| ISSN: 1139-8736 Depósito Legal: B-8714-2001 |
5.3 Módulo Acústico (Algoritmo de Un Paso)
El algoritmo de reconocimiento de habla es una adaptación del conocido algoritmo de Un Paso, que ha probado ser más eficiente en coste computacional y en memoria que otros algoritmos conocidos (Dos Pasos, Constructor de Niveles) basados en Programación Dinámica. La idea fundamental es utilizar la información gramatical (sintáctica y léxica) para construir o generar un espacio de estados, en forma de autómata de estados finitos cuyo elemento (estado) básico es un estado de un modelo HMM, y cuya tabla de transiciones es el resultado de compilar el autómata de la gramática junto con el autómata de estados de la transcripción alofónica de cada palabra y el autómata de estados de Markov de cada uno de los alófonos de esa transcripción. Sobre esta red de estados de Markov (espacio de estados), el algoritmo de Un Paso debe encontrar la secuencia de palabras asociada a la secuencia de estados óptima, basándose en los principios de la Programación Dinámica.
Para poder reducir los cálculos del algoritmo de búsqueda, acelerando el proceso de reconocimiento, se ha incorporado un mecanismo de poda de caminos conocido como Búsqueda en Haz (Beam-Search). Este procedimiento está basado en calcular, para cada trama, el estado de la red con más alta probabilidad y aplicando un umbral (calculado empíricamente), marcar para no procesar aquellos estados cuya probabilidad queda fuera de ese margen. Con ello se consiguen reducciones del espacio de estados considerables sin llegar a afectar a la tasa de reconocimiento, es decir, sin aumentar los errores en el proceso de decodificación acústica.
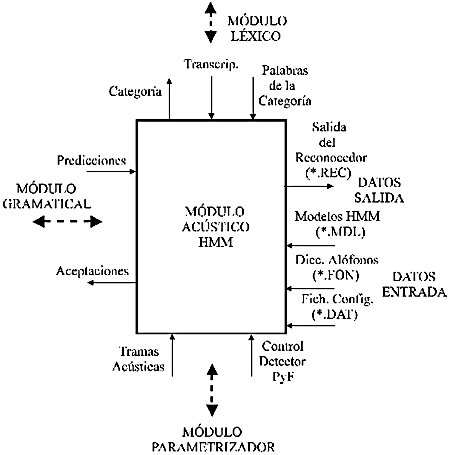
Al Módulo Acústico se le deben proporcionar los siguientes ficheros:
Fig.5.8 Módulo Acústico. Detalle de los datos de Entrada y de Salida.
Anterior I Siguiente I Índice capítulo 5 I Índice General
| ISSN: 1139-8736 Depósito Legal: B-8714-2001 |