IITLEX es un proyecto que se está llevando a cabo en la actualidad en el Instituto Tecnológico de Illinois en colaboración con la Universidad de Mississippi, cuyos orígenes se remontan a principios de los años ochenta. Nos detenemos a analizar este proyecto porque mantiene una serie de paralelismos con el nuestro, aunque también existen algunas diferencias.
El proyecto IITLEX se creó con la finalidad de desarrollar una base de datos léxica para ser utilizada en tareas genéricas de procesamiento de lenguaje natural. En la documentación referente al proyecto a la que hemos tenido acceso (Pin-Ngern Colon et al. 1994; IITLEX 1997) no se refleja tanto la información real que la base de datos contiene en este momento, como el tipo de información que sus autores consideran necesaria o pretenden incluir en un futuro. Por ejemplo, se dice que es su intención incluir información tanto de carácter enciclopédico como léxico. También, usando sus propias palabras, los autores apuntan a la posibilidad de "locate the whole semantic field of each entry by threading through the information available in the lexical and semantic relationships that we provide" (Pin-Ngern Colon et al. 1994:202), aunque no se especifica el modo en que este tipo de información será representada.
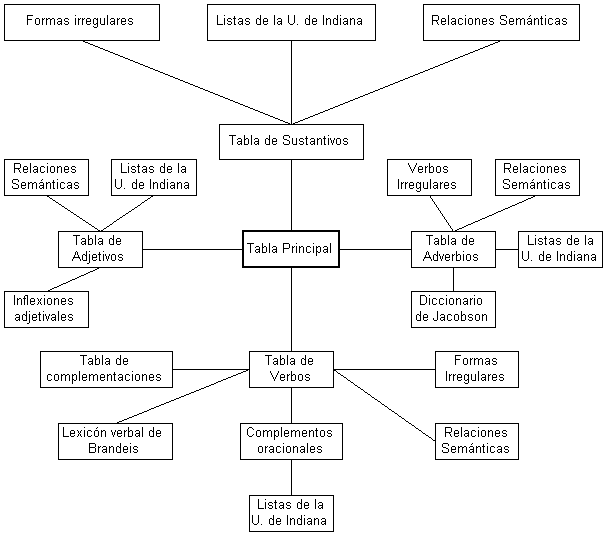
Este proyecto ha extraído la información léxica contenida en su base de datos de cuatro fuentes principales: El Collins English Dictionary (CED), unas listas de vocabulario procedentes de la Universidad de Indiana (que contienen información sintáctica y semántica referente a sustantivos, verbos, adjetivos y adverbios), la lista de verbos elaborada en la Universidad de Brandeis por Grimshaw y Jackendoff y, por último, el diccionario de Jacobson, que contiene información sobre las diferentes posiciones de los adverbios en la oración y su clasificación semántica (Pin-Ngern Colon et al. 1994).
IITLEX reconoce que toda esta información puede servir sólo como punto de partida para la organización de toda la información que debe contener un lexicón computacional orientado al procesamiento del lenguaje natural. Además de describir los múltiples problemas que han encontrado en el proceso de extracción de la información, los autores señalan que mucha de la información ha de ser adquirida por procesos manuales ya que no les ha sido posible extraerla por métodos automáticos.
La mayoría de los problemas que la extracción de información de sus fuentes electrónicas ha planteado están derivados de los aspectos que hemos señalado en el apartado 2.3, por lo que no nos detendremos en este aspecto del proyecto, aunque hay que señalar que estos problemas se han visto agravados por haber tenido que tratar con información procedente de cuatro fuentes diferentes, con cuatro procesos de compilación diferentes y cuatro formatos, en muchos casos diferentes, en otros casos incompatibles. El resultado ha sido un intenso trabajo manual que refleja, según pensamos, el deseo de sus creadores de crear un repositorio de información léxica de alta calidad.
Otra característica en común con nuestro proyecto es la implementación utilizando un sistema de representación de información no propietario, como es una base de datos relacional. En el apartado 4.2.3 describimos en detalle este modelo de datos, pero creemos necesario adelantar algunos conceptos básicos para poder mostrar la implementación del sistema IITLEX. Concretamente deberíamos entender las diferencias del concepto de "tabla" en general y en el ámbito de las bases de datos relacionales.
Genéricamente hablando, una tabla es una estructura de datos bidimensional. Se correspondería vagamente con una cuadrícula con un número de filas y columnas determinado, donde las filas reflejan un atributo y las columnas un valor, mediante las que se puede leer una estructura de datos simple del tipo atributo:valor. A los ficheros que contienen este tipo de estructura de datos se les suele denominar "ficheros planos" o "tablas planas" (debido a su naturaleza bidimensional).
Por otra parte, una tabla dentro de un esquema relacional puede ser considerada en los mismos términos, pero también es sinónimo de "relación" y en ese sentido se trata de una estructura de datos mucho más compleja, susceptible de ser manipulada mediante una serie de operaciones matemáticas bien definidas en el álgebra y el cálculo relacionales. Una relación es sinónimo de "conjunto", por lo que los elementos de una relación (las filas de la tabla) no están ordenados. Su identificación se realiza bien mediante un identificador único, en forma de clave primaria, ya sea ésta semántica o subrogada28.
En el proyecto IITLEX se utilizó inicialmente el sistema gestor de bases de datos relacionales OracleTM de Oracle Corporation. Sin embargo, aunque se pretende seguir utilizando este sistema, la inexistencia de un interfaz gráfico adecuado que facilitase las tareas de edición y consulta de datos a usuarios no expertos en el manejo del lenguaje de consulta29, hizo que sus creadores optasen por convertir las tablas de la base de datos original, generadas a partir de las fuentes que hemos mencionado, en tablas planas en formato texto. De este modo, facilitan el acceso a los datos a los lexicógrafos no cualificados para manejar este gestor de bases de datos.
Aunque consideramos que esta decisión es justificable, los problemas que se derivan, como sus propios autores reconocen, son múltiples. El problema fundamental es que tras la reconversión de las tablas planas a tablas relacionales se generarán sin duda un buen número de conflictos de integridad relacional. Un ejemplo simple es el caso extremo en el que un lexicógrafo defina un lexema que no existe en la tabla que contiene los lemas. Este tipo de problemas se evita de forma eficiente trabajando directamente con la base de datos, por medio de la aplicación de reglas de integridad referencial y la utilización de un interfaz gráfico adecuado. Como veremos en el Capítulo 5, nuestra implementación contempla todas estas funcionalidades.
En cuanto a la organización del lexicón, éste separa las entradas léxicas en cuatro partes de la oración: sustantivos, verbos, adjetivos y adverbios. Una tabla principal contiene los lemas (word entries) con códigos numéricos que identifican el significado, la parte de la oración y la información sobre los homófonos de cada entrada, que tiene a su vez un código de identificación único que se usa para consultar las entradas en cada una de las tablas dependientes de la principal y que sirve de índice.
La Figura 2.3, adaptada de (Pin-Ngern Colon et al. 1994), resume la organización de la información la base de datos IITLEX.
En el lexicón de sustantivos se especifica si un nombre es regular o irregular, singular o plural, abstracto o concreto, común, propio, colectivo, contable o incontable y humano, animado o inanimado. También se ha proyectado (aunque aún no ha sido incluido) indicar el género de los sustantivos para guiar posibles aplicaciones de NLP en el proceso de resolución de anáfora.
Se ha realizado un amplio estudio sobre nombres propios, dividiéndolos en categorías diferentes según pertenezcan al ámbito de la geografía, la onomástica, los nombres de organizaciones, etc.
En cuanto a los verbos, IITLEX los clasifica como regulares/irregulares, dinámicos/estáticos y transitivos/intransitivos. Estas clasificaciones han sido extraídas de los diccionarios, aunque información sintáctica más detallada, como la referida a los complementos oracionales o la pasivización ha tenido que ser incluida manualmente o aún está en proceso de inclusión.
La información sintáctica y semántica más compleja referida a los verbos está estructurada en los denominados "case frames", que contienen información sobre los argumentos que pueden aparecer en los diferentes significados de un verbo, así como las funciones semánticas asociadas a esos argumentos. Los nombres de los casos están tomados de Fillmore (1968).
Figura 2. 3 Organización de la base de datos léxica IITLEX
Un marco de casos de un verbo en IITLEX incluye la siguiente información:
Al igual que ocurre con la mayoría de los proyectos de investigación, este diseño inicial ha sufrido varias modificaciones, como por ejemplo la ampliación de las funciones sintácticas y de las restricciones de selección de los argumentos y se espera que el diseño sufra aun más modificaciones cuando se empiece a trabajar con los adjetivos y los adverbios.
Para resumir lo expuesto en este apartado, diremos que este proyecto tiene una concepción original muy similar a la nuestra y una ejecución adecuada, pero pensamos que su implementación podría ser mejorada con respecto a la creación de interfaces gráficos y restricciones de acceso a los datos que evitarían la necesidad de abandonar un entorno de trabajo fiable como el que ofrece el modelo de datos relacional.
NOTAS
Anterior I Siguiente I Índice capítulo 2 I Índice General