| ISSN: 1139-8736 Depósito Legal: B-25223-99 |
3.3.1. Proyecto Sift (LKB-Acquilex)
El proyecto Sift y Acquilex han mostrado1 que las estructuras de definición a través de diccionarios en distintas lenguas proporcionan suficiente información como para inferir explícitamente relaciones semánticas. En Acquilex, esas herramientas y recursos fueron desarrollados como parte de un estudio para determinar la posibilidad de derivar una base de conocimiento léxico multilingüe. Estos métodos no se aplicaron a grandes cantidades de datos, sino a un pequeño subconjunto para el que se extrajo mucha más información que las relaciones semánticas. Estas herramientas y recursos básicos están preparados para su explotación y existe un conocimiento claro sobre las limitaciones de estas técnicas. De hecho, según explican los autores de este estudio, dado el estado de las bases de datos, herramientas y experiencias puede decirse que no requiere un esfuerzo excesivo poder desarrollar redes semánticas completas y que vale la pena concentrarse en la relación y mezcla de recursos léxicos distintos.
En este proyecto, la extracción de relaciones semánticas a partir de diccionarios en soporte electrónico parte de la desambiguación del término genus en las definiciones. Utilizando el Longman Dictionary of Comtemporary English2 (LDOCE), organizan distintas jeraquías conectando los términos genus y sus adyacentes3 una vez desambiguados, construyendo así árboles de primitivos semánticos u ontologías. El siguente paso consiste en interpretar el tipo de relación que dichos elementos de las definiciones representan.
En este sentido, las meronimias ocupan un lugar importante entre las relaciones que se han utilizado en este proyecto. Las dependencias léxicas en la base de datos léxica de Sift son las siguientes:
Relaciones del proyecto Sift
Hiponimia |
|
hiperónimos BASIC_HYPERONYM |
hipónimos BASIC_HYPONYM |
Meronimia |
|
holónimos PORTION_HOLONYM |
merónimos PORTION - MERONYM |
| Sinonimia | Antonimia |
sinónimos REGISIER_SYNONYM |
antónimos CO - HYPONYM-ANTONYM |
Analogía |
|
analogías SPECIFIC-ANALOGY |
|
Instancia |
|
Este proceso de interpretación es crucial para pasar desde la información que proporcionan los genus a las dependencias léxicas que queremos establecer. Sin entrar en detalles en el tipo de representación, podemos mostrar una entrada tipo en la que se especifican estas dependencias léxicas:
Entry screen
Genus kind of frame
LD Hyperonyms
Entry: frame
Type: KIND_HYPERONYM
Los términos genus también expresan meronimias. El proyecto Sift contempla cuatro tipos de meronimia:
| 1- merónimo-holónimo básico |
| 2- porción-masa (PORTION-MASS) |
| 3- grupo-miembro (GROUP-MEMBER) |
| 4- componente-todo (COMPONENT-WHOLE) |
Los patrones sintácticos y léxicos que suelen utilizar en las definiciones para representar las meronimia pueden variar enormemente (ver capítulo 4), sin embargo, la estructura N + de + Complemento (of complement) y algunas palabras clave como group, member, part parecen predominar en el LDOCE. También utiliza expresiones como conteniendo, con + Det, provisto de, etc.
| Tipo de meronimia | Palabra entrada | Definición del LDOCE 1978 |
| 1- merónimo-holónimo básico | set | a group of elements |
| 2- porción-masa | content | the amount of a substance |
| 3- grupo-miembro | phrase | a small group of words |
| 3- grupo-miembro | list | a set of names of things written one after the other |
| 3- grupo-miembro | number | a member of the system used in counting and measuring |
| 4- componente-todo | chapter | one of the main divisions of a book or long article |
| 4- componente-todo | file | any of various arrangements of drawers, shelves, boxes, or case |
Una de las razones que aluden para distinguir entre varios tipos de relaciones meronímicas es su diferente comportamiento en cuanto al grado de predicción que se puede realizar sobre las propiedades de los elementos relacionados. De esta manera, la distinción de cada uno de los subtipos diferentes tiene consecuencias para el peso de los rasgos: en el caso de las relaciones porción-masa las propiedades son altamente predecibles desde el componente, es decir, la mayor parte de las propiedades del componente aplican a la palabra de la entrada, holónimo; en el caso de las relaciones grupo-miembro, la posibilidad de predecir las propiedades es menor y existen numerosas propiedades que no son transferibles; en el caso componente-todo, es aún menor, ya que un elemento o pieza de un objeto compuesto por partes mecánicas, por ejemplo, no tiene por qué coincidir en ninguna propiedad con el todo del que es parte. Aquí la herencia se ve restringida al aspecto funcional.
Entendemos por peso en un rasgo o en una relación un valor numérico que indica su grado de ser heredado o la fuerza (proximidad) de esa relación. El concepto de peso es muy utilizado en los modelos relacionales informáticos, entre otros. Por ejemplo, los autómatas finitos pueden calibrar y asignar prioridades entre distintos estados de una transición a un mismo nivel en el autómata mediante valores o pesos. Un estado con un peso menor al de otro tendrá menos posibilidades de ser utilizado para pasar a la siguiente transición. Este concepto está posiblemente inspirado en la denominada lógica difusa, en la que los valores de verdad no son dos: verdadero y falso, 0 y 1, sino varios, graduados entre 0 y 1.
En este sentido, el hecho de que dos relaciones tengan pesos similares hace sospechar algún tipo de similitud entre ambas. Los autores comparan la relación porción-masa con la hiponimia debido a su parecido en los pesos de las relaciones para transmitir rasgos.
A continuación mostraremos algunos ejemplos concretos que nos ofrecen de cada tipo específico de meronimia.
Tipo de meronimia |
Ejemplo en Sift |
| 1- merónimo-holónimo básico | Entry text Genus word + PL of a speech, article, etc. LD Hyperonyms: () Hyponyms: () Holonyms: () Entry: speech Type: BASIC-HOLONYM Entry: article Type: BASIC-HOLONYM Meronyms:
Entry: writer |
| 2- porción-masa (PORTION-MASS) amount, piece, quantity |
Entry content Genus amount of substance LD Hyperonyms Entry: amount Type: BASIC_HYPERONYM Hyponyms: () Holonyms: () Meronyms: Entry: substance Type: PORTION:MERONYM |
| 3- grupo-miembro (GROUP:MERONYM) group, number, set, member |
Entry content Genus group of words LD Hyperonyms Entry: group Type: BASIC_HYPERONYM Hyponyms: () Holonyms: () Meronyms: Entry: word Type: GROUP:MERONYM |
| 4- componente-todo
(COMPLEX:MERONYM) part, piece, system, arrangement |
Entry chapter Genus divisions of book or article LD Hyperonyms Entry: division Type: BASIC_HYPERONYM Hyponyms: () Holonyms: () Entry: book Type: COMPLEX:MERONYM Entry: article Type:COMPLEX:MERONYM Meronyms: |
Todas las relaciones pueden darse la vuelta y crear relaciones inversas para ser almacenadas en sus respectivas entradas.
En cuanto a la meronimia y holonimia básica (BASIC_MERONYM, BASIC_HOLONYM), los autores la definen como meronimia por defecto que se utiliza en aquellos casos en los que la interpretación no está suficientemente clara a la hora de asignar un subtipo de meronimia. Es decir, para ellos no tiene un estatus definido (a diferencia de lo que veremos en los próximos capítulos).
Extraen finalmente interesantes conclusiones sobre la disposición de los datos en un modelo relacional en el que cada entrada corresponda a un único significado de un único término, esto es, que no utiliza el concepto de synset (ver la próxima sección), y las figuras geométricas y grafos resultantes de esa disposición, concretamente sobre las interpretaciones de bucles laterales (dos elementos o más relacionados al mismo nivel) que pueden ser vistos como co-hipónimos o como sinónimos.
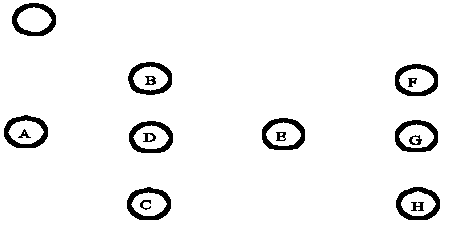
A propósito de las relaciones arbóreas unarias, establecen una interpretación específica para las meronimias, utilizando como ejemplo la siguiente estructura arbórea:
En el caso de la meronimia, el término «A» es el todo mayor y más inclusivo. La relación entre «D» y «E» es única con respecto a la estrcutura arbórea de los demás significados. Esto significa que las propiedades que se pueden predecir de «E» desde «D» no están diferenciadas en este nivel, sino en el siguiente. La unicidad de una relación meronímica puede ser vista como indicador de la fuerza de la herencia o posibilidad de predecir propiedades desde un componente hacia su todo. La herencia y peso de propiedades de componentes a todos están determinadas, según estos autores, entre otras cosas, por el grado en el que los componentes conforman el todo. En cualquier caso consideran que pesar las relaciones para lograr inferencias específicas es una tarea muy tediosa4.
NOTAS
1 Vossen & Bon (1996). 2 Edición de 1978. 3 Ver Vossen & Bon (1996), págs 2-18. 4 Efectivamente, parece que existen algunas labores de representación semántica que exigen análisis automáticos, pues la tarea manual resulta excesivamente costosa.
Anterior I Siguiente I Índice capítulo 3 I Índice General
| ISSN: 1139-8736 Depósito Legal: B-25223-99 |