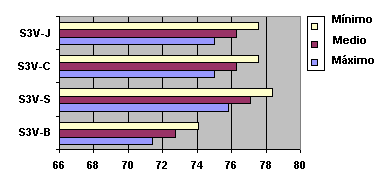
Fig. 5.19 Diagrama donde se observa el valor mínimo, medio y máximo
(banda de probabilidad) para cada uno de los sistemas (S3V-B, S3V-C, S3V-S, S3V-J).
Representación gráfica de la tabla 5.22.
| ISSN: 1139-8736 Depósito Legal: B-8714-2001 |
5.4.1.1.2 Modelos Semicontinuos con Pausado. 3 Codebooks
Los Modelos Ocultos de Markov Discretos representan la opción más básica y por tanto, peor de los diferentes Modelos HMM que es posible emplear (discretos, semicontinuos, continuos). El uso de modelos semicontinuos (SCHMM), así como la incorporación de un tercer codebook, y el modelado de las pausas internas en la frase mediante el propio proceso de entrenamiento basado en el algoritmo de Viterbi, suponen una gran mejora en los patrones acústicos que puede utilizar el sistema de reconocimiento de habla continua.
S3V Tasa de Aciertos de Palabras (WA) Léxico (Diccionario) Locutor D-B D-S D-C D-J ENR 69.25 74.39 73.83 73.83 FER 63.73 67.47 64.85 64.85 LEA 73.36 79.34 79.53 79.53 ROM 84.57 87.19 86.91 87.00 WAMEDIO 72.72 77.09 76.28 76.30 Tabla 5.20 Resultados de la Evaluación (Tasa de Aciertos de Palabra o Word Accuracy) del Módulo Acústico utilizando modelos semicontinuos de Markov de 3 codebooks (S3V) con pausado, sin gramática, cambiando el diccionario (D-B, D-S, D-C y D-J). Resultados para los 4 locutores (ENR, FER, LEA y ROM) y su promedio.
Con el fin de estudiar qué mejoras son introducidas con los nuevos modelos, realizamos los mismos experimentos descritos en el apartado anterior y que quedan reflejados en la tabla 5.20.
Los Pesos de Penalización de Inserción de Palabras (PIP) utilizados son los mismos que los obtenidos por J. Ferreiros en su Tesis Doctoral [FER96] para esta base de datos, sin utilizar gramática (NG), y para los modelos SCHMM de 3 codebooks con pausado de Viterbi (S3V):
S3V Locutor ENR FER LEA ROM PIPNG 75000 65000 60000 60000 Tabla 5.21 Pesos de Inserción de Palabras (PIP) estimados para los modelos S3V cuando no se utiliza gramática, para cada uno de los locutores de la base de datos
Las bandas de probabilidad para cada uno de los sistemas (utilizando los diferentes diccionarios pero sin usar gramática) se encuentran en la siguiente tabla y en la gráfica que viene a continuación para una mayor claridad.
SISTEMA WA Mínimo WA Medio WA Máximo S3V-B 71,386 72,720 74,054 S3V-S 75,831 77,090 78,349 S3V-C 75,006 76,280 77,554 S3V-J 75,026 76,300 77,574 Tabla 5.22 Bandas de Probabilidad asociadas a los valores promedio de los cuatro locutores para el experimento anterior (Tabla 5.20)
Fig. 5.19 Diagrama donde se observa el valor mínimo, medio y máximo (banda de probabilidad) para cada uno de los sistemas (S3V-B, S3V-C, S3V-S, S3V-J). Representación gráfica de la tabla 5.22.
En ellas podemos comprobar que vuelve a cumplirse el hecho de que la información fonológica (S3V-S) mejora significativamente la calidad (tasa) del sistema frente al diccionario básico (S3V-B), pero que el hecho de modelar los nombres propios compuestos como una sola palabra (S3V-C o S3V-J) no aporta ventajas significativas.
TEST B. S3V-B S3V-S S3V-C S3V-J S3V-B ----- S3V-S S3V-C S3V-J S3V-S ----- ----- IGUAL IGUAL S3V-C ----- ----- ----- IGUAL Tabla 5.23 Tabla de Comparación de los sistemas S3V-B, S3V-S, S3V-C y S3V-J utilizando el test de las Bandas de Probabilidad
Anterior I Siguiente I Índice capítulo 5 I Índice General
| ISSN: 1139-8736 Depósito Legal: B-8714-2001 |