| ISSN: 1139-8736 Depósito Legal: B-8714-2001 |
5.0 Introducción
Ya hemos visto que uno de los módulos más importantes en un Sistema de Comprensión de Habla es el Módulo Acústico, cuya función es la de decodificar el mensaje hablado, es decir, reconocer la secuencia de palabras contenida en la frase hablada.
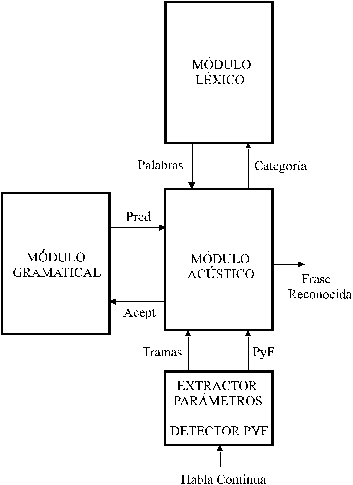
Fig.5.1 Diagrama de Bloques del Sistema de Reconocimiento de Habla Continua Modular
Esta secuencia de palabras será, en muchos sistemas, la entrada textual con errores del Módulo de Comprensión, que deberá ser lo suficientemente robusto para extraer la información semántica relevante a pesar de los errores, dentro lógicamente de las limitaciones impuestas por la ontología del dominio semántico restringido que se haya definido.
Hemos estudiado que existen 2 posibles arquitecturas básicas a la hora de diseñar un sistema de reconocimiento de habla continua: integrada y no integrada. La primera es más potente en cuanto a la incorporación de la información gramatical (léxica, sintáctica y semántica) en el proceso de decodificación del mensaje hablado, dando lugar a menores tasas de error. Sin embargo, son sistemas más caros en memoria y en coste computacional que los no integrados. A nosotros nos va a interesar diseñar e implementar un sistema de reconocimiento integrado pues necesitamos obtener las frases de salida con el menor número de errores posibles permitiendo al Módulo de Comprensión realizar su tarea sin excesiva dificultad.
Es importante plantearse cómo debe ser la arquitectura de un Sistema de Reconocimiento de Habla Continua, sobre todo si deseamos que sea flexible, es decir, capaz de incorporar gramáticas de distinta naturaleza (estocásticas del tipo N-gramas y formales como son las Libres de Contexto Probabilísticas), sin necesidad de rediseñar el sistema. Es necesario recordar que la incorporación del conocimiento gramatical guiando al proceso de decodificación acústica afecta al espacio de estados donde el algoritmo de Programación Dinámica utilizado debe encontrar una o varias soluciones. Un buen diseño debería permitirnos cambiar la gramática y el sistema debería ser capaz de generar el espacio de búsqueda correcto (en el que se puede encontrar la solución óptima), a partir de la misma. Además, debería ser posible trabajar con gramáticas que impongan las restricciones del lenguaje a nivel de categorías sintáctico-semánticas, pues ya vimos cómo éstas eran más fáciles de entrenar cuando los córpora de datos disponibles no eran suficientemente grandes. En este caso existirá un diccionario donde deberán estar las palabras a reconocer con la información de la categoría a la que pertenecen (diccionario categorizado). Debemos resaltar el hecho de que el espacio de estados también se verá afectado directamente, como ya se vió en los capítulos de introducción, por la estructura del diccionario, que podía adoptar 2 formas básicas: lineal y en árbol. Será interesante poder cambiar el diccionario sin necesidad de modificaciones en el sistema.
Pero no sólo los aspectos de la incorporación del conocimiento lingüístico deben ser considerados en el diseño de una arquitectura flexible sino también determinados aspectos acústicos como son: posibilidad de utilizar diferentes modelos HMM (discretos o DHMM, semicontinuos o SCHMM, continuos o CHMM), con múltiples parámetros (cepstrum, diferenciales de los cepstrum, prosódicos, etc), incorporación de mecanismos de reducción o poda del espacio de búsqueda (conocidos como beam-search en la literatura científica anglosajona), de generación u obtención de varias frases hipótesis de salida (N-caminos) (las mejores N hipótesis), gestión dinámica del espacio de estados (en base a un conjunto de listas y estructuras de datos que se actualizan trama a trama), etc. Además, el procesamiento de la información acústica recibida por el sistema debe poder ser procesada síncronamente, trama a trama, lo que permitirá, si la potencia del hardware es suficiente, la respuesta en tiempo real del mismo.
Teniendo en cuenta todos estos aspectos, se ha decidido implementar una arquitectura modular y flexible, basada en 3 módulos principales: Módulo Gramatical, Módulo Léxico y Módulo Acústico. En un principio, el diseño se realizó teniendo en cuenta la posibilidad de utilizar una arquitectura hardware multiprocesador, en la que cada módulo tuviese su procesador y su memoria dedicados, y pudiesen comunicarse asíncronamente entre ellos, enviándose la información necesaria cuando cada módulo lo decidiese. Sin embargo, las primeras experiencias demostraron que el flujo de datos era, en el fondo, un cuello de botella, perdiéndose demasiado tiempo en procesar las tramas o paquetes (estructuras de datos) que se intercambiaban entre ellos, y que para arquitecturas hardware monoprocesador (estación de trabajo, ordenador personal) de las utilizadas en nuestro caso, no suponía ninguna ventaja sino más bien inconvenientes debido al mayor coste en memoria y en cálculo. Debido a ello se optó por mantener la filosofía modular de la arquitectura pero compartimos estructuras de datos entre los distintos módulos para reducir el coste en memoria y ahorrar tiempo de proceso en el envío (preparación de los datos empaquetados en una estructura de datos que se transmite), recogida (lectura de la estructura de datos recibida) y procesamiento (distintas operaciones con los datos recogidos, antes de que puedan ser procesados por el módulo que los ha recibido) de los datos intercambiados por los módulos.
Se han realizado distintas implementaciones que nos han permitido analizar los pros y los contras de distintas soluciones: espacio de estados (de búsqueda) estático vs. espacio dinámico (listas actualizables), en el segundo caso es necesario utilizar una parámetro de aceptación que más tarde explicaremos, y que es equivalente al parámetro de poda ampliamente conocido (técnica de poda del haz o búsqueda en haz) y utilizado para ambos casos, generación de una solución (1 camino o solución óptima) comparado con N soluciones (1 óptima y N-1 subóptimas). El Módulo Gramatical ha sido diseñado de modo que puedan utilizarse distintos tipos de gramáticas estocásticas (N-gramas), desde un bigrama o un trigrama hasta un autómata (la N-grama de mayor N posible, las más restrictiva) de palabras o de categorías (sintácticas, semánticas).
A continuación describiremos cada uno de los módulos que forman parte de las arquitecturas implementadas, detallando las características fundamentales que nos ayudarán a entender la flexibilidad de los sistemas implementados. Sin embargo, es conveniente decir que, cuanto más flexible es un sistema menos eficiente es desde el punto de vista de memoria y de cálculo. A pesar de ello, creemos que se ha alcanzado un punto de equilibrio interesante, que no está exento, por supuesto, de mejoras u optimizaciones en el futuro. Debemos destacar el hecho de que todos los módulos han sido diseñados separando datos de procedimientos, lo que permite esa flexibilidad ya comentada.
Convenios Léxicos y Gramaticales
A partir de estos momentos utilizaremos una serie de convenios para nombrar a las gramáticas utilizadas en los experimentos de esta tesis:
D-x: para nombrar los diccionarios categorizados. El valor de x podrá ser B para referirnos al diccionario básico, de 982 palabras, original; S para referirnos a un diccionario que trata los nombres propios compuestos como si de varias palabras independientes se tratase, pero que tiene más entradas que el B pues hace uso de las reglas fonológicas descritas en el apartado 5.2.1 de este capítulo; C indicará que el diccionario tiene los nombres propios compuestos compilados en una sola palabra, sin incorporar la posibilidad de que exista una pausa entre las palabras del nombre compuesto, y que además, tiene en cuenta las reglas fonológicas; J sirve para nombrar un diccionario que trata los nombres propios compuestos como una sola palabra pero con la posibilidad de pausas entre las palabras del mismo y además tiene en cuenta las reglas fonológicas. En el apartado 5.2.2 encontraremos más información sobre los diccionarios y algunos resultados de reconocimiento.
GR160S-x: es el nombre de las gramática bigrama de 160 macrocategorías suavizada utilizada el método de “back-off” [KAT87], que será analizado en el apartado 5.1.3 de este capítulo, por eso aparece la S, y el valor de x podrá ser uno de los anteriores (B, S, C, o J), indicando el diccionario utilizado y la correspondiente implicación en la matriz de macrocategorías, que será entrenada a partir de diferentes corpus debido al modo de tratar los nombres propios compuestos y a las reglas fonológicas
Anterior I Siguiente I Índice capítulo 5 I Índice General
| ISSN: 1139-8736 Depósito Legal: B-8714-2001 |