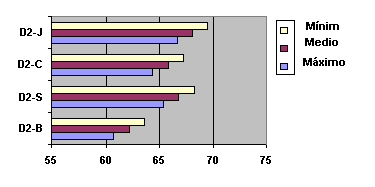
Fig. 5.18 Diagrama donde se observa el valor mínimo, medio y máximo
(banda de probabilidad) para cada uno de los sistemas (D2-B, D2-C, D2-S, D2-J).
Representación gráfica de la tabla 5.17.
| ISSN: 1139-8736 Depósito Legal: B-8714-2001 |
5.4.1.1.1 Modelos Discretos. 2 Codebooks
En la siguiente tabla presentamos las tasas de acierto de palabras (Word Accuracy, WA) obtenidas para los cuatro locutores, utilizando Modelos Discretos de Markov, con dos codebooks y sin el uso de conocimiento gramatical. Sin embargo, hemos querido comprobar las ventajas de incorporar conocimiento fonológico (las transiciones entre palabras en habla continua) en el diccionario de palabras (D-S) y tratar, además, los nombres propios compuestos como una sola palabra sin silencios entre las palabras componentes del mismo (D-C) y con la posibilidad de silencios entre las mismas (D-J). Se ha calculado el promedio de los cuatro locutores por sistema con el fin de poder comprobar las diferencias entre los diferentes tipos de diccionario, independientemente del locutor.
D2 Léxico Locutor D-B D-S D-C D-J ENR 56.44 60.93 59.25 62.52 FER 52.05 54.85 53.36 56.91 LEA 68.31 72.99 71.77 73.73 ROM 71.86 78.50 78.78 79.34 WAMEDIO 62.17 66.82 65.80 68.12
Tabla 5.16 Resultados de la Evaluación (Tasa de Aciertos de Palabra o Word Accuracy) del Módulo Acústico utilizando modelos discretos de Markov de 2 codebooks (D2), sin gramática, cambiando el diccionario (D-B, D-S, D-C y D-J). Resultados para los 4 locutores (ENR, FER, LEA y ROM) y su promedio.
Las bandas de probabilidad para cada uno de los sistemas D2-B, D2-S, D2-C, y D2-J se muestran en la tabla 5.17.
SISTEMA WA Mínimo WA Medio WA Máximo D2-B 60,717 62,170 63,623 D2-S 65,409 66,820 68,231 D2-C 64,379 65,800 67,221 D2-J 66,724 68,120 69,516
Tabla 5.17 Bandas de Probabilidad asociadas a los valores promedio de los cuatro locutores para el experimento anterior (Tabla 5.16) y su representación gráfica (figura 5.18) nos ofrece una mayor claridad en el análisis comparativo:
Fig. 5.18 Diagrama donde se observa el valor mínimo, medio y máximo (banda de probabilidad) para cada uno de los sistemas (D2-B, D2-C, D2-S, D2-J). Representación gráfica de la tabla 5.17.
Del análisis deducimos que la incorporación de conocimiento fonológico (D2-S) con o sin el modelado de los nombres compuestos como si de una sola palabra se tratase (D2-C y D2-J), es claramente mejor que utilizar el diccionario en su forma básica (D2-B). El uso de nombres propios compuestos considerados como una sola palabra no tiene en este caso ventajas significativas, aunque el uso de silencios o pausas entre las palabras del nombre compuesto mejora relativamente la tasa. Debemos tener en cuenta que muchos nombres compuestos están formados por palabras con más de una sílaba, es decir, con una longitud que favorece que el sistema de reconocimiento no cometa errores con ellos.
TEST B. D2-S D2-C D2-J D2-B D2-S D2-C D2-J D2-S ----- IGUAL IGUAL D2-C ----- ----- IGUAL D2-J ----- ----- -----
Tabla 5.18 Tabla de Comparación de los sistemas D2-B, D2,S, D2-C y D2-J utilizando el test de las Bandas de Probabilidad
Los Pesos de Penalización de Inserción de Palabras (PIP) utilizados son los mismos que los obtenidos por J. Ferreiros en su Tesis Doctoral para esta base de datos, sin utilizar gramática (NG), y para los modelos DHMM de dos codebooks (D2):
D2 Locutor ENR FER LEA ROM PIPNG 60000 75000 60000 45000
Tabla 5.19 Pesos de Inserción de Palabras (PIP) estimados para los modelos D2 cuando no se utiliza gramática, para cada uno de los locutores de la base de datos
Anterior I Siguiente I Índice capítulo 5 I Índice General
| ISSN: 1139-8736 Depósito Legal: B-8714-2001 |