Figura 27: Resumen de la estructura de base de datos en el CLS Framework
| ISSN: 1139-8736 Depósito Legal: B-39120-2002 Copyright: © Chantal Pérez |
Con independencia del formato que se elija para representar la información terminológica, (una base de datos relacional, un texto estructurado con códigos SGML, un programa de gestión terminológica, etc.), es de vital importancia establecer de forma explícita un modelo de datos para todos los tipos de información terminológica (Higgins & Ahmad 1996: 215-224). Como hemos seńalado en el apartado 5.2, la norma ISO 12620 ofrece un inventario completo de categorías de datos. Según esta norma, una entrada terminológico-conceptual (denominadas en inglés terminological concept entry o term entry, en forma abreviada) está compuesta por una serie de campos de datos y cada uno de estos elementos o campos conforma una categoría de datos. Lo que la norma ISO 12620 no especifica es la estructura de la entrada terminológico-conceptual, es decir, no indica de forma explícita las relaciones que existen (o deben existir) entre las distintas categorías de datos dentro de una entrada.
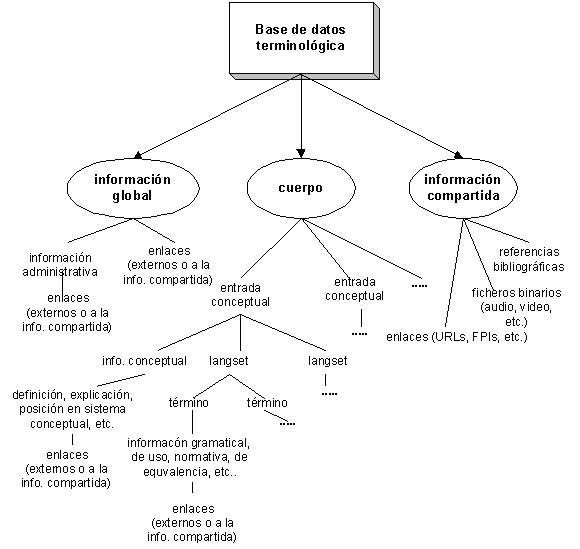
Precisamente ésta es una de las propuestas que el CLS Framework está desarrollando en la actualidad. En ella, se propone una forma de estructurar los elementos que se integran en una entrada terminológica de modo que dicha estructuración esté en consonancia con los fundamentos generales de la teoría terminológica (se parte del concepto para llegar a la denominación). Las siglas elegidas para denominar al grupo de trabajo hacen referencia explícita al enfoque propuesto para la estructuración de una base de datos terminológica: Concept-oriented with Links and Shared references -una estructuración basada en los conceptos, con enlaces y referencias compartidas. Por tanto, según el CLS Framework una base de datos terminológica se estructura en tres partes fundamentales:107
La información global puede incluir detalles sobre el nombre de la base de datos, versión, derechos de autor y creadores de la base de datos. Puede además incluir información sobre las lenguas y los alfabetos usados en la base de datos, el grupo de usuarios potencial de la información contenida u otra información administrativa o de gestión.
El segundo de los grupos, las entradas terminológico-conceptuales, también denominado cuerpo (body), está compuesto por los conceptos en un campo de especialidad y los términos que les son asignados como designación específica en una o varias lenguas. A cada uno de estos términos se le asigna, a su vez, una serie de informaciones específicas (descriptivas, administrativas, lingüísticas, de uso, etc.).
En consonancia con los principios de la teoría terminológica tradicional, la situación ideal en este tipo de estructuración de base de datos (y de cualquier otra, deberíamos ańadir) se da cuando todos los términos (en una o varias lenguas) contenidos en una entrada terminológico-conceptual designan el mismo concepto. De este modo, en cada entrada, los términos de una misma lengua se agrupan y forman los denominados langsets, por lo que determinadas categorías de datos pueden también asignarse al langset completo (autor de las entradas, fecha, fuentes bibliográficas, notas, etc.).
Sin embargo, es posible que el terminólogo tenga que hacer frente a situaciones en las que la equivalencia interlingüística (equivalencia entre términos de diferentes langsets) o intralingüística (sinonimia entre términos de un mismo langset) no sean perfectas. En estos casos, puede ańadirse un comentario sobre transferencia (transfer comment), es decir, una observación que indique el grado de equivalencia de los términos. En otros casos, el grado de no-equivalencia puede ser mayor, por lo que el terminólogo deberá decidir si es necesario definir dos conceptos diferentes y crear por tanto dos entradas terminológicas independientes.
La tercera parte de la base de datos se compone de una serie de enlaces (links) que relacionan unas entradas (o elementos de una entrada) con otras entradas o elementos de otras entradas, o bien con un conjunto de referencias que se consideran compartidas, ya que pueden asignarse a varios elementos (entradas o partes de ellas) de la base de datos (SharedRefs). Una entrada bibliográfica completa, información sobre el autor de la entrada o la fecha de redacción se considera información compartida, ya que es probable que se asignen a varias entradas o elementos de una entrada. Otro tipo de información compartida la constituyen los gráficos, tablas, imágenes y archivos de sonido, etc.
El lugar donde estas referencias compartidas se almacenan reciben el nombre de back matter. En el back matter también se incluyen otros tipos de referencias que pueden compartir varias entradas o partes de una entrada: enlaces (links) a elementos externos a la base de datos, como puede ser la dirección que identifica un documento o una página personal en la web.
La utilidad de este tipo de estructuración de base de datos es clara: evita que incluya información redundante, un principio fundamental en la gestión de bases de datos. Si, por ejemplo, una referencia bibliográfica o cualquier otro tipo de información compartida se incluye sólo una vez en la base de datos y varias entradas la incluyen, no físicamente, sino como un enlace, no sólo se evita la redundancia, sino que además supone un importante ahorro en cuanto a la cantidad de información que se guarda. Otra ventaja de este tipo de estructuración es que facilita la consistencia y la coherencia de la información, por lo que evita errores o variaciones posibles al incluir información repetida y hace mucho más fácil corregir o actualizar la información que se repite en una base de datos, asegurando que la corrección se hace en todos los lugares en los que esa información aparece.
Las categorías de datos contempladas por la norma ISO 12620 que se agrupan en estos tres grandes bloques (información global, cuerpo terminológico y referencias compartidas) poseen, además, otras dos características implícitas: el tipo de datos que puede incluirse en un campo determinado (numérico, alfanumérico, textual) y la lengua en la que debe consignarse, en caso de ser un campo textual. En otros casos, el valor de una categoría de datos puede estar restringido a uno o más de una lista de opciones permitidas (pick lists): por ejemplo, en la categoría género gramatical las opciones permitidas pueden ser cuatro: masculino, femenino, neutro y otro.
Esta estructuración de base de datos puede representarse gráficamente (de forma muy simplificada) con el siguiente esquema:
Notas
107 En la explicación de la estructuración de una base de datos terminológica que sigue, así como en la descripción de las categorías de datos propuestas por el comité técnico 37 de la ISO y tomadas por el CLS Framework, hemos traducido los términos específicos usados para facilitar la lectura del texto en espańol. Sin embargo, dado que estas traducciones son bastante directas y han de considerarse totalmente "ad hoc", hemos incluido en muchas ocasiones también los nombres de las categorías propuestos originalmente en lengua inglesa entre paréntesis y en cursiva.
| ISSN: 1139-8736 Depósito Legal: B-39120-2002 Copyright: © Chantal Pérez |