Tabla 1: Estadísticas generales. Ratio palabras/formas
| ISSN: 1139-8736 Depósito Legal: B-39120-2002 Copyright: © Chantal Pérez |
Este es el primer análisis básico que suele realizarse en cualquier corpus, independientemente del uso que se le quiera dar, ya que estas estadísticas nos dan información general sobre la composición del corpus y su tamańo. Este tipo de estadísticas no son muy significativas en sí mismas, pero es necesario tenerlas en cuenta, puesto que pueden influenciar el resultado de otras operaciones matemáticas que sean dependientes del tamańo o composición del corpus.
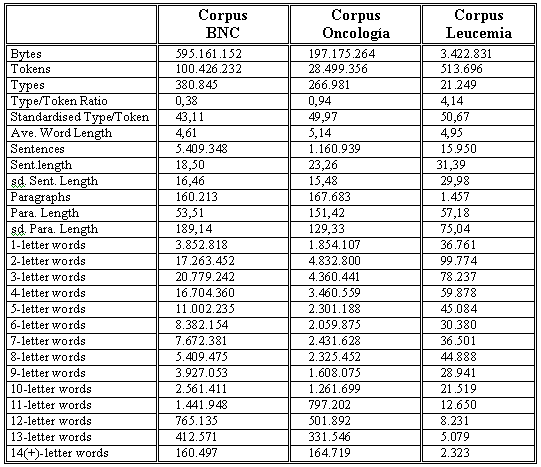
En la tabla que incluimos a continuación están contenidas las estadísticas generales de los tres córpora que hemos usado en nuestro estudio, en la que se muestra el número de bytes de cada uno, palabras (tokens), formas (types), junto con otros tipos de información como el número de oraciones, párrafos y longitud de las palabras que componen el corpus:
Como puede apreciarse, el número de tokens de los córpora corresponde al de palabras contenidas en el texto, tomando como palabra cualquier cadena de caracteres separada por espacios. En el caso de palabras unidas por un guión (p. ej. self-help), esta herramienta da la opción de contarlas como dos palabras separadas (la opción que hemos elegido) o considerarlas una sola. El número de types (formas) corresponde a las palabras diferentes que se encuentran en el texto, es decir, el BNC está compuesto por trescientas ochenta mil palabras diferentes que se repiten hasta conformar un corpus de cien millones de palabras.
La relación que existe entre ambas cifras se denomina ratio palabras/formas y se suele calcular siguiendo la formula siguiente:
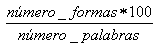
Aunque esta ratio puede ser indicativa de la variedad y riqueza léxica que se encuentra en un texto (a menor ratio, mayor riqueza léxica), el resultado de este tipo de cálculo depende en gran medida de la longitud del texto (cuanto menor sea la cantidad de palabras en el texto, mayor será la ratio). De ahí la gran diferencia que puede apreciarse entre la ratio de los tres córpora (0,38 en el BNC, 0,94 en el de oncología y 4,4 en el de leucemia) que, recordemos, difieren grandemente en cuanto al tamańo (100 m. de palabras el BNC; 28,5 m. el corpus de oncología y medio millón el de leucemia).
Sin embargo, WordSmith ofrece otro procedimiento para calcular la ratio palabras/formas que puede ser mucho más útil, puesto que primero calcula la ratio palabras/formas de cada segmento de texto de forma independiente (en nuestro caso cada 1000 palabras) y después establece la ratio media de todos los segmentos que componen el corpus. Por este procedimiento se obtiene la llamada standardised type/token ratio, que en el caso de nuestros tres córpora, sigue manteniendo diferencias significativas, aunque mucho menos acusadas: 43,11 en el BNC, 49,97 en el de oncología y 50,67 en el de leucemia.
Otra alternativa para calcular la riqueza léxica de un texto teniendo en cuenta la longitud del texto es la propuesta por Honoré (1979) en la fórmula siguiente:116

Aplicando esta fórmula obtenemos los siguientes índices de riqueza léxica, que demuestran que ésta es inversamente proporcional a la especificidad del corpus, es decir, el mismo hecho que nos mostraba la standardised type/token ratio:
|
BNC: 1333,9 Corpus de leucemia: 1238,1 Corpus de leucemia: 995,3 |
Aunque es difícil saber hasta qué punto dicha diferencia apunta a una menor riqueza léxica por parte de los textos más específicos sin que la longitud del corpus intervenga en forma alguna, la diferencia que se muestra entre la ratio y el índice de riqueza léxica del BNC y los del corpus de oncología, junto con la menor distancia que separa la ratio de éste último de la del corpus de leucemia parece apuntar en esa dirección.
Notas
116 Queremos agradecer al Prof. Chris Butler su ayuda a la hora de calcular esta fórmula y la siguiente en esta sección.
| ISSN: 1139-8736 Depósito Legal: B-39120-2002 Copyright: © Chantal Pérez |