Figura 38: Búsquedas combinadas como sondas de conocimiento.
| ISSN: 1139-8736 Depósito Legal: B-39120-2002 Copyright: © Chantal Pérez |
En nuestra búsqueda de la información necesaria para la estructuración del dominio de especialidad optamos por buscar en el corpus estructuras lingüísticas que nos dieran indicaciones sobre las partes del texto las que los autores incluían información sobre los conceptos relevantes al dominio y la forma en la que se relacionaban. Conocíamos el trabajo realizado por otros tres autores (Kavanagh 1995; Davidson 1998146 y Ahmad y Fulford 1992), en los que se estudian estructuras lingüísticas que representan relaciones semánticas y se exploran las posibilidades de extracción de información por medio de recuperación de contextos en los que aparezcan dichas estructuras.
A pesar de que dichos estudios resultaron muy reveladores para nuestros propósitos, las metodologías usadas por estos autores nos planteaban dos problemas fundamentales: el primero de ellos, ya mencionado, es el sentido en el que se plantea la recuperación de la información. En estos estudios se parte de un listado de estructuras lingüísticas que se identifican con determinadas relaciones semánticas. De esta forma, se identifica, casi siempre de forma biunívoca, una estructura lingüística con una relación semántica. Por ejemplo, las estructuras lingüísticas formadas por el verbo to be (ej. X is a Y) se toman como indicativas de una relación genérico/específico, y el éxito de la recuperación de contextos se mide con referencia al número de contextos en los que los autores han usado el verbo to be para expresar una relación de hiponimia, considerando los demás como ruido (contextos no válidos por no expresar dicha relación). Este tipo de planteamiento puede ser el acertado cuando el fin último es la automatización absoluta del proceso de extracción y adquisición del conocimiento. En este caso, sin embargo, la reducción del número de contextos que pueden considerarse como ruido exige el refinamiento de los patrones lingüísticos que se usan para extraerlos y ese refinamiento ha de pasar, necesariamente, por el estudio manual de los contextos. Conscientes de dicha dificultad, decidimos explorar el corpus en el sentido contrario, es decir, analizando las posibles relaciones semánticas que los autores comunican por medio de una determinada estructura lingüística.
El segundo problema metodológico que debimos plantearnos era la obtención de las estructuras lingüísticas que íbamos a usar como "sondas" de búsqueda de contextos conceptualmente ricos. En los trabajos anteriormente citados no se menciona expresamente la forma en la que los autores han obtenido dichas estructuras; sólo en el caso de Davidson (1998) la autora hace referencia a un estudio manual previo para extraer las estructuras lingüísticas. En nuestro caso, decidimos usar información que ya habíamos obtenido del corpus sobre las áreas conceptuales más relevantes del dominio de especialidad y sobre la forma en la que unas palabras clave se relacionan con otras en proximidad co-textual, por lo que tomamos los listados de palabras clave y de palabras clave enlazadas con otra palabra clave (§ 6.1.3, 6.1.4, 6.1.5) como primeras sondas de conocimiento y estudiamos la información que los contextos así extraídos nos ofrecían sobre el dominio de especialidad.
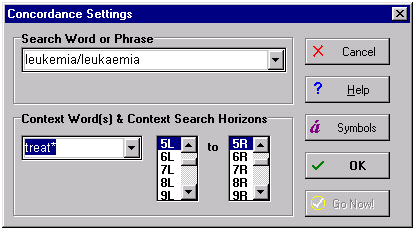
Para extraer los contextos, usamos la herramienta Concord, puesto que nos permitía recuperar las ocurrencias de una palabra o combinación de palabras que aparecen en combinación con otras, dentro de un determinado horizonte colocacional. De esta forma, tomamos una de las palabras clave como palabra de búsqueda y las palabras clave asociadas a ella como palabras que debían aparecer en un horizonte colocacional de 5/5 (cinco palabras a izquierda y derecha), tal y como muestra la siguiente captura de pantalla:
Según la cual obtendríamos las ocurrencias de las palabras clave leukemia/leukaemia en las que aparece junto a ellas, cinco posiciones a izquierda o derecha, algunas de las formas flexivas de "treat" (treatment, treat, treats, treatment, etc.).
En las secciones que siguen ejemplificaremos el tipo de contextos que pueden extraerse por este medio y la relevancia que tienen para la estructura conceptual del subdominio de la oncología. Ante la imposibilidad material de reproducir todas y cada una de las búsquedas realizadas y plasmarlas en papel, mostraremos algunas de las más relevantes, usando leukemia/leukaemia como palabra de búsqueda.
Notas
146 Tanto Kavanagh (1995) como Davidson (1998) usaron el ya mencionado TEXT ANALYZER en su estudio de relaciones semánticas, centrado básicamente en la hiponimia, la meronimia y la relación objeto-función.
| ISSN: 1139-8736 Depósito Legal: B-39120-2002 Copyright: © Chantal Pérez |