
Figura 2. Tabla con información de forma
| Estudios de Lingüística del Español (ELiEs) |
| Los Diccionarios Electrónicos: hacia un nuevo concepto de diccionario / Ana Fernández-Pampillón Cesteros y María Matesanz del Barrio |
2.3 Modelos de datos para la organización de la información léxica de los diccionarios electrónicos
Los diccionarios impresos presentan una estructura o modelo de organización de la información muy diferente de los diccionarios en formato electrónico. El diccionario impreso organiza la información léxica en una lista de entradas léxicas, sin demasiadas relaciones explícitas entre ellas. Cada entrada se organiza con un esquema jerárquico, denominado microestructura, distinta en cada diccionario. Esta organización no es completa, ya que el texto en de los niveles finales del árbol (nodos “hoja”) no está, en general, estructurado. Así, no existe un modelo común o regular al que se ajusten todos los artículos.
Con esta organización, los usuarios de los diccionarios impresos son capaces de interpretar los datos (el texto), y obtener la información asociada a dichos datos. Por ejemplo, el usuario es capaz de deducir, a partir de las definiciones de una palabra, las distintas relaciones semánticas entre los conceptos (representados con las palabras) que aparecen en las definiciones de un concepto definido: relaciones de generalización/especialización (hiperonimia/hiponimia), o de sinonimia entre otras.
Los modelos computacionales para la organización de la información son modelos de datos para representar, estructurar, relacionar y almacenar adecuadamente la información en formato electrónico, con el objetivo de poder gestionarla14 automáticamente. En el caso de los diccionarios electrónicos, los modelos de datos más utilizados son el modelo relacional de bases de datos y el modelo hipertexto.
El modelo relacional de bases de datos organiza la información en un conjunto de estructuras planas denominadas relaciones15. Estas relaciones se pueden representar como tablas, donde cada fila es una entidad u objeto y cada columna de la tabla son los distintos valores que tienen los objetos para una misma propiedad o atributo (figura 2). Este modelo de datos tiene, además, definido un conjunto de operaciones16, el álgebra relacional, y un lenguaje declarativo estándar, SQL, para la creación, consulta, y modificación de las bases de datos (Ullman,1988).
El modelo relacional está apoyado por la existencia, en el mercado, de una amplia variedad de software para la gestión de bases de datos relacionales, los Sistemas Gestores de Bases de Datos (SGBD) relacionales. Estas aplicaciones son muy potentes, sencillas de utilizar y, en algunos casos, de libre distribución17. Permiten gestionar automáticamente toda la información de la base de datos, de forma gráfica, con asistentes o utilizando el lenguaje SQL.
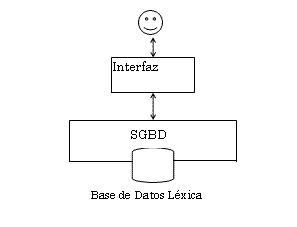
Muchos de los diccionarios electrónicos actuales están basados en una base de datos relacional, donde se almacena toda la información léxica. La gestión de los datos se realiza mediante un SGBD, a través de un programa de aplicación que constituye la interfaz con el usuario. Esta interfaz gráfica recibe las consultas de los usuarios y las envía al SGBD, que accede a la base de datos, extrae los resultados de la consulta y se los devuelve a la interfaz que los presenta al usuario (figura 3). Para esta presentación, curiosamente, se utiliza otro tipo de organización de la información: el hipertexto.
Otros diccionarios electrónicos utilizan aproximaciones mucho más simples desde el punto de vista computacional. La información se organiza en simples archivos de registros18, donde cada registro almacena un artículo del diccionario. Estos archivos son gestionados por aplicaciones software de propósito específico. Este tipo de organizaciones tiene importantes desventajas que no analizaremos en este capítulo19, pero que podemos resumir en que son difíciles y costosas de actualizar y de mantener.
El hipertexto (texto no lineal) es un modelo de representación de información (normalmente de tipo textual) en el que los datos se organizan en una red de nodos conectados mediante enlaces. Esta organización permite estructurar y representar la información de forma asociativa, imitando el modelo de organización del conocimiento del cerebro humano (Conkling, 1987). En esencia, la información se almacena en nodos, que pueden estar, a su vez, compuestos de otros nodos o, simplemente, contener valores o unidades de información simple. Los nodos están relacionados entre sí mediante enlaces que pueden estar etiquetados con el tipo de asociación que representan. Los nodos pueden estar en una misma máquina (enlaces locales) o en máquinas diferentes (hiperenlaces), posiblemente muy alejadas unas de otras. La estructura resultante es una red que puede ser de grandes dimensiones, muy compleja e, incluso, estar distribuida por todo el mundo.
Los objetivos básicos del modelo hipertexto son (a) representar con más exactitud dominios de conocimiento que contienen gran cantidad de relaciones, y (b) hacer más sencillo e intuitivo el acceso a dicho conocimiento (Balasubramanian, 1994). El hecho de que estos objetivos se ajusten perfectamente a las necesidades de los diccionarios electrónicos, unido al hecho de tener un desarrollo tecnológico suficiente para poder utilizarlo, han hecho posible la aparición3 de diccionarios (sobre todo en Internet) basados en este modelo.
Aunque no vamos a entrar en detalle, el tipo de diccionarios que utiliza este modelo es, en la mayoría de los casos, el glosario en Internet. Este producto utiliza un lenguaje estándar, HTML20, para estructurar y formatear la información, es un lenguaje de etiquetado descriptivo, que es interpretado por todos los navegadores de Internet, por lo que, el usuario, no precisa ningún software o hardware específico21. La información junto con las etiquetas HTML se almacena en archivos de texto con extensión htm, o html denominados documentos html o páginas Web. La información contenida en estos documentos es, por tanto, totalmente accesible desde cualquier máquina, cualquier navegador y cualquier lugar del mundo conectado a Internet, constituyendo diccionarios con una dimensión universal.
Actualmente, el lenguaje HTML se está utilizando únicamente como lenguaje de presentación, para formatear la información. Esto es así por la necesidad creciente de distinguir entre estructura y presentación de la información, distinción que está haciendo evolucionar rápidamente los lenguajes de marcado. Se están definiendo lenguajes generales de marcado, basados en un metalenguaje estándar (ISO-8879), XML, que permiten estructurar y describir explícitamente la información con el grado de precisión que se desee. Estos documentos se acompañan de otros (CSS o XSL) que definen el formato o formatos de visualización de la información. Además, existe una tecnología XML en rápida evolución que ya permite abordar la cuestión del procesamiento semántico de la información22. Sobre esta cuestión volveremos en la sección 4.
En los diccionarios electrónicos, la estructura de la información utilizando el modelo hipertexto, es similar a los diccionarios tradicionales impresos. La unidad básica de almacenamiento es la entrada léxica que, a su vez, contiene los distintos tipos de información asociada a dicha entrada. Sin embargo, incorpora una posibilidad nueva, enlazar la información. Así, por ejemplo, en los glosarios encontramos definiciones que utilizan términos que se consideran importantes para definir, por lo que se añaden al glosario y se enlazan con ellos. Los diccionarios, de forma mucho más completa, enlazan todas las palabras contenidas en una entrada léxica con sus entradas correspondientes.
No existe un modelo de datos claramente elegido para la construcción de diccionarios electrónicos, pero sí que existen esfuerzos internacionales23 en la búsqueda de modelos estándares que superen las limitaciones e inconvenientes de los modelos relacional e hipertextual, y permitan construir diccionarios cuyo conocimiento sea más accesible, fácil de mantener y procesar “inteligentemente” (Bertino et. al., 2001). Asimismo, se está planteando la posibilidad de que se puedan utilizar estos diccionarios como lexicones computacionales e incluirse en sistemas que procesen lenguaje natural (SPLN) para obtener la información léxica que necesitan en los procesos de comprensión y/o generación de lenguaje natural. Estas son las líneas que están marcando la evolución los modelos de datos para la construcción de diccionarios electrónicos.
Notas
14 La gestión de información se refiere a la creación, modificación, borrado y consulta o recuperación de la información almacenada.| Estudios de Lingüística del Español (ELiEs), vol. 24 (2006) | ISSN: 1139-8736 |