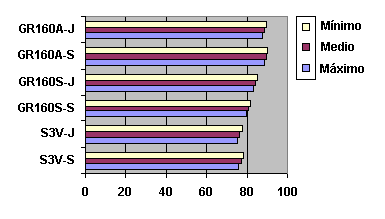
Fig. 5.21 Diagrama donde se observa el valor mínimo, medio y máximo
(banda de probabilidad) para cada uno de los sistemas (S3V-S, S3V-J, GR160S-S, GR160S-J,
GR160A-S, GR160AJ). Representación gráfica de la Tabla 5.31.
| ISSN: 1139-8736 Depósito Legal: B-8714-2001 |
5.4.1.2 Con las gramáticas morfosintácticas GR160S-J y GR160S-S
A continuación se presentan los experimentos de referencia, con los 4 locutores, sin utilizar ningún Peso de Inserción de Palabras (PIP) ni ningún Peso Gramatical (PG), es decir, el peso para la información acústica y gramatical es el mismo. La gramáticas utilizadas son GR160S-J y GR160S-S (con sus diccionarios respectivos D-160J y D-160S). Los modelos de Markov son los SCHMM de tres codebooks con pausado de Viterbi (S3V).
S3V
PIP=0;PG=1Tasa de Aciertos Palabras (WA) Locutor GR160S-J GR160S-S ENR 78.97 78.31 FER 68.59 68.31 LEA 82.33 81.96 ROM 88.03 88.50 Tabla 5.26 Resultados de la Evaluación (Tasa de Aciertos de Palabra o Word Accuracy) del Módulo Acústico utilizando modelos semicontinuos de Markov de 3 codebooks (S3V) con pausado, con la gramática morfosintáctica de 160 macrocategorías suavizada general del castellano, cambiando el diccionario (D-S, D-J). Resultados para los 4 locutores (ENR, FER, LEA y ROM) . Sin ponderar la información gramatical frente a la acústica (PG=1) y sin penalizar las inserciones de palabras (PIP=0).
Ajuste de los Pesos de Inserción de Palabras (PIP) en el caso de utilizar una Gramática
Se supone que la incorporación de las restricciones gramaticales en el espacio de búsqueda deben compensar la falta de calidad de los patrones de reconocimiento (modelos HMM), sobre todo si estos no son demasiado buenos. En nuestro caso, vamos a utilizar modelos HMM semicontinuos con tres codebooks (S3HMM), que han demostrado tener un buen comportamiento en ausencia de gramática (Tesis Doctoral de Javier Ferreiros [FER96]). La gramática es GR160S-J, y el diccionario D-160J. Se analiza cómo varía la Tasa de Aciertos de Palabra (TAP) (WA-Word Accuracy, en inglés).
S3V – GR160S-J - PG = 1.0 - PIP variable ENR FER LEA ROM PIP WA PIP WA PIP WA PIP WA 15000 79.71 12000 70.56 10000 82.42 10000 89.71 25000 80.37 22000 70.93 20000 82.42 20000 91.12 35000 79.90 32000 70.84 30000 82.05 30000 90.74 45000 79.43 42000 70.56 40000 81.58 40000 90.93 55000 78.59 52000 70.74 50000 81.58 50000 90.18 Tabla 5.27 Tasa de Acierto de Palabras obtenida con el sistema S3V – GR160S-J, sin ponderar la gramática PG=1.0, y variando el Peso de Inserción de Palabras (PI). Para cada locutor y cada peso PIP se ha obtenido la Tasa de Acierto de Palabras (Word Accuracy)
Ajuste de la Ponderación de la Gramática (PG) sin Penalizar las Inserciones de Palabras (PIP)
A continuación llevamos a cabo el ajuste de la Ponderación de la Gramática (PG), sin penalizar las inserciones de palabras (PIP), con un factor de penalización o ponderación de la información gramatical frente a la del modelo acústico. Los modelos de Markov utilizados son los S3V, la gramática es GR160S-J, y el diccionario D-160J.
S3V
PIP=0;PG var GR160S-JTasa de Aciertos Palabras (WA) Locutores Peso Gramatical ENR FER LEA ROM 0.5 75.14 62.71 81.02 84.29 1.0 78.97 68.59 82.33 88.03 1.236 80.18 68.69 82.24 88.50 1.388 79.71 67.10 81.21 88.03 1.5 80.28 68.78 80.84 88.87 2.0 78.13 68.13 82.61 90.00 2.235 76.63 63.45 81.77 86.91 2.387 73.17 62.99 79.43 85.04 2.5 74.57 62.24 79.62 85.60 Tabla 5.28 Tasa de Acierto de Palabras obtenida con el sistema S3V – GR160S-J, sin Penalizar la Inserción de Palabras (PIP=0), y variando la Ponderación Gramatical (PG). Para cada locutor y cada factor de ponderación PG, se ha obtenido la Tasa de Acierto de Palabras (Word Accuracy)
Con los pesos PIP ( Peso de Inserción de Palabras) y PG (Ponderación Gramatical) obtenidos y que producen una mejor Tasa de Acierto de Palabras (WA), considerados como pesos independientes, evaluamos el sistema con la gramáticas GR160S-J y GR160S-S con sus diccionarios respectivos (D-160J y D-160S), con los modelos de Markov semicontinuos de tres codebooks (S3V). Los resultados obtenidos se muestran en la siguiente tabla. Hemos supuesto que los pesos PIP y PG óptimos calculados para la gramática GR160S-J son también óptimos para la otra gramática GR160S-S, hipótesis que no es cierta pues cada gramática necesita del ajuste de los pesos de modo particular. Esto ha sido comprobado al realizar experimentos con la gramática GR160S-S para dos locutores, ENR y FER. En ellos hemos probado a variar el peso PG de 1.5 a 1.0, es decir, no ponderamos el conocimiento gramatical frente al acústico, obteniendo una ligera mejora (WAENR: 80.18 , WAFER: 71.68). Sin embargo, para no tener que realizar tantos experimentos de ajuste para esta gramática, supondremos que los pesos óptimos calculados para GR160S-J son óptimos también para GR160S-S, basándonos en las pocas diferencias que existen entre ellas.
Resultados Combinando los Pesos de Inserción de Palabra (PIP) y la Ponderación Gramatical Óptimos
S3V Tasa de Aciertos de Palabras (WA) _ Locutores ENR FER LEA ROM WAMEDIO PIP-PG 25000-1.5 22000-1.5 20000-2.0 20000-2.0 PIP-PGOPT GR160S-J 82.14 73.83 82.71 92.80 84.12 GR160S-S 79.62 70.74 81.02 91.30 80.67 Tabla 5.29 Resultados de la Evaluación (Tasa de Aciertos de Palabra o Word Accuracy) del Módulo Acústico utilizando modelos semicontinuos de Markov de 3 codebooks (S3V) con pausado, con la gramática morfosintáctica de 160 macrocategorías suavizada general del castellano, cambiando el diccionario (D-S, D-J). Resultados para los 4 locutores (ENR, FER, LEA y ROM) . Con el factor de ponderación de la información gramatical frente a la acústica óptimo en cada caso (PG óptimo) y con la penalización de las inserciones de palabra óptima en cada caso (PIP óptima).
La diferencia entre GR160S-J y GR160S-S es significativa como veremos más adelante en las bandas de probabilidad calculadas.
El uso de una gramática de macrocategorías entrenada con textos diferentes no pertenecientes al dominio semántico de la aplicación, nos hace cuestionar la importancia de la adaptación de los modelos gramaticales al dominio de aplicación, con el objetivo de obtener una mejor cobertura natural, y una menor perplejidad. Para valorar y entender el problema se ha llevado a cabo un análisis de las matriz de macrocategorías utilizada, y se ha generado una matriz entrenada sólo con los textos del corpus DARPA-ESPAÑOL, los del dominio semántico de la aplicación. Esta gramática adaptada sólo servirá para encontrar un punto de referencia, el valor de la mejor tasa de reconocimiento que podría obtenerse al incorporar un modelo gramatical caracterizado por ese conjunto de macrocategorías si los datos de entrenamiento fuesen los más indicados, cosa que no suele ocurrir en la realidad y que puede justificar la necesidad de adaptar las gramáticas obtenidas para el lenguaje en general al dominio semántico de nuestra aplicación. Los pesos utilizados para cada locutor son los pesos óptimos obtenidos en el caso de la gramática no adaptada. Las gramáticas se llamarán ahora GR160A-J y GR160A-S, respectivamente. No necesitan estar suavizadas pues han sido entrenadas con todo el corpus DARPA-ESPAÑOL. Recuerde que sólo sirven para obtener el caso mejor posible si nuestro entrenamiento fuese el más adecuado.
Resultados Combinando los Pesos de Inserción de Palabra (PIP) y la Ponderación Gramatical Óptimos pero utilizando la gramática adaptada al dominio de aplicación (GR160A-x)
Las bandas de probabilidad para los sistemas con la gramática de macrocategorías suavizada, y los diccionarios que modelan las transiciones fonológicas entre palabras propias del habla continua (GR160S-S) y con los nombres propios compuestos como una sola palabra (GR160S-J), se muestran a continuación, en forma de tabla y gráficamente. Además, se han incorporado los sistemas equivalentes pero sin la incorporación de gramáticas (S3V-S, S3V-J), y los sistemas con las gramáticas adaptadas al corpus de frases del dominio de aplicación (GR160A-S, GR160A-J).
S3V Tasa de Aciertos de Palabras (WA) _ Locutores ENR FER LEA ROM WAMEDIO PIP-PG 25000-1.5 22000-1.5 20000-2.0 20000-2.0 PIP-PGOPT GR160A-J 88.22 80.18 90.74 95.79 88.73 GR160A-S 88.41 81.30 91.12 96.07 89.22 Tabla 5.30 Resultados de la Evaluación (Tasa de Aciertos de Palabra o Word Accuracy) del Módulo Acústico utilizando modelos semicontinuos de Markov de 3 codebooks (S3V) con pausado, con la gramática morfosintáctica de 160 macrocategorías adaptada al dominio semántico de la aplicación, cambiando el diccionario (D-S, D-J). Resultados para los 4 locutores. Con el factor de ponderación de la información gramatical frente a la acústica óptimo en cada caso (PG óptimo) y con la penalización de las inserciones de palabra óptima en cada caso (PIP óptima).
SISTEMA WA Mínimo WA Medio WA Máximo S3V-S 75,831 77,090 78,349 S3V-J 75,026 76,300 77,574 GR160S-S 79,487 80,670 81,853 GR160S-J 83,025 84,120 85,215 GR160A-S 88,457 89,380 90,303 GR160A-J 87,783 88,730 89,677 Tabla 5.31 Bandas de Probabilidad asociadas a los valores promedio de los cuatro locutores para los tres conjuntos de experimentos anteriores (Tabla 5.20, Tabla 5.29 y la Tabla 5.30)
Fig. 5.21 Diagrama donde se observa el valor mínimo, medio y máximo (banda de probabilidad) para cada uno de los sistemas (S3V-S, S3V-J, GR160S-S, GR160S-J, GR160A-S, GR160AJ). Representación gráfica de la Tabla 5.31.
TEST BANDAS S3V-J GR160S-S GR160S-J GR160A-S GR160A-J S3V-S IGUAL GRS-S GRS-J GRA-S GRA-J S3V-J ----- GRS-S GRS-J GRA-S GRA-J GR160S-S ----- ----- GRS-J GRA-S GRA-J GR160S-J ----- ----- ----- GRA-S GRA-J GR160A-S ----- ----- ----- ----- IGUAL Tabla 5.32 Tabla de Comparación de los sistemas S3V-S, S3V-J, GR160S-S, GR160S-J, GR160A-S y GR160A-J, utilizando el test de las Bandas de Probabilidad
Como ya se conoce, de las bandas de probabilidad y de la tabla comparativa anterior, se deduce que la incorporación de gramática supone un aumento significativo de la tasa de acierto de palabras en los sistemas, y que es mejor la gramática cuanto más adaptada está al dominio de aplicación como era lógico de esperar, mientras que, en este caso de gramática no adaptada, el uso de un modelo de palabra única para los nombres propios compuestos introduce también una mejora en el funcionamiento del sistema.
| Conclusión: cuánto más adaptadas estén las gramáticas al dominio de la aplicación (GR160A-x), siempre que no redunde en una menor cobertura del sistema, mayor tasa de acierto de palabras obtenemos. El modelado de los nombres propios compuestos como una sola palabra y con la posibilidad de silencio entre las palabras del nombre compuesto (GR160S-J) parece interesante de considerar en el caso de empleo de gramáticas generales no demasiado adaptadas, pues redunda en una mejora significativa del sistema. |
Anterior I Siguiente I Índice capítulo 5 I Índice General
| ISSN: 1139-8736 Depósito Legal: B-8714-2001 |