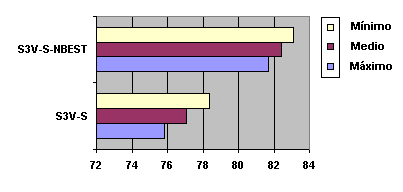
Fig. 5.24 Diagrama donde se observa el valor mínimo, medio y máximo
(banda de probabilidad) para cada uno de los sistemas (S3V-S-NBEST, S3V-S).
Representación gráfica de la Tabla 5.39
| ISSN: 1139-8736 Depósito Legal: B-8714-2001 |
5.4.2.2.1 Sin gramática
En la siguiente tabla se muestran los resultados (Tasa de Aciertos de Palabra) obtenidos con cuatro caminos, para los cuatro locutores de la base de datos, sin utilizar gramática (S3V–S-NBEST):
S3V–S-NBEST Tasa de Acierto de Palabras (WA) N = 4 ENR FER LEA ROM WAMEDIO _ 80.56 73.27 84.20 91.58 82.40 Tabla 5.39 Resultados de la Evaluación (Tasa de Aciertos de Palabra o Word Accuracy) del Módulo Acústico utilizando modelos semicontinuos de Markov de 3 codebooks (S3V) con pausado, sin gramática, con el diccionario que modela las transiciones fonológicas entre palabras en habla continua y nombres propios compuestos como varias palabras (D-S). Resultados para los 4 locutores (ENR, FER, LEA y ROM) y su promedio. Se han generado 4 hipótesis de salida (N = 4 caminos).
Además, nos interesará conocer que tipo de error ha sido el más beneficiado por esta estrategia, y el número de caminos realmente diferentes que se producen si utilizamos el criterio general: “caminos válidos son aquellos que se diferencian al menos en una palabra”, considerando como palabras los silencios acústicos y considerando diferentes las distintas pronunciaciones que una palabra puede tener en el diccionario. El uso de este criterio ha dado lugar a una reducción considerable del número de caminos a considerar, es decir, no siempre hemos obtenido cuatro caminos diferentes sino que en muchos casos, entre dos caminos la única diferencia era la inclusión o borrado de silencios, o el uso de una pronunciación diferente para una determinada palabra, lo que no conduce a ninguna compensación de error que mejore la calidad de la salida del reconocedor. Todo ello se puede observar en la siguiente tabla.
En la siguiente tabla y la gráfica que viene a continuación vemos las bandas de probabilidad calculadas para los sistemas con un solo camino óptimo (S3V-S) y cuatro caminos (hipótesis de reconocimiento) (S3V-S-NBEST):
SISTEMA WA Mínimo WA Medio WA Máximo S3V-S 75,831 77,090 78,349 S3V-S-NBEST 81,688 82,400 83,112 Tabla 5.40 Bandas de Probabilidad asociadas a los valores promedio de los cuatro locutores para los experimentos anteriores (Tabla 5.39)
Nota.- Realmente, S3V-S es el sistema S3V-S-NBEST en el que el número de caminos es igual a 1 en lugar de 4.
Fig. 5.24 Diagrama donde se observa el valor mínimo, medio y máximo (banda de probabilidad) para cada uno de los sistemas (S3V-S-NBEST, S3V-S). Representación gráfica de la Tabla 5.39
Del análisis de las bandas se deduce que la estrategia de cuatro caminos es claramente significativamente superior a la de un sólo camino.
S3V-S-NBEST N = 4 Porcentaje de Hipótesis Diferentes para N = 4 Caminos Caminos Distintos ENR FER LEA ROM 4 31% 29% 22% 15% 3 25% 25% 21% 23% 2 31% 38% 41% 39% 1 13% 8% 16% 23% Tabla 5.41 Análisis del número de caminos diferentes (de 1 mínimo a 4 como máximo) obtenidos para cada locutor si consideramos que dos frases o hipótesis de salida son distintas cuando las secuencias de palabras , eliminando los silencios o pausas entre palabras, correspondientes a ambas frases son diferentes en, al menos, una unidad. Tampoco se consideran los silencios inicial y final de la frase.
En la tabla anterior podemos observar cómo para locutores con mayor Tasa de Acierto de Palabras (WA), como son LEA y ROM, el número de caminos distintos disminuye considerablemente, aumentando el número de casos en los que de los cuatro caminos obtenidos por el sistema, sólo dos o uno son realmente distintos (a nivel de palabra sin considerar los silencios ni las múltiples pronunciaciones de algunas palabras). Esto nos conduce a plantear que, para locutores con pocos errores, recuperarse de los mismos supone en general, aumentar mucho el número de caminos a generar, y conseguir así un mayor número de caminos diferentes de entre los cuales podamos obtener la frase correcta. Sin embargo, con los locutores peores ENR, FER se observa el efecto contrario, permitiendo recuperar algunos errores con facilidad, es decir, generando pocas hipótesis de salida (N pequeños).
En las dos tablas siguientes se muestra cómo se reparten los distintos tipos de error (sustituciones, borrados, e inserciones) para los cuatro locutores de la base de datos, cuando se genera una sola hipótesis (primera tabla) y varias hipótesis, concretamente cuatro (segunda tabla). Con ellas se pretende comprender el modo en que afecta al error el uso de una estrategia de generación de las N mejores hipótesis de salida.
S3V-S-NBEST
N =1 CAMLocutor Tipo de Error ENR FER LEA ROM Sustitución 14 % 16.2 % 11.1 % 7.8 % Inserción 0.1 % 0.5 % 0.5 % 0.4 % Borrado 11.5 % 15.6 % 8.8 % 4.6 % Tabla 5.42 Distribución del Tipo de Error (Sustitución, Borrado e Inserción) cuando se genera una sola hipótesis de salida. Es un experimento de referencia para intentar comprender mejor el comportamiento de este tipo de estrategias, es decir, la generación de las N-mejores hipótesis.
S3V-S-NBEST
N = 4 CAMLocutor Tipo de Error ENR FER LEA ROM Sustitución 11.8 % 14.7 % 8.5 % 5.4 % Inserción 0.4 % 1 % 0.7 % 0.5 % Borrado 7.2 % 10.4 % 6.5 % 2.5 % Tabla 5.43 Distribución del Tipo de Error (Sustitución, Borrado e Inserción) al aumentar el número de hipótesis de salida a generar hasta 4. Permite comprobar cómo una estrategia como ésta, es decir, la generación de las N-mejores hipótesis, aunque para valores de N pequeños (N = 4), permite al Módulo Acústico recuperarse de algunos errores, principalmente sustituciones y borrados.
Se puede observar cómo han aumentado, relativamente, las inserciones al utilizar la estrategia de generación de las N mejores hipótesis de salida pero, sin embargo, han disminuido considerablemente, y de modo, unívoco, para los cuatro locutores, las sustituciones y los borrados.
El espacio de estados con cuatro hipótesis de salida se incrementa considerablemente (se multiplica por NCAM) si lo comparamos con la versión que genera una sola hipótesis.
S3V, NG,D-S NCAM=1 NCAM=4 Espacio Estados 31374 125496 Tabla 5.44 Tamaño del Espacio de Búsqueda medido en número de estados a procesar en el caso de generar una sólo hipótesis de salida o 4 hipótesis. Se observa que el incremento es considerable.
| Conclusión: la modificación del algoritmo de Un Paso para generar N hipótesis de salida (una óptima y N-1 subóptimas) es una buen estrategia que aumenta significativamente la tasa de acierto de palabras aún para un número de hipótesis pequeño (en nuestro caso con cuatro caminos hemos obtenido diferencias significativas). Sin embargo, no debemos olvidar que el espacio de búsqueda se incrementa considerablemente y que el uso de estrategias de recorte como las estudiadas en esta tesis se hacen necesarias para mantener el tiempo de proceso en unos límites razonables. Además, debemos tener en cuenta cómo el sistema que utilice la salida del reconocedor va a manejar la información de las N hipótesis de salida de un modo elegante y de fácil implementación (por ejemplo, con un grafo). |
Anterior I Siguiente I Índice capítulo 5 I Índice General
| ISSN: 1139-8736 Depósito Legal: B-8714-2001 |