Fig. III.10: Comparación de sistemas de herencia
ISSN: 1139-8736
3.3 Representación del conocimiento léxico
mediante estructuras de rasgos tipificadas: LRL-LKB
LRL (Copestake, 1992) es un lenguaje de representación del conocimiento desarrollado en el marco del proyecto Acquilex para representar una base de conocimiento léxico, LKB. Asimismo, en Castellón (1993) se describe con detalle la LKB y su uso para la codificación y el tratamiento del conocimiento léxico del español. En esta sección presentaré de forma somera dicho formalismo, siguiendo en parte a los autores citados y a Copestake and Briscoe (1995).
LRL (Lexical Representation Language, 'Lenguaje de Representación Léxica') es un lenguaje basado en estructuras de rasgos tipificadas (Carpenter, 1992) aumentado con reglas léxicas y de composición de signos y herencia por defecto. Como en todo lenguaje de estructuras de rasgos los objetos consisten en asociaciones de atributos y valores. En LRL, además, por basarse en estructuras de rasgos tipificadas, los valores son tipos elegidos de un conjunto bien definido y jerárquicamente estructurado. Un ejemplo de este tipo de formalización puede verse a partir del esquema de la fig. I.8, en donde los valores de los rasgos que definen la estructura del signo léxico gato_1 son tipos previamente definidos.
LKB (Lexical Knowledge Base, 'Base de Conocimiento Léxico') es la base de conocimiento léxico desarrollada utilizando los mecanismos de LRL. La entrada léxica de LKB es similar a la de HPSG (Pollard y Sag 1987, 1994). Consta de cuatro rasgos mayores: ortografía, sintaxis, semántica formal y semántica léxica, esta última basada en la teoría del Lexicón Generativo (Pustejovsky, 1995). La sintaxis se describe en LKB en términos de gramáticas categoriales, es decir, bien mediante categorías básicas de tipo atómico (p.e., N, V), bien mediante categorías complejas en las que dos categorías se hallan relacionadas por un operador de dirección (p.e. adjetivo = N/N). La semántica formal se describe mediante rasgos correspondientes a un predicado y a sus argumentos, más un índice ontológico del argumento. Respecto a la semántica léxica, describiré con detalle en §6 el marco de representación desarrollado por Pustejovsky; LKB implementa una adaptación del mismo, RQS, mediante una serie de rasgos que pueden ser vistos como conocimiento general asociado a los signos léxicos (p.e. forma, color, constitución, función, etc.).
Un ejemplo de una entrada de LRL-LKB puede ser visto en (13), la entrada del adjetivo 'blanco'. El rasgo CAT (sintaxis) define el adjetivo en español como un signo N\N, o signo que combina con un nombre que le antecede resultando la composición en un nuevo signo nominal. La semántica formal de 'blanco' descrita en SEM equivale a la fórmula 'entidad(x) Ù blanco(x)'. En dicha descripción se utiliza la reentracia o coindización de valores; como puede verse en el ejemplo, la utilización del símbolo de reentracia [1] indica que el argumento lógico del predicado 'blanco' es idéntico al del nombre. El rasgo ÍNDICE es indicativo del tipo semántico del argumento. Finalmente el rasgo FORMAL:COLOR recibe un valor de tipo blanco (definido en la estructura de tipos).
(13)
[ORT: "blanco"
CAT: [RESULTADO: n
DIRECCION: retroactiva
SIGNO ACTIVO: n]
SEM: [ÍNDICE: entidad
PREDICADO: Ù
ARGUMENTO 1: [PREDICADO: nombre
ARGUMENTO: x = [1] ]
ARGUMENTO 2: [PREDICADO: blanco
ARGUMENTO: [1]] ]
RQS: [FORMAL: COLOR: blanco]]
Además de los signos léxicos (nombre, verbo, adjetivo, etc.) se definen también signos complejos (phrasal signs), los cuales se obtienen a partir de la combinación de signos léxicos utilizando los mecanismos de composición de signos de LRL y las reglas definibles en dicho marco. El mecanismo fundamental que se utiliza es el de la unificación de estructuras de rasgos (cf. vid. Shieber, 1986, y Castellón, 1993), aunque otros mecanismos de composición pueden ser definidos mediante LRL. De este modo, LRL-LKB permite no tan sólo la representación del conocimiento léxico sino también el tratamiento de la composición sintáctica y semántica de las expresiones.
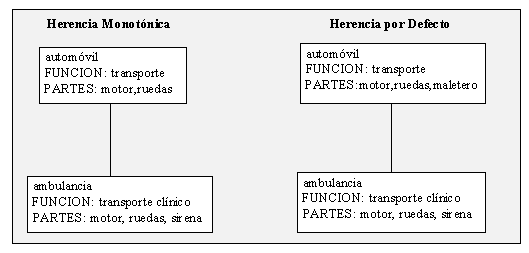
En LRL-LKB opera la herencia monotónica de información para el conjunto de la estructura de tipos, y además la herencia por defecto en el subconjunto de tipos constituido por los signos léxicos (o entradas). La diferencia entre ambos tipos de mecanismos de herencia es fundamentalmente la siguiente: en la herencia monotónica los objetos heredan de los que les son jerárquicamente superiores los rasgos de éstos, pudiendo únicamente realizar dos operaciones:
(i), acrecentar dicha información con nuevos rasgos (que sean
pertinentes);
y (ii), atribuir a los rasgos heredados valores más específicos que
los atribuídos en la estructura más general.
En cambio, en la herencia por defecto, es posible, por así decirlo, borrar o sobreescribir información presente en el objeto jerárquicamente superior, eliminando valores, o atribuyendo a los rasgos valores de tipo distinto -y no más específico- al de origen.
Fig. III.10: Comparación de sistemas de herencia
Dicha diferencia puede ser ejemplificada como en la fig. III.10. A la izquierda vemos como ambulancia hereda de modo monotónico los rasgos de automóvil, únicamente acrecentando el rasgo PARTES con un nuevo valor aporpiado: sirena y dando a FUNCIÓN un valor (transporte clínico) que es subtipo del presente en automóvil para el mismo rasgo (transporte). En la estructura de la derecha, la aplicación de un mecanismo de herencia por defecto permite el 'borrado' del rasgo maletero en los valores de PARTES para ambulancia, lo cual no sería posible manejando únicamente herencia monotónica.
Las reglas léxicas son fórmulas que generan una estructura de rasgos a partir de otra estructura de entrada. Su utilidad principal es la simplificación del lexicón de modo que no toda realización alternativa de un signo léxico deba estar presente de forma estática en la base de conocimiento. Así, mediante las reglas léxicas, pueden generarse a partir de las entradas léxicas iniciales, por ejemplo, formas flexivas ('ventana' ® 'ventanas'), derivados morfológicos ('ventana' ® 'ventanita') o extensiones de significado ('ventana' [objeto] ® 'ventana' [abertura] ). Un ejemplo simplificado de regla léxica es el de la pluralización nombres (14).
(14)
[IN: [ORT: cadena
CATEGORÍA: n = [1]
NÚMERO: singular]]
OUT: [ORT: cadena + 's'
CATEGORÍA: [1]
NÚMERO: plural]]
La aplicación de la regla de (14) generaría para cualquier entrada
nominal en singular una entrada en plural con la misma categoría sintáctica (extremo
éste expresado por la reentrancia de los valores del descriptor CATEGORÍA en las
estructuras de entrada y de salida) y una ortografía resultante de la concatenación de
la cadena original y el grafema 's'.
Como he apuntado antes, la entrada léxica de LKB se basa en parte en el marco formal propuesto por Pustejovsky (1991, 1995) -que describiré en §6-, aunque existen ciertos matices diferenciales. Por ejemplo los rasgos de la estructura de Qualia son tratados en su mayor parte en LKB como una descripción estática de propiedades, mientras que en Pustejovsky (op. cit.) son vistos como objetos semánticos activos susceptibles de intervenir en los procesos de composición de signos complejos. En todo caso, el lenguaje de representación, LRL, permite expresar -de hecho, implementar- la teoría de Pustejovsky (u otra teoría lingüístico-formal) del modo que se considere conveniente.
Representación del conocimiento léxico en WordNet y en LRL-LKB
Indudablemente, LRL-LKB es un formalismo más expresivo que las representaciones léxico-relacionales de WordNet o EuroWordNet, los cuales son subsumibles en el mismo.
En primer lugar, resulta obvio notar que las representaciones relacionales de WordNet son representables de modo directo mediante estructuras de rasgos como las de LRL-LKB; por ejemplo, la relación meronímica 'car'¬ 'blinker' de la fig. III.2 de §3.1 puede ser expresada como en (15):
(15)
car
[TIENE_PARTE: blinker]
Pero de hecho, de modo más general, es de destacar que una jerarquía léxico-conceptual como la de WordNet puede ser usada como base para la creación de las representaciones del conocimiento léxico de LRL-LKB. Considérese por ejemplo en la fig. III.11 una parte de la jerarquía de WordNet de la fig. III.2, aquí traducida al español.
Dado que los nodos de WordNet (los synsets) representan
conceptos, que pueden realizarse en diferentes unidades léxicas (sinónimos en contexto,
como 'coche' y 'automóvil' para el concepto {coche,automóvil}), dichos nodos pueden ser
tomados como tipos del modelo del conocimiento o interpretación del mundo de LRL-LKB -la
estructura de tipos-, y los lexemas en que se realizan dichos conceptos como las etiquetas
de los signos léxicos que refieren a dichas entidades.
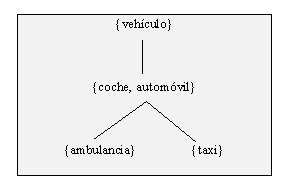
Fig. III.11: Taxonomía al estilo de WordNet
Así, la taxonomía de la fig. III.11 puede ser convertida en
la estructura de tipos (recuérdese, entidades del modelo del mundo, no signos léxicos)
de fig. III.12, en dónde el nodo {coche,automóvil} de WordNet se representa
mediante el tipo [COCHE], independientemente de sus realizaciones léxicas alternativas:
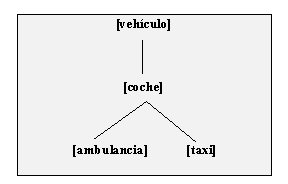
Fig. III.12: Estructura de tipos creada a partir de fig. III.11
Asimismo, a partir de la taxonomía de WordNet de fig. III.11
y en relación con la estructura de tipos de fig. III.12 puede crearse la
jerarquía léxica de LRL-LKB de la fig. III.13, en dónde la información asociada
a los signos expresará, como valor de ÍNDICE, la referencia del
signo al correspondiente tipo del modelo del mundo:
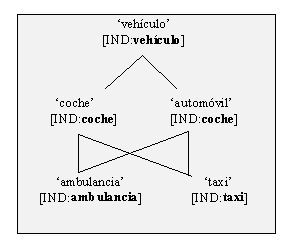
Fig. III.13: Jerarquía léxica a partir de fig. III.11 y III.12
Por otra parte, en LRL-LKB no es necesario realizar un completo
desarrollo en paralelo o casi en paralelo de las estructuras léxica y de tipos. De hecho
en los trabajos de Copestake (1992) y Briscoe y Copestake (1995), en aras de una mayor
economía de representación, el desarrollo de la estructura de tipos se reduce a los
niveles superiores de entidades, en relación a los cuales se describen las propiedades
semánticas básicas de los signos que las refieren, dejando para la estructura léxica y
la herencia (por defecto) que sobre ella se aplica la expresión completa de la
representación semántica de los signos hipónimos. Así por ejemplo, la estructura de
tipos de la fig. III.12 se reduciría a la de la fig. III.14:
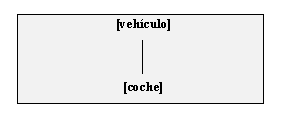
Fig. III.14: Estructura de tipos simplificada, como en Copestake (1992)
En cuanto a los signos léxicos se atribuiría a 'coche' -y a 'automóvil'- una estructura semántica básica, como por ejemplo la de (16):
(16)
['coche'
RQS: [IND: coche
FUNCIÓN: transporte
ORIGEN: artefacto]]
Y en función de ésta se completaría la estructura semántica correspondiente a los hipónimos léxicos, como p.e. en 'ambulancia' como en (17), en dónde la notación indica que la representación semántica de 'ambulancia' es la misma de 'coche' -luego la hereda- con la salvedad del rasgo FUNCIÓN, que adquiere para 'ambulancia' el valor transporte_clínico.
(17)
ambulancia
<RQS> < coche <RQS> <RQS FUNCIÓN> = transporte_clínico
La anterior definición formal de la entrada 'ambulancia' generará para el signo la estructura de rasgos de (18):
(18)
['ambulancia'
RQS: [IND: coche
FUNCIÓN: transporte_clínico
ORIGEN: artefacto]]
Otra posibilidad en la adaptación de un lexicón de WordNet a una base de conocimiento LKB puede ser la introducción en la estructura de tipos complejos, con el fin de obtener una representación que puede considerarse más adecuada de acuerdo con planteamientos teóricos. Por ejemplo, en el planteamiento de Pustejovsky (1995) -ver §6.1 y mi desarrollo de la semántica de los contenedores en §6.2.4- es deseable reducir la multiplicidad de significados relacionados de una palabra; para ello, la estructura de WordNet de la fig. III.15 puede sufrir una adaptación que, introduciendo un nuevo tipo, contenedor-contenido, permita la reducción de las entradas léxicas como en la fig. III.16.
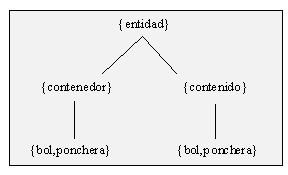
Fig. III.15: Estructura parcial de WordNet sobre nombres de
contenedores
Siguiendo el procedimiento de las fig. III.11 a
III.13, la estructura de la fig. III.16 -parte derecha- resultaría en dos
entradas léxicas para cada uno de los lexemas 'bol' y 'ponchera', uno con el significado
de contenedor (objeto) y otro con el de contenido (porción o cantidad contenida en el
objeto). Dado que éste constituye un caso típico de polisema regular (por metonimia,
todos los nombres de contenedor pueden denotar también el contenido), puede introducirse
un tipo complejo contenedor-contenido -ver parte izquierda de fig. III.16-
al que se atribuyan las características semánticas apropiadas que den cuenta de dicho
comportamiento polisémico, situando a continuación en el plano léxico a los lexemas
denotadores de contenedores de modo que hereden tales especificaciones:
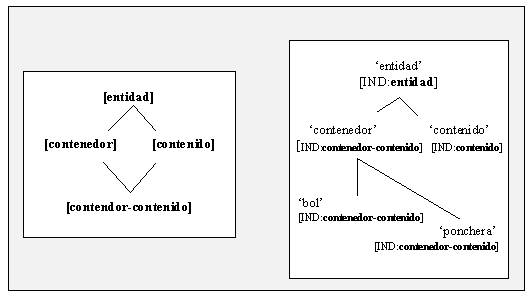
Fig. III.16: Adaptación de la estructura de Fig. III.15 a las
estructuras de tipos y léxica de LKB
En todo caso, la relación entre las representaciones tipo WordNet y las de LRL-LKB debe ser vista del modo antes sugerido: las segundas subsumen a las primeras, y un lexicón estructurado al modo WordNet puede ser usado como pauta o punto de partida para la realización de una base de conocimiento más estructurada como LRL-LKB. Por otra parte, como he comentado antes, LRL-LKB permite aplicar mecanismos de composición sintáctica y semántica a las entradas léxicas, construyendo así estructuras denotadoras de expresiones complejas. A los efectos de este trabajo, mediante LRL-LKB es posible dar cuenta de la información merológica, tanto si se realiza léxicamente como si se realiza, como en el caso de los sintagmas partitivos, sintagmáticamente -lo cual no es posible mediante un formalismo como el de WordNet-. Asimismo, como se verá en §7, el mecanismo de reglas léxicas resultará ser altamente explicativo en la tarea de definir las posibilidades combinatorias de los nombres partitivos. Por otra parte, la elección para este trabajo de LRL-LKB frente a otros formalismos similares es debida a que en este formalismo se han implementado -de forma no completa pero sí suficiente, y en todo caso ampliable en los aspectos necesarios- las representaciones propuestas por Pustejovsky (op. cit.), las cuales constituyen el marco formal en el que desarrollaré el núcleo central de mi trabajo.
Aproximación a la merología en el marco de LRL-LKB
La única aproximación al conocimiento parte-todo en el marco de LRL-LKB la han llevado a cabo Vossen y Copestake (1994) al tratar la recuperación automática de información léxica para la base de conocimiento a partir de diccionarios. En dicho trabajo no se trata la información meronímica ni se ofrece un tratamiento general de la composición del significado mediante sintagmas partitivos, pero sí se realiza una primera aproximación a la representación del significado de los nombres partitivos.
En la construcción de las entradas léxicas de la LKB a partir del análisis de las definiciones de diccionarios llevado a cabo en el proyecto Acquilex -en el que se enmarca el trabajo de Vossen y Copestake- la metodología habitual implica definir la estructura de un lexema dado de modo que herede la especificación semántica del lexema que, en la definición de diccionario, sea analizado como genus. Por ejemplo, a partir de una definición como la de (19), la entrada léxica de 'taxi' se declararía de modo que heredara las principales características semánticas de 'coche'.
(19) taxi: coche de alquiler provisto de un taxímetro (Casares, 1959)
Sin embargo, la existencia de entradas de diccionario como las de (20) no permiten la aplicación directa del método habitual, ya que el genus aparente es un nombre o una construcción partitiva:
(20)
a. root 1 : the part of a plant that...
(raíz 1: la parte de la planta que...)b. meal 1 : an amount of food eaten at one time.
(comida 1: una cantidad de alimento consumida de una vez)
Centrándose en patrones como los de (20b), cantidades de nombres de masa, los autores concluyen que dicho tipo de patrones 'producen un individual a partir de un genus que denota una masa, describiendo la manera en que dicha entidad resulta individuada'. Y postulan los siguientes efectos de representación en LKB:
(i) la nueva entrada pertenecerá al tipo que expresa entidades individuales (en su sistema el tipo lex-count-noun, nombre contable) en lugar de al tipo que expresa masas (lex-uncount-noun, nombre incontable);
y (ii) la nueva entrada heredará la totalidad de la estructura de qualia del genus excepto el rasgo FORM el cuál será el especificado por el patrón denotador de porción.
De este modo, al entrada para 'meal_1' deducida a partir de su
definición (20b) será la de (21), en dónde se indica que a la estructura de 'meal_1' se
le atribuye el tipo de nombre contable, y hereda la estructura semántico-léxica de
'food' ('comida') con excepción del rasgo QUALIA:FORM:RELATIVE, el cual recibe para
'meal_1' el valor portion (porción) -el valor de QUALIA:FORM para 'food' sería mass
(masa)-.
(21)
meal _1
lex-count-noun
< QUALIA > < food L_0_1+2 < QUALIA >
< QUALIA : FORM : RELATIVE > = portion.
La idea básica subyacente a este tratamiento es
equivalente en principio a una parte de la que desarrollaré en mi representación de los
partitivos, es decir, la aplicación de un nombre partitivo a un nombre de masa produce un
grupo denotador de una entidad individual. Sin embago, como veremos, muchos otros aspectos
de la semántica de este tipo de construcciones deben ser tenidos en cuenta para obtener
una representación adecuada: en general, ni toda la estructura semántico-léxica del
nombre del todo puede ser heredada de modo simple por la construcción partitiva, ni todas
las construcciones partitivas de porción se aplican necesariamente a nombres de masa (ver
capítulos §6 y §7).
Continuar
Volver al inicio del capítulo
Volver al índice
Climent S. (1999) Individuación e información Parte-Todo. Representación para el procesamiento computacional del lenguaje. Estudios de Lingüística Española (ELiEs).
ISSN: 1139-8736
Depósito Legal: B-8929-00