilidades de trabajo con las líneas de concordancia dependerán en gran medida del paquete informático que estemos manejando. La mayoría de ellos nos permitirán obtener un número determinado de líneas (100, 200, o todas las que aparezcan en el texto) y ordenarlas posteriormente de diferentes maneras: alfabéticamente, de acuerdo con la palabra inmediatamente anterior o posterior al nodo o en relación a la palabra que aparezca dos, tres, etc. posiciones a la derecha o izquierda de nuestro nodo (el nodo también puede ser, a su vez, una sola palabra o un grupo de palabras).
Algunos programas están limitados en cuanto al número de líneas de concordancia que pueden ofrecernos, como por ejemplo MicroConcord que, al servirse únicamente de la memoria convencional de DOS, suele limitar el número de líneas que puede extraer a una cifra entre 1500 y 1700.
La Figura 4 es una captura de pantalla que muestra algunas líneas de concordancia de la palabra inglesa "term" (ordenadas según la primera palabra que aparece antes del nodo), extraídas con la herramienta Concord de WordSmith Tools.
Estos diferentes tipos de ordenación permiten centrar nuestra atención en el co-texto inmediatamente anterior o posterior de la palabra (por ejemplo, para estudiar tipos comunes de sujetos y complementos en el caso de un verbo), o en el tipo de modificación adjetival que lleva un sustantivo determinado o, al revés, el tipo de sustantivos a los que acompańa un adjetivo determinado. Muchos de estos programas permiten el uso de caracteres comodín (wildcards), con los que se puede buscar diferentes formas de una misma palabra o realizar búsquedas difusas, múltiples y de frases idiomáticas con un cierto grado de variación.
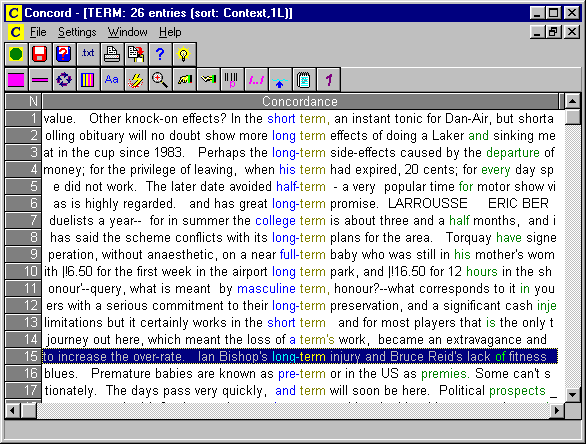
Figura 4: Líneas de concordancia extraídas con la utilidad Concord de WordSmith Tools.
Con la mayoría de los programas que existen en el mercado también podremos identificar la fuente original de una línea de concordancia determinada, ampliar el co-texto o acceder al texto original al que un ejemplo determinado pertenece. Los ficheros de líneas de concordancia pueden almacenarse en el ordenador para después editarlos y manipularlos con un procesador de texto. Como decimos, todas estas posibilidades dependerán del paquete informático que se use, ya que algunos son más limitados que otros tanto en la cantidad de texto que pueden manejar a la vez como en la variedad de análisis que ofrecen. La Figura 5 muestra algunas líneas de concordancia de la palabra inglesa "term", extraídas con Micro Concord (OUP):
MicroConcord search SW: term
90 characters per entry
Sort : SW/1L
r: low grade facilities destroyed in Iraq. Long-term contamination in small areas lik
ng to a 120mph wind, so you don't hear it. Short-term memory also comes low on the li
ney supply, and thus inflation. The Medium Term Financial Strategy as it was dubbed
means that the ERM has replaced the Medium Term Financial Strategy as the bedrock of
llow the international players to enjoy an end-of-term pillow fight. In South-west Lo
of innocence Michael Henderson on the end-of-term attractions of the Rosslyn Par
heme did not work. The later date avoided half-term - a very popular time for moto
f the club.'' Us, name-drop? Surely not. A long-term injury to Brian Gayle has prompt
t to increase the over-rate. Ian Bishop's long-term injury and Bruce Reid's lack of
(Even better, stretch it into Sunday.) In long-term, relationships, hanging on means
e a cool I
!5.5 billion in a full year. The long-term success of this Budget may well
ny other new entrant into the market. The long-term aim would be to have numbers tha
accident.'' So when you finally get into a long-term relationship . . . "Who knows. T
ndship and communication. You could meet a long-term lover in a bar. Many of my frien
hs had been dropping amorous hints about a long-term relationship upped and disappear
work here if only someone will commit to a long-term investment,' says Mark Edwards,
nomy with wider ownership of wealth; and a long-term commitment to future generations
tral striking role, when Agana picked up a long-term injury, and has responded with e
r have a realistic shot at developing into long-term love. Part of negotiating your w
u find it difficult to get aroused by your long-term partner and it may be necessary
ten minutes to lodge then securely in your long-term memory. 4 Remember pictures. Ins
fficult for chemical companies to tackle a longer-term difficulty facing up to the
market tightens, anyone willing to take a longer-term view will be able to take adv
education budget. But the most effective longer-term measure for a green Budget wou
for the next thing. Whatever that is, his longer-term ambition seems to be increasin
should not distract policy-makers from the longer-term, underlying issue. Britain's k
t term planning. Let me see
nd disrupted agriculture could be the main medium-term effects, say the World Conserv
is yet to decide whether there should be a mid-term election and, if so, who would he
ming fashionable to see him as a potential one-term President. He'd had a tremendous
baby blues. Premature babies are known as pre-term or in the US as premies. Some can
distortions from savings allocation, not a short-term fix hiding behind false claims
at by Richard Branson, he was engaged on a short-term contract by BA chairman Lord Ki
endence of the office is worth more than a short-term political gain.'' It's just th
a chains will do much good. They are after short-term profit, and Hollywood makes tha
ch larger and a much longer trial, and any short-term benefits from early AZT treatme
have stopped launching into niches to make short-term profits. And it is thought that
e then she says We need to standardize our short-term planning and this is what we're
agnosed as having Koirsakoff's Psychosis - short-term memory loss resulting from long
th have advantages for those who want some short-term guarantee of interest-rate stab
e of payments encourages this view: in the short-term, at least, Britain's foreign ex
t interested in returning to quotas in the short-term nor in changing the market moni
ify the discussion, let us use the British term of 'personal allowances' to refer to
." "What is 'GNILLIC'? "That is the Eskimo term for 'snow.'" "So you knew the English
rs, be they complex, real or rational. The term modern algebra can then be used to de
page there is reference to a "bistro'', a term which apparently did not come into use
ected that scientists should have coined a term for so ostensibly unscientific a purs
ch like a rock band. Parallax, otherwise a term which in physics relates to the chang
for the contemporary use of ``bitch'' as a term of endearment is culled from the lett
y dead. Instead, ``luggable'' is used as a term of abuse for portables that ought to
at trial judges should be free to impose a term of imprisonment that they believe fit
ow, the ``real books'' phrase has become a term of disapproval, a convenient shibbole
who wonder if their party deserves another term of office. And, frankly, more of the
ty. The team leader probably in the autumn term will be language and music that will
time I checked, a stonker was a colloquial term for what a man gets if he's on a long
rents. I also go to boarding school during term time. All this makes it impossible fo
vival, started during Mr Heseltine's first term as Environment Secretary, is well est
1981). Michael Heseltine, in his first term as Environment Secretary, also warned
that he would not seek a second five-year term of the institution that provides more
vative Party had been elected for a fourth term and appears to have convinced itself
general reference point, but as a general term of abuse. Intermittently they stamp o
dvantage of the defendant, and in the long term to the police as well. While there i
ted widely and which may have unknown long term effects. Amniocentesis involves extra
ttlement of Offenders, said: ``In the long term the Government should reduce the numb
uncertainty in the short term; in the long term it offers enormous opportunities it
rely to offset inflation and in the longer term the extra indexing of the threshold w
says ``higher petrol prices in the longer term are both necessary and unavoidable''.
off each month. At the end of the mortgage term the borrower owes nothing. Repayment
each month, and at the end of the mortgage term (usually 25 years) the debt will be c
ve jobs we enjoy, a daughter in her second term at university and a 14-year-old son a
h still looked like a shoo-in for a second term in the White House, Margaret Thatcher
idn't invest in new players just for short term success, although that is what we wan
ad of England. It looks like, in the short term at least, he made the right choice.
originally an early 20th century US slang term of abuse either for any lesbian or for
the noise of closing doors, in the spring term of the first year of the ``sixth-form
t school only during the present teacher's term of office. The regular scholars, if t
is exobiology? In fact, it's the technical term for the study of alien life in space.
. Since the turn of the year, though, the term ``expansive'' has disappeared from Co
ests, on the manner and sense in which the term is used: positive and life-affirming?
r). He seems unaware that criticism of the term "adolescence'' in relation to sexual
c violence yes I agree with the use of the term domestic violence but this is not the
ow where they were. I don't know where the term "junglist'' (hardcore Techno's domina
inal festival band (provided you allow the term "original'' a certain latitude). The
ton, Cheshire Commonplace criticism of the term 'adolescence' MARK SHIMPSON accused m
modern classic from the man who coined the term 'homophobia'. LESBIAN Somewhere Like
azz Dancing, Class of '89'') redefines the term 'engaging': as in, I'd like to engage
h and many men did not even understand the term `sexual intercourse' used in the titl
y camps and high camp. Black comedy is the term which springs to mind, but it would b
e Government has been careful to avoid the term ``victory'' in relation to these even
as a proxy for an academic record; but one term's work cannot yield ``evidence'' of p
ministrative legal area), during one legal term, there were 24 travelling days listed
embarrassment causes blushing. In the long term, emotional stress affects the pituita
gger' and 'faggot'. It's such a pejorative term, one I associate with a mode of think
Figura 5: Líneas de concordancia de la palabra term extraídas con MicroConcord.
Únicamente con echar un vistazo a estas líneas de concordancia (que son una fracción mínima de las que aparecen en nuestro corpus) pueden verse no sólo los co-textos de uso más frecuentes de la palabra term (term of abuse, term of disapproval, term of office, jail term, prison term, in the short/long term), sino también alguno de los compuestos en los que aparece: long-term, short-term (con y sin guión), medium-term, mid-term, medium-to-long term, end-of-term, full-term (baby), one-term (President), etc.
La mayoría de las herramientas incluyen también una serie de cálculos estadísticos, que pueden ir desde simples índices de frecuencia de aparición de una determinada forma (o formas) en el corpus e índices de asociación de palabras (colocaciones), hasta cálculos estadísticos muy complejos, desarrollados en centros de investigación especializados, en muchos casos orientados a la traducción automática, la adquisición automática de información léxica o la recuperación de información.
El estudio de los hábitos colocacionales de las palabras es uno de los caballos de batalla de las actividades relacionadas con la enseńanza y aprendizaje de la lengua, la traducción automática y la lexicografía, tanto monolingüe como bilingüe.22 Sin embargo, es una de las áreas en la que los estudiantes y los usuarios potenciales de un diccionario necesitan más ayuda, ya que no resulta nada fácil llegar a dominar las combinaciones de palabras que se perciben como idiomáticas en una lengua extranjera. Los lexicógrafos, por ejemplo, a la hora de estudiar una palabra o grupo de palabras y sus hábitos colocacionales, necesitan herramientas que les asistan en el análisis de las diversas combinaciones que pueden observarse en un corpus, sobre todo en aquellos casos en los que el corpus cuenta con un número muy elevado de palabras y/o cuando la palabra en cuestión presenta un índice de aparición muy alto, por lo que sería prácticamente imposible estudiar todas y cada una de las líneas de concordancia manualmente (Clear 1994).
Por esta razón, es muy útil contar con herramientas computacionales que ofrezcan listados de colocaciones, así como la posibilidad de ordenarlas según diferentes cálculos estadísticos. La Figura 6, por ejemplo, muestra las colocaciones más frecuentes de la palabra term (en posición inmediatamente posterior y anterior), en relación a las líneas de concordancia que habíamos extraído anteriormente:
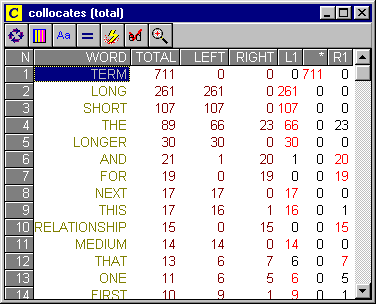
Figura 6: Colocaciones más frecuentes de la palabra "term" extraídas con Concord (WordSmith Tools).
Algunos de estos cálculos estadísticos son muy útiles para el estudio de las colocaciones, como por ejemplo uno de los índices que muestran la frecuencia de asociación denominado índice de información mutua (MI Score), en el que se mide la fuerza de asociación entre dos palabras, es decir, la cantidad de información que la aparición de una palabra nos da sobre la aparición de otra (Church & Hanks 1990). Esta medida estadística calcula la probabilidad de que las dos palabras (x y z) aparezcan juntas, calculando la probabilidad de que x y z aparezcan de forma independiente y después compara los dos valores. Si existe una asociación fuerte entre x y z, la probabilidad de que aparezcan juntas deberá ser mucho mayor que la de que aparezcan por separado. En caso de que los dos valores de frecuencia sean muy similares, la concurrencia de las dos palabras no suele considerarse muy significativa.
Clear (1993) discute en profundidad la utilidad lexicográfica del índice de información mutua, comparándolo con otro índice que también se usa con bastante frecuencia en lexicografía, el T-score, que mide, no como el anterior, la fuerza de la asociación de dos palabras, sino el grado de confianza con que se puede decir que existe una asociación de palabras. Las palabras que poseen un índice de frecuencia más alto en el corpus (preposiciones, pronombres o artículos) ofrecerán también un índice de colocación t-score mayor, de forma que índices significativos de esta medida suelen seńalar colocaciones muy fuertes o asociaciones entre palabras léxicas y gramaticales (por ejemplo, preposiciones con verbos o con adjetivos), mientras que el índice de información mutua suele indicar asociaciones que son estadísticamente significativas (aunque la frecuencia de aparición de los elementos de la colocación en el corpus sea muy baja), por lo que suele seńalar asociaciones semánticas entre palabras o elementos de una unidad fraseológica.
A modo de ejemplo, compárense una sección el índice de frecuencia de asociación t-score (Figura 7)y el índice de información mutua (MI) (Figura 8) de la palabra term, obtenidos a través del servicio CobuildDirect, ofrecido por la editorial Collins Cobuild en su servidor de Internet, el cual posibilita la consulta de una parte de su corpus, el citado Bank of English (50 millones de palabras, lematizadas y etiquetadas), al que se accede a través de una potente herramienta de manejo de corpus denominada lookup. El programa permite seleccionar secciones del corpus, crear concordancias, hacer búsquedas complejas y, como vemos en las dos figuras que siguen, ofrecen diversos cálculos estadísticos:
long 35566 3108 54.974874 |
short 11038 1307 35.781761 |
the 2872094 4793 18.863081 |
longer 7811 347 18.118833 |
this 224039 697 16.097594 |
for 482791 1121 15.974017 |
a 1228514 2147 14.145253 |
term 8714 198 13.319368 |
in 958631 1670 12.384545 |
end 28018 185 11.100465 |
year 76008 276 11.058452 |
medium 1631 123 10.911984 |
used 28519 170 10.382740 |
use 25110 155 10.001151 |
rates 5737 110 9.823960 |
effects 3888 103 9.683765 |
during 22181 137 9.403872 |
interest 12573 115 9.300319 |
investment 5173 95 9.102411 |
fixed 2359 87 9.020313 |
is 499929 873 9.003541 |
future 11901 103 8.725160 |
jail 2450 76 8.376587 |
second 25016 121 8.238859 |
relationship 7062 81 8.047317 |
next 32264 130 7.966097 |
last 67959 190 7.798093 |
psychotherapy 278 59 7.637204 |
contract 4831 68 7.534923 |
contracts 1667 57 7.281756 |
savings 2607 59 7.269069 |
mid 3678 60 7.169467 |
Figura 7: T-score de las colocaciones de la palabra term (CobuildDirect).
endearment 24 13 8.802222 |
michaelmas 19 5 7.760641 |
psychotherapy 278 59 7.450312 |
coined 116 23 7.352181 |
duisenberg 16 3 7.271555 |
dyads 22 4 7.227156 |
crocks 37 6 7.062080 |
incapacity 41 6 6.913967 |
absentees 22 3 6.812077 |
gits 24 3 6.686534 |
derogatory 65 8 6.664164 |
short 11038 1307 6.608378 |
penal 93 11 6.606799 |
prioress 32 3 6.271455 |
legislator 43 4 6.260227 |
pathways 154 14 6.227056 |
long 35566 3108 6.170042 |
imprecise 37 3 6.061981 |
involvements 37 3 6.061981 |
maturities 50 4 6.042613 |
colloquial 39 3 5.986024 |
medium 1631 123 5.957435 |
crock 81 6 5.931571 |
generic 149 11 5.926721 |
vp 75 5 5.779553 |
outweigh 91 6 5.763610 |
longitudinal 97 6 5.671482 |
viability 115 7 5.648295 |
Figura 8: MI-score de las colocaciones de la palabra term (CobuildDirect).
Estos dos cálculos estadísticos están integrados en el programa diseńado para el estudio lexicográfico de las colocaciones desarrollado por Oxford University Press, denominado collocate, que además incluye la posibilidad de estudiar variaciones en las posiciones de los elementos de la colocación y permite estudiar el co-texto derecho o izquierdo de la colocación independientemente, posibilidad que no ofrecían los primeros índices de información mutua y t-score, ya que no proporcionaban información sobre la posición de los elementos de la colocación.
Otra de las áreas de aplicación lexicográfica del estudio de las colocaciones es la discriminación de significados (sense discrimination), es decir, el estudio de las diferentes acepciones de una palabra que deben incluirse en la entrada. Diferentes significados de una palabra suelen asociarse con colocaciones diferentes y con diversos patrones sintácticos. Baugh, Harley y Jellis (1996: 40), por ejemplo, destacan cómo el estudio de las colocaciones ayudó en el proceso de compilación del CIDE, tanto en el estudio del significado como en el de los patrones sintácticos asociados a los diferentes significados. Para estos autores, el corpus fue una herramienta fundamental a la hora de hacer distinciones de significados, y comparándolo con métodos tradicionales argumentan que "through using the corpus, CIDE lexicographers often found that previous dictionaries defined quite rare senses of words but missed important, common ones" (ibid.: 41).
Además del citado programa collocate, Clear (1994) muestra una herramienta computacional diseńada para discriminar los diferentes sentidos de una palabra usando listas de colocaciones extraídas de un corpus. Trabajando con una lista determinada de colocaciones de una palabra, esta herramienta procesa un número de líneas de concordancia, usando las colocaciones asociadas con un significado determinado como indicios (clues), y todas las demás colocaciones como contrarios (antis). Después, ańade información estadística sobre palabras que aparecen frecuentemente asociadas a las colocaciones (tanto las tomadas como indicios de un significado como las contrarias), de forma que agrupa las líneas de concordancia de acuerdo con la aparición (en un co-texto de 512 caracteres) de alguna de las colocaciones y sus palabras asociadas. Según se desprende de la discusión final de los resultados, esta metodología, aunque necesite ser refinada para conseguir resultados más acertados, posee una utilidad lexicográfica enorme, sobre todo en las fases de análisis de significado más avanzadas, ya que puede ofrecer al lexicógrafo las concordancias agrupadas de acuerdo con los diferentes significados de una palabra y facilitar, por ejemplo, la selección de un ejemplo de uso o el estudio de las restricciones de selección de una palabra.
Otro aspecto en el que los córpora poseen una gran utilidad lexicográfica es en la selección de los ejemplos que se han de incluir junto con las definiciones en las entradas. Los ejemplos son de vital importancia en el proceso de compilación de un diccionario, sobre todo en aquellos que están orientados al aprendizaje de una lengua extranjera, ya que pueden usarse para mostrar contextos típicos de uso, ilustrar restricciones de selección o características pragmáticas de una palabra para guiar a los usuarios, ofreciéndoles ejemplos similares a la frase que ellos intentan construir o entender. En muchos casos, los ejemplos no son tomados directamente del corpus, sino que el lexicógrafo los adapta, "inspirándose" o derivándolos de los que ha encontrado en el corpus, aunque no existe consenso sobre el grado en el que los 23
Notas
22 La noción misma de colocación ha sido entendida y definida de formas diferentes por diferentes autores. En términos generales, suele entenderse la coaparición (aparición simultánea) de dos o más palabras en un segmento de texto en el que la distancia entre los elementos de la colocación no sobrepase las cuatro o cinco palabras. Corpas Pastor (1996: 53) define las colocaciones como "unidades fraseológicas que, desde el punto de vista del sistema de la lengua, son sintagmas completamente libres [...] pero que al mismo tiempo, presentan cierto grado de restricción combinatoria determinada por el uso (cierta fijación interna)."
23 Por ejemplo, Fox (1987: 138), por una parte y Baugh, Harley y Jellis (1996: 43), por otra, argumentan de forma diferente en lo que respecta a la autenticidad de los ejemplos, defendiendo la autenticidad y no modificación de los ejemplos extraídos del corpus en el caso de la primera autora.
| ISSN: 1139-8736 Depósito Legal: B-39120-2002 Copyright: © Chantal Pérez |