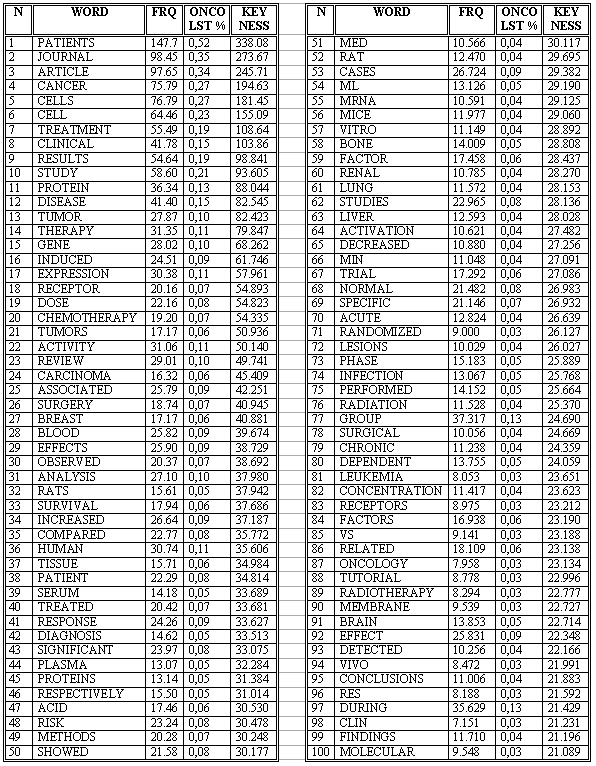
Tabla 4: Palabras clave en el corpus de oncología (comparándolo con el BNC)
| ISSN: 1139-8736 Depósito Legal: B-39120-2002 Copyright: © Chantal Pérez |
La segunda forma en la que estudiamos los elementos léxicos que integran nuestro corpus fue por medio del estudio de palabras clave (keywords). Dichas palabras clave las identificamos por medio de la comparación de patrones de frecuencia de aparición de una palabra en dos córpora: el de estudio (en nuestro caso, el corpus de oncología o el de leucemia) y el corpus de mayor tamańo que se toma como referencia (en nuestro caso, el British National Corpus).
Las palabras identificadas como clave no son necesariamente las más frecuentes en el corpus de estudio, sino aquellas que poseen una frecuencia significativa al compararla con la del corpus de referencia. Existen varios métodos más para determinar la relevancia estadística en la diferencia de frecuencia de aparición de un elemento léxico, de los cuales el chi-square test y el Log likelihood son los más usados. En nuestro caso, usamos este último, diseńado por Ted Dunning, e implementado en KeyWords135. De esta forma, pudimos identificar dos tipos de palabras clave: las positivas, es decir, aquellas que ocurren con una frecuencia mayor de la que se podría considerar aleatoria al comparar la frecuencia de aparición de una palabra en el corpus de estudio con el de referencia y las negativas, es decir, las que ocurren con una frecuencia menor a la que se podría esperar al comparar ambos córpora.
Las palabras clave que selecciona el procedimiento de comparación de ambos córpora sirven para dar una buena indicación de la temática de los textos, por lo que pensamos que nos pueden ser útiles para delimitar áreas conceptuales importantes en el ámbito de especialidad. Al procesar nuestros dos córpora de estudio, el de oncología y el de leucemia y compararlos entre ellos y con el de referencia, obtuvimos una media de 500 palabras clave, de las que, para facilitar la lectura, reproducimos sólo las 100 primeras en la Tabla 4, Tabla 5 y Tabla 6 respectivamente y resumimos a continuación los resultados más significativos.
Lo primero que salta a la vista en la Tabla 4 es que las 12 primeras corresponden a las más frecuentes del corpus que mostramos en la Tabla 2 (con ligeras variaciones en el orden de frecuencia). Esto nos indica que dichas palabras (patients, journal, article, cancer, cells, cell, treatment, clinical, results, study, protein, disease y tumor) son relevantes, no sólo en términos de frecuencia absoluta, sino también al comparar su frecuencia en el corpus de oncología con la frecuencia que poseen en el corpus de referencia. Vemos que otras palabras también aparecen en ambas tablas (chemotherapy, carcinoma, induced, etc.), pero ahora lo hacen en posiciones mucho más altas.
Estas cien primeras palabras clave del corpus de oncología, junto con el estudio de su uso mediante el análisis de concordancias, pueden darnos una indicación de las áreas temáticas más importantes y reiteradas de los textos incluidos en el corpus de oncología. Sin embargo, al intentar agrupar las palabras incluidas en la Tabla 4 en grupos de afinidad semántica, considerando, por tanto, los conceptos que dichas palabras designan, éstas muestran que, en realidad, los textos son bastante heterogéneos136 y, en consecuencia, los grupos semánticos son muy generales y por tanto indican categorías conceptuales muy amplias comunes a todos ellos:
Además de estos grupos semánticos, volvemos a encontramos con tres casos de formas abreviadas cuya frecuencia las hace palabras clave:
Estos grupos semánticos pueden ayudar al terminógrafo a empezar a perfilar la estructura conceptual del dominio de la oncología. Sin embargo, somos conscientes de la complejidad de dicho dominio y de los múltiples aspectos y dimensiones que activa, cuya representación sobrepasa el alcance de nuestro trabajo y es la misión del equipo de investigadores que integran el proyecto OncoTerm. Por tanto, una vez que obtuvimos información genérica sobre el cáncer, decidimos acotar nuestra búsqueda de información en el corpus a un subdominio del cáncer, el de la leucemia, por lo que procesamos las palabras clave de un conjunto de textos que versan sobre dicha enfermedad y su tratamiento, comparándolos primero con nuestro corpus de referencia (el BNC) y después con los demás textos sobre oncología. Las Tabla 5 muestra las 100 primeras palabras claves obtenidas al comparar el corpus de leucemia con el BNC y la Tabla 6 las 100 primeras palabras claves del corpus de leucemia usando el corpus de oncología como referencia.
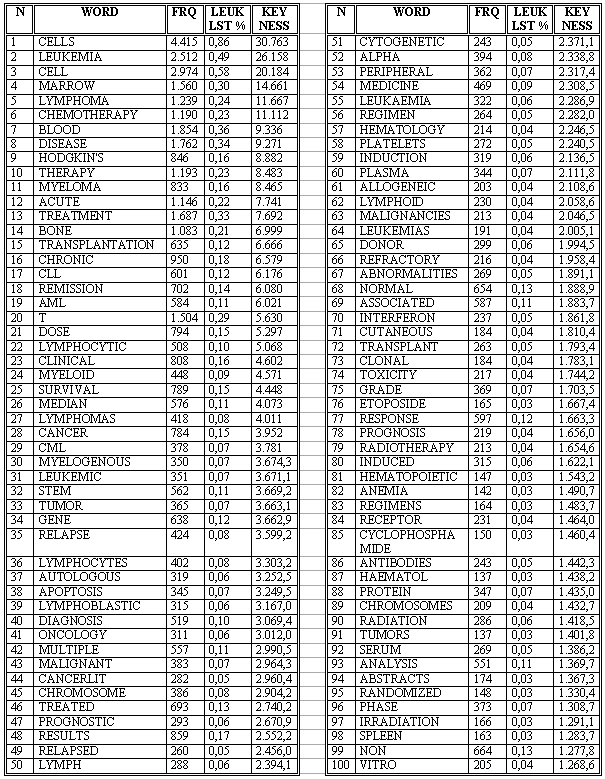
Si estudiamos con atención las palabras clave del corpus de leucemia que mostramos en la Tabla 5, vemos que resultan tremendamente informativas de los conceptos básicos implicados en la enfermedad y en su tratamiento. Como consecuencia de la homogeneidad temática de los textos, las palabras que integran los conjuntos semánticos en que se pueden agrupar las palabras de dicha lista son mucho más compactos que los que obtuvimos en el corpus de oncología y resultan, por tanto, mucho más útiles en el trazado de la estructura conceptual del subdominio:
Esta información sobre los grupos semánticos del subdominio de la leucemia puede completarse si, en vez de comparar nuestro subcorpus de leucemia con uno de propósito general, lo comparamos con el corpus de oncología, el cual a pesar de ser de carácter especializado es mucho más heterogéneo en cuanto a la temática de los textos. La combinación de ambas comparaciones nos resultó muy útil por dos razones: la reiteración de determinadas palabras clave nos confirmó que son conceptos importantes en el ámbito específico de la leucemia, aunque en algunos casos aparecen en posiciones ligeramente diferentes; además, nos mostró otras palabras clave, sobre todo compuestos químicos y siglas especializadas, que no habían sido identificadas antes.
La Tabla 6 muestra dichas palabras, y a continuación seńalamos las palabras clave en su correspondiente grupo semántico, sin repetir las que ya habían aparecido en la Tabla 5, para mostrar más claramente la información que ańade la comparación de los dos córpora especializados con diferente temática y homogeneidad textual.
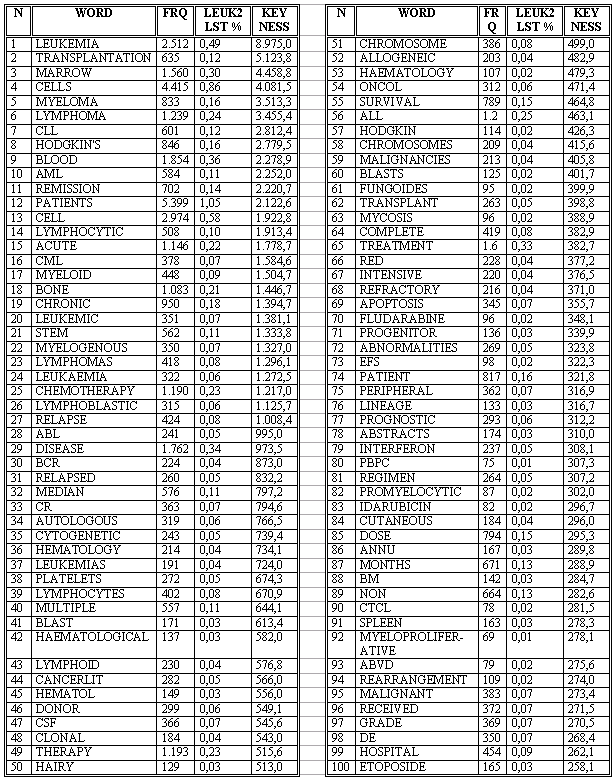
Los grupos semánticos en los que estas palabras clave pueden agruparse son los siguientes:
Además de las que hemos mostrado en las tablas anteriores, las palabras clave que se encuentran en posiciones inferiores también resultaron de gran utilidad en la estructuración del dominio conceptual de la leucemia. Entre las 50 siguientes de la Tabla 6 encontramos, por poner algunos ejemplos, nombres de compuestos químicos y fármacos usados en el tratamiento (como la sigla MOPP, que corresponde a mechlorethamine, oncovin, procarbazine y prednisone; vincristine y arabinoside), síntomas de la enfermedad como la anemia, patologías y disfunciones asociadas a la leucemia como la thrombocytosis, myelofibrosis y polycytemia, tipos de células cuyo funcionamiento es fundamental para entender el desarrollo de la enfermedad, como son neutrophil y basophil, procesos sanguíneos que tienen lugar natural (hematopoiesis) o artificialmente (apheresis), etc.
El estudio de las palabras clave de nuestros dos córpora nos ha servido para ver las principales áreas conceptuales que debe cubrir una representación de los conceptos implicados en el subdominio de la leucemia. Sin embargo, los listados de palabras clave no nos ofrecen ninguna información sobre las relaciones de dichos conceptos ni sobre su posición en la estructura conceptual. En las secciones que siguen mostramos cómo puede obtenerse este tipo de información estudiando de forma individual las ocurrencias de cada una de estas palabras clave y sus relaciones con otras palabras clave del corpus.
Notas
135 Oakes (1998) ofrece una descripción detallada y las fórmulas que se usan en ambos cálculos estadísticos.
136 Con esto queremos decir que en el corpus de oncología los textos varían en cuanto al tipo de cáncer del que tratan (cáncer de pulmón, de mama, etc) y a la perspectiva desde la que lo tratan (tratamiento, muestra de resultados de ensayos clínicos, exposición pedagógica de los signos y síntomas, etc.).
137 Especificamos en el grupo semántico que hemos denominado propiedades los dos tipos atributos y relaciones porque ésta es la forma en la que las propiedades se representan en nuestra ontología.
138 Incluimos vivo y vitro en el grupo de propiedades, puesto que en el corpus sólo aparecen en las expresiones latinas in/ex vivo e in vitro, con dos funciones sintácticas fundamentales: modificando la acción verbal (demonstrated in vivo, maintained in vitro) o premodificando a un repertorio bastante cerrado de nombres o grupos nominales: ex vivo activation, ex vivo activity, ex vivo analysis, ex vivo assays, ex vivo techniques, ex vivo expansions, ex vivo gene therapy; in vivo activity, in vivo administration of X, in vivo analysis, in vivo behaviour, in vivo conditions, in vivo depletion, in vivo effects, in vivo evidence, in vivo evaluation, in vivo experiment, in vivo gene therapy, in vivo gene transfer; in vitro model, in vitro drug sensitivity testing, in vitro toxicology, in vitro cultivation, in vitro experiments, in vitro studies, in vitro testing.
139 Las formas abreviadas de los nombres de revistas separadas por guiones corresponden a las convenciones tipográficas de una de las fuentes del corpus, el MEDLINE.
140 Multiple también aparece en el corpus como cuantificador de carácter general en secuencias tales como multiple doses, multiple factors, multiple births, multiple sources y en el nombre de otro tipo de cáncer: Multiple Endocrine Neoplasia (MEN).
141 Incluimos induction en este grupo porque, además de su significado más general de "causar un proceso" aparece muy frecuentemente en nuestros textos premodificando a varios tipos de tratamiento (ej. induction chemotherapy, induction chemoradiation o induction chemoratiotherapy).
142 Aunque en los textos de leucemia la sigla BM corresponde únicamente a bone marrow, en el corpus de oncología esta sigla es polisémica, puesto que puede sustituir también a basilar membrane, bowel movement y basement membrane.
143 La sigla CSF aparece, además, en nuestro corpus de leucemia especificada en las combinaciones siguientes: G-CSF (granulocyte colony stimulating factor), GM-CSF (granulocyte-macrophage/granulocyte-monocyte colony stimulating factor) y rhG-CSF (recombinant human granulocyte colony stimulating factor).
| ISSN: 1139-8736 Depósito Legal: B-39120-2002 Copyright: © Chantal Pérez |