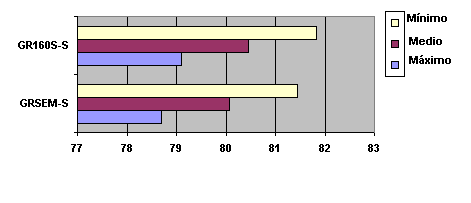
Fig. 5.22 Diagrama donde se observa el valor mínimo, medio y máximo
(banda de probabilidad) para cada uno de los sistemas (GR160S-S, GRSEM-S). Representación
gráfica de la Tabla 5.33.
| ISSN: 1139-8736 Depósito Legal: B-8714-2001 |
5.4.1.3 Con la gramática semántica GRSEM-S
Para evaluar la influencia de esta gramática semántica, adaptada al dominio semántico de la aplicación, desde el punto de vista de calidad acústica, es decir, de la Tasa de Aciertos de Palabra, utilizamos el mismo conjunto de frases de evaluación que para el resto de los experimentos realizados en este capítulo al cuál le hemos quitado un pequeño grupo de frases (ST0029, ST0030, ST0031, ST0032, ST0033, ST0036, ST0038, ST0060, ST0064, ST0069, ST0076, ST0088, ST0097). De este modo el conjunto de evaluación se ha visto reducido a 87 de las 100 frases originales, no utilizadas en las fases de entrenamiento de ninguno de los sistemas. Esta reducción no es significativa y responde al hecho de que, debido al dominio semántico diseñado, no todas las frases del conjunto de entrenamiento ni del conjunto de evaluación pertenecen, semánticamente hablando, al mismo, y por tanto, el sistema no pretende que sean cubiertas, pero no por error de la gramática semántica utilizada sino por definición de la misma. De este modo, todas las frases del conjunto de evaluación deberían estar teóricamente cubiertas por la gramática entrenada con las frases de entrenamiento seleccionadas, y los fallos de cobertura que se produzcan sí podrán considerarse limitaciones o errores de la gramática utilizada.
Para comparar los resultados obtenidos con los de la gramática morfosintáctica que hemos utilizado anteriormente, realizaremos experimentos con GR160S-S empleando el conjunto de evaluación de 87 frases que hemos seleccionado cubiertas semánticamente por la gramática GRSEM-S, en la que los nombres propios compuestos se tratan como palabras independientes, al igual que han sido considerados en la gramática semántica. Sin embargo, debemos añadir que la propia gramática semántica incorpora una pequeña gramática para los nombres propios compuestos, aunque no en el nivel del diccionario como ocurría con la gramática GR160S-J. Utilizamos los modelos HMM semicontinuos de tres codebooks con pausado S3V, y realizamos experimentos para los cuatro locutores. Mantenemos los pesos PIP y PG óptimos calculados para las gramáticas morfosintácticas, aunque lo más correcto hubiese sido calcular los pesos óptimos para la nueva gramática semántica.
S3V (87 frases) Tasa de Aciertos de Palabras (WA) _ Locutores ENR FER LEA ROM WAMEDIO PIP-PG 25000-1.5 22000-1.5 20000-2.0 20000-2.0 PIP-PGOPT GRSEM-S 78.76 69.48 81.34 88.35 79.48 GR160S-S 79.89 69.89 81.03 91.23 80.51 Tabla 5.33 Resultados de la Evaluación (Tasa de Aciertos de Palabra o Word Accuracy) del Módulo Acústico utilizando modelos semicontinuos de Markov de 3 codebooks (S3V) con pausado, con la gramática semántica del dominio de aplicación GRSEM-x, con el diccionario (D-S) y la gramática de 160 macrocategorías GR160S-S suavizada y el mismo diccionario. Resultados para los 4 locutores (ENR, FER, LEA y ROM) y su promedio. Con el factor de ponderación de la información gramatical frente a la acústica óptimo en cada caso (PG óptimo) y con la penalización de las inserciones de palabra óptima en cada caso (PIP óptima) en ambos casos. Los experimentos se han realizado sobre las 87 frases del conjunto de evaluación que pertenecen al dominio semántico y por tanto cubiertas, en un principio, por la gramática semántica.
Las bandas de probabilidad en el caso de los sistemas que utilizan gramáticas semánticas, basadas en un autómata finito probabilístico de categorías semánticas del dominio de aplicación, se encuentran en la siguiente tabla y la gráfica que aparece a continuación.
SISTEMA WA Mínimo WA Medio WA Máximo GRSEM-S 78,209 79,480 80,751 GR160S-S 79,264 80,510 81,756 Tabla 5.34 Bandas de Probabilidad asociadas a los valores promedio de los cuatro locutores para los experimentos anteriores (Tabla 5.33). Recuerde que los resultados son sobre 87 frases de evaluación
Fig. 5.22 Diagrama donde se observa el valor mínimo, medio y máximo (banda de probabilidad) para cada uno de los sistemas (GR160S-S, GRSEM-S). Representación gráfica de la Tabla 5.33.
| TEST BANDAS | GR160S-S |
| GRSEM-S | IGUAL |
Tabla 5.35 Tabla de Comparación de los sistemas GR160S-S, GRSEM-S utilizando el test de las Bandas de Probabilidad
| Conclusión: del análisis objetivo de los resultados deducimos que la gramática semántica no aporta ninguna mejora significativa, en cuanto a Tasa de Acierto de Palabras (WA) se refiere, con respecto al uso de la gramática morfosintática de 160 macrocategorías. Sin embargo, debe considerarse que, a pesar de que la gramática semántica pretende ser lo más robusta posible, aún presenta una perplejidad menor que la gramática morfosintáctica y además, permite obtener la frase de salida segmentada conceptualmente, ahorrando todo un proceso (Decodificador Conceptual) en el Módulo de Comprensión. Debido a ello, parece una opción interesante a considerar en el diseño de arquitecturas para comprensión de habla. Además, sería interesante analizar el tipo de errores que se producen con cada gramática (morfosintáctica y semántica) para poder afirmar realmente que son equivalentes a nivel semántico, y no sólo a nivel de palabras. Es posible que los errores del sistema que utiliza la gramática semántica sean menos significativos para el proceso de comprensión en sí, es decir, estén más acordes con la tarea de comprensión y por tanto, incrementar el valor añadido de las mismas. |
A la hora de analizar los resultados debemos tener en cuenta los problemas de cobertura que presenta la gramática semántica comparada con la morfosintáctica. Aunque su perplejidad es menor, con el conjunto de frases de entrenamiento utilizado, es muy probable que aparezcan estructuras (secuencias de categorías semánticas) nuevas para algunos conceptos en las frases de evaluación e incluso que algún concepto no haya sido incluido en la gramática, que falten incluso categorías semánticas. Lo único que hemos intentado es que existiera la mayor cobertura posible a nivel de palabras del diccionario para las distintas categorías. La gramática morfosintáctica suavizada no adolece de estos problemas de cobertura aunque tiene una perplejidad más elevada.
Debemos tener en cuenta que la gramática semántica GRSEM-S no tiene una cobertura total de las frases del conjunto de evaluación (las 87 frases), lo que redunda en la tasa de aciertos de palabra. Las frases no cubiertas son: ST0013, ST0022, ST0039, ST0052, ST0054, ST0067, ST0070, ST0071, ST0073, ST0077, ST0082, ST0089, ST0090.
Si eliminamos las frases no cubiertas del conjunto de frases de evaluación y medimos la perplejidad de dicho conjunto utilizando la gramática GR160S-S, obtenemos un valor de 450.1. Más cercano al de la perplejidad de la gramática semántica GRSEM-S, cuyo valor era 317.56, aunque todavía mayor. Parece que existe una cierta discrepancia entre los valores de perplejidad y las tasas de acierto de palabras para ambas gramáticas. Para comprender cómo afecta la no cobertura de la gramática semántica a los errores a nivel de palabra, realizamos un experimento utilizando sólo aquellas frases del conjunto de evaluación que sí son cubiertas por la gramática semántica y comparamos con la gramática morfosintáctica suavizada GR160S-S.
S3V (74 frases) Cobertura Total Tasa de Aciertos de Palabras (WA) Locutores ENR FER LEA ROM WAMEDIO PIP-PG 25000-1.5 22000-1.5 20000-2.0 20000-2.0 PIP-PGOPT GRSEM-S 79.70 69.07 82.39 89.11 80.07 GR160S-S 80.31 69.19 81.17 91.19 80.46 Tabla 5.36 Resultados de la Evaluación (Tasa de Aciertos de Palabra o Word Accuracy) del Módulo Acústico utilizando modelos semicontinuos de Markov de 3 codebooks (S3V) con pausado, con la gramática semántica del dominio de aplicación GRSEM-x, con el diccionario (D-S) y la gramática de 160 macrocategorías GR160S-S suavizada y el mismo diccionario. Resultados para los 4 locutores (ENR, FER, LEA y ROM) y su promedio. Con el factor de ponderación de la información gramatical frente a la acústica óptimo en cada caso (PG óptimo) y con la penalización de las inserciones de palabra óptima en cada caso (PIP óptima) en ambos casos. En este caso se han eliminado aquellas frases para las que no existe cobertura en la gramática semántica
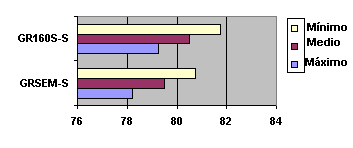
Las bandas de probabilidad para los sistemas que utilizan gramáticas semánticas y morfosintácticas, pero considerando el hecho de la cobertura del modelo semántico, que es el que está adaptado al dominio de aplicación, se encuentran en forma de tablas y de gráfico de barras a continuación.
SISTEMA WA Mínimo WA Medio WA Máximo GRSEM-S 78,701 80,070 81,439 GR160S-S 79,101 80,460 81,819 Tabla 5.37 Bandas de Probabilidad asociadas a los valores promedio de los cuatro locutores para los experimentos anteriores (Tabla 5.36). Recuerde que los resultados son sobre las frases de evaluación pertenecientes al dominio semántico de la aplicación y además, cubiertas por la gramática semántica.
Fig. 5.23 Diagrama donde se observa el valor mínimo, medio y máximo (banda de probabilidad) para cada uno de los sistemas (GR160S-S, GRSEM-S). Representación gráfica de la Tabla 5.36, con los resultados de procesar sólo aquellas frases del conjunto de evaluación pertenecientes al dominio semántico de la aplicación y además, cubiertas por la gramática semántica.
TEST BANDAS GR160S-S GRSEM-S IGUAL Tabla 5.38 Tabla de Comparación de los sistemas GR160S-S, GRSEM-S utilizando el test de las Bandas de Probabilidad, con los resultados de procesar sólo aquellas frases del conjunto de evaluación pertenecientes al dominio semántico de la aplicación y además, cubiertas por la gramática semántica.
De su análisis se deduce exactamente lo mismo que en el caso de problemas de cobertura, es decir, no aporta información el hecho de trabajar con gramáticas semánticas de elevada perplejidad frente a gramáticas morfosintácticas generales de la lengua.
Podemos observar que las diferencias relativas se siguen manteniendo, aunque no son significativas, y que las frases no cubiertas por la gramática semántica no introducen errores significativos con respecto a la gramática morfosintáctica. No nos queda nada más que pensar que las diferencias se deben a la propia naturaleza de la gramática semántica.
| Conclusión: las gramáticas semánticas basadas en autómatas finitos probabilísticos con categorías semánticas del dominio de aplicación, diseñados de forma robusta (buscando la mayor cobertura posible), mantienen una perplejidad comparable aunque algo menor (317.56) a las gramáticas morfosintácticas (481.22 de GR160S-J y 501.69 de GR160S-S) (basadas en categorías sintácticas de la lengua) entrenadas con textos no pertenecientes al dominio de aplicación, por lo que no suponen una clara ventaja frente a las segunda, siendo además mucho más difícil su entrenamiento o generación. Sin embargo, sirven para el propósito de la comprensión del contenido semántico de la frase reconocida y ahorran proceso en el módulo de comprensión. |
Anterior I Siguiente I Índice capítulo 5 I Índice General
| ISSN: 1139-8736 Depósito Legal: B-8714-2001 |