Figura 33: El Termbase Editor de OntoTerm
| ISSN: 1139-8736 Depósito Legal: B-39120-2002 Copyright: © Chantal Pérez |
El editor de base de datos terminológica (Termbase Editor) de OntoTerm es el módulo que complementa al ya expuesto Ontology Editor (§ 5.4). En el Termbase Editor el terminólogo lleva cabo la tarea de describir las categorías lingüísticas, de uso y administrativas de los términos.
Puesto que OntoTerm es un sistema basado en conceptos, no es posible introducir un término en la base de datos sin que asignarlo previamente a un concepto que con anterioridad ha tenido que ser definido conceptualmente en el editor de ontologías (véase sección 5.4). Por tanto, este sistema impone una metodología de trabajo acorde con la orientación conceptual del trabajo terminológico y al mismo tiempo permite una división del trabajo clara en equipos de terminógrafos.
Al igual que en el Ontology Editor, una nueva base de datos terminológica se crea simplemente dando un nombre de fichero y un nombre lógico. En el momento de su creación, la ontología que esté abierta en el Ontology Editor será considerada la "ontología de trabajo" de la nueva base de datos y los conceptos serán copiados a la nueva base de datos. A partir de este momento, todos los cambios realizados en la ontología de trabajo quedarán automáticamente reflejados en la lista espejo que contienen todas las bases de datos que la tengan como tal. No existe ningún límite en cuanto al número de bases de datos terminológicas que pueden estar asignadas a una ontología en concreto. La ontología contiene un listado de las mismas y, en caso de faltar alguna de ellas en el momento de cualquier actualización (porque el usuario la ha eliminado), se mostrará un mensaje de error y se eliminará este enlace. Del mismo modo, una base de datos terminológica previamente creada no se podrá abrir si su ontología de trabajo no es la que se encuentra abierta en ese momento.
Esto implica que el Termbase Editor está subordinado al Ontology Editor, que en todo momento deberá permanecer activado (con la ontología de trabajo en cuestión) durante el proceso de edición o navegación una de sus bases de datos terminológicas. Esto implica que no se puede abrir más de una base de datos terminológica aunque estén asignadas a la misma ontología de trabajo. Sin embargo, es posible ejecutar múltiples instancias del Ontology Editor, abriendo la misma ontología, es decir, OntoTerm permite el acceso concurrente a sus bases de datos, de modo que esto no es realmente una limitación.
El esquema conceptual de las bases de datos que genera el Termbase Editor está basado en la especificación Reltef? (Hardman 2000), el cual ha sido adaptado para conseguir mayor velocidad de acceso mediante el uso de claves indizadas numéricas y algunas otras mejoras. Como ya hemos mencionado, implementa las categorías de datos detalladas en el apartado anterior.
La implementación de estos estándares se ha enfocado a facilitar su utilización por parte del terminógrafo, a quien se pretende aislar de la complejidad interna del modelo de datos que se está empleando. Esto lo consigue OntoTerm mediante una interfaz de usuario innovadora, que poco tiene que ver con las fichas terminológicas que suelen emplear los sistemas de bases de datos a los que estamos acostumbrados. Todas las categorías de datos se encuentran disponibles, pero es el usuario quien decide cuándo utilizarlas, siempre y cuando el sistema se lo permita (según sean combinaciones de categorías o tipos de datos permitidas o no en el CLS Framework). Al igual que en el Ontology Editor, el usuario es el que decide la complejidad de sus entradas terminológicas, la aplicación se limita a ofrecer las posibilidades y bloquear las incoherencias o instancias no permitidas.
En nuestra experiencia, la utilización de OntoTerm se ha revelado como una aplicación enormemente didáctica, ya que no es necesario poseer más que un conocimiento superficial de las categorías de datos para empezar a trabajar. Puesto que la aplicación nos impide cometer errores en cuanto al uso de las mismas, se nos da la facilidad de experimentar con las posibilidades que se nos ofrecen, de modo que poco a poco se hace evidente la enorme flexibilidad que el CLS Framework permite.
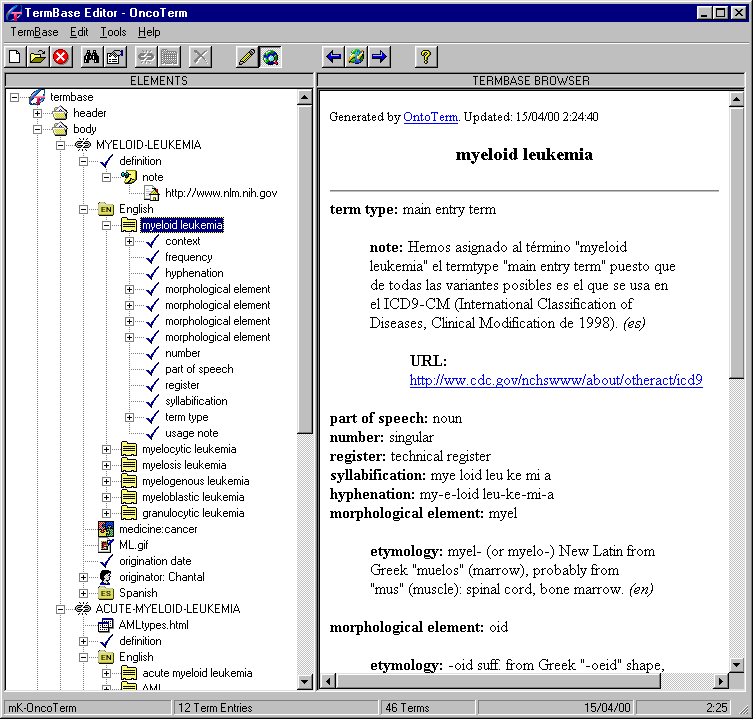
Para conseguir esto, la interfaz del Termbase Editor se basa en dos árboles y un marco de edición. Prácticamente todas las operaciones de edición y navegación se realizan en esta misma ventana, que mostramos en la Figura 33.
Figura 33: El Termbase Editor de OntoTerm
El árbol de la izquierda refleja de forma gráfica la estructura jerárquica que subyace a toda base de datos terminológica que siga el CLS Framework. Según vimos en el apartado 5.5.2, una base de datos consta de un encabezado, un cuerpo y la información compartida. El grueso de la información terminológica se encuentra en el cuerpo de la base de datos, que engloba las denominadas entradas terminológicas. A éstas se les asignan los términos, que se agrupan en los denominados langsets, así como otros elementos de información. Lo realmente interesante de este sistema es que absolutamente todos estos elementos, al igual que cada uno de los atributos que se asignan a cualquier elemento gozan del mismo estatus por lo que se refiere al modelo de datos. Internamente, una base de datos basada en el modelo propuesto por el CLS Framework almacena del mismo modo todos estos elementos y se les asigna un tipo que es el que realmente les caracteriza.
La razón de esto es que de este modo podemos hacer que una categoría de datos determinada se pueda caracterizar mediante un subconjunto de categorías de datos determinado, que incluso puede contener un atributo igual (por ejemplo, una nota se puede describir mediante otra nota). En este principio se basa el funcionamiento básico del gestor de base de datos de OntoTerm: validar o bloquear determinadas categorías para determinadas categorías. Esto lo hace de una forma totalmente gráfica: al hacer clic sobre cualquiera de los elementos que conforman el árbol de la base de datos (el izquierdo), el árbol derecho muestra las categorías de datos válidas para el elemento seleccionado mediante el icono con la flecha azul y bloquea las no válidas mediante una cruz roja.
De esta manera podemos asignar atributos (es decir, describir) no sólo a conceptos y términos, sino también a los propios atributos. Por ejemplo, podemos asignar a la definición de un término la fuente bibliográfica de donde se ha extraído y, a su vez, describir ésta mediante un hipervínculo a una sede web determinada a la que, a su vez, le podemos asignar un código de fiabilidad bajo, indicando que no estamos seguros de esta información. En definitiva, la herramienta nos permite incluir información tan explícita o genérica como deseemos para un elemento en cuestión, sin necesidad de asignar las mismas categorías a todos los elementos de un mismo tipo.
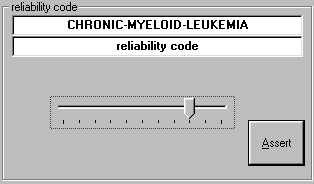
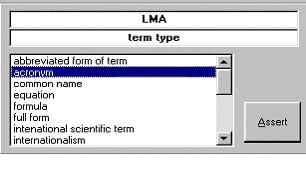
Hemos mencionado que el editor se compone de estos dos árboles y el marco de edición. Sin embargo, como se puede observar en la Figura 33, éste último no se puede apreciar. En realidad, éste sólo aparece cuando hacemos clic en una de las categorías de datos (válida) del árbol derecho. En ese momento le damos a entender que deseamos ańadir o editar un valor para el elemento que hemos seleccionado y OntoTerm muestra el marco de edición en la parte inferior del árbol izquierdo con un control apropiado según el tipo de datos de que se trate, ya sea una caja de texto para la inclusión de texto libre, una lista de la que escoger valores, un deslizador para valores en un rango numérico o un cuadro de texto con máscara para fechas (ver Figura 34).
 |
 |
El mismo marco sirve tanto para ańadir un atributo determinado como para editarlo una vez ha sido ańadido, la única diferencia es que en el segundo caso, el botón de confirmación mostrará "OK" en lugar de "Assert".
En lugar de ofrecer un listado de campos, OntoTerm muestra las categorías de datos de forma gráfica, facilitando la localización de los mismo mediante iconos descriptivos del tipo de categoría. La inserción de remisiones o referencias cruzadas se realiza también de forma totalmente gráfica: en primer lugar seleccionamos el elemento que contendrá la referencia, después hacemos clic en la categoría de datos que implique la remisión, que puede ser bien una referencia genérica a la que deberemos dar una etiqueta (por ejemplo, "véase") o bien una categoría de datos que requiere otro elemento de la base de datos (por ejemplo un homógrafo o un false friend). En ese momento OntoTerm nos informa de que debemos seleccionar el elemento al que se remite, solicita una etiqueta en caso de ser necesaria, cambia el puntero del ratón a una flecha con interrogación y espera a que pulsemos sobre el elemento al que queremos hacer referencia. Las remisiones son mostradas mediante un icono con dos anillos y la etiqueta que los describe. Para saber a qué elemento se hace referencia deberemos usar el menú contextual (ver Figura 35).
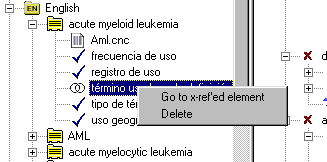
Figura 35: Gestión de remisiones en OntoTerm
Hasta aquí hemos mostrado el modo en que creamos y editamos una base de datos terminológica en OntoTerm. Sin embargo, las características de navegación no se limitan al árbol de la base de datos, sino que las entradas terminológicas también pueden ser visualizadas en modo de navegación. Al pasar al modo de navegación, el panel derecho se convierte en un navegador web en el cual OntoTerm visualiza un documento HTML que genera sobre la marcha en caso de no haber sido generado previamente, para el concepto sobre el que se haga clic en el árbol de la base de datos. Esto nos permite una lectura y visualización rápida de toda la información que hayamos asignado a la entrada terminológica en cuestión. Las imágenes u otros elementos multimedia (sonido, vídeo, etc.) también se visualizarán en este navegador (véase Figura 36).
Como se puede observar en esta captura de pantalla, OntoTerm convierte las referencias a otras entradas terminológicas en hipervínculos, lo que nos permite, por ejemplo navegar libremente entre las mismas, por ejemplo, siguiendo remisiones.
Figura 36: Ejemplo de visualización en el navegador de OntoTerm
OntoTerm guarda todas estos documentos HTML en un directorio especial que la aplicación genera durante el proceso de instalación, de modo que podemos utilizar cualquier navegador web para visualizarlos, modificarlos, etc. En realidad, no es necesario generar las páginas una a una, ya que, al igual que el Ontology Editor, el Termbase Editor tiene un generador de informes (véase sección 5.4, Figura 26) que permite generar masivamente todas las entradas terminológicas de nuestra base de datos, o bien una parte de ellas, en una localización determinada. Los informes generados de esta forma pueden contener toda la información incluida en la base de datos terminológica para un concepto determinado (por ejemplo todos los términos que designan dicho concepto en las lenguas de trabajo) o, si se prefiere, se puede generar sólo la información pertinente a un término. En estas páginas, además, puede incluirse también la información conceptual del Ontology Editor, de forma que en una sola página puedan verse ambos tipos de información y, por tanto, navegar en modo de hipertexto por las páginas generadas correspondientes a los conceptos o los términos. En los apéndices incluimos ejemplos de documentos HTML generados por el navegador para algunos conceptos y/o términos de la base de datos terminológica.
| ISSN: 1139-8736 Depósito Legal: B-39120-2002 Copyright: © Chantal Pérez |