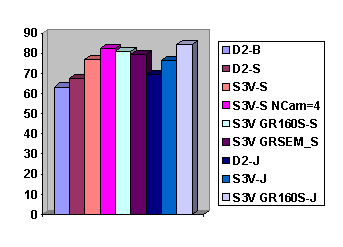
Fig. 5.33 Resultado de la evaluación de distintos sistemas. Para interpretar
correctamente la gráfica lea el gráfico de izquierda a derecha mientras lee la leyenda
de arriba abajo.
| ISSN: 1139-8736 Depósito Legal: B-8714-2001 |
5.4.4 Conclusiones Generales del Capítulo 5
Fig. 5.33 Resultado de la evaluación de distintos sistemas. Para interpretar correctamente la gráfica lea el gráfico de izquierda a derecha mientras lee la leyenda de arriba abajo.
En la figura 5.33 se presentan los resultados más significativos obtenidos durante el desarrollo y evaluación del Módulo Acústico. Como se puede observar en dicha gráfica, y a modo de resumen, se puede decir que han sido varios los sistemas desarrollados y evaluados, desde aquellos que no utilizan gramática pero incluyen información fonológica que mejora el modelado de las unidades a reconocer (palabras), pasando por distintos modelos de Markov (discretos y semicontinuos, con dos y tres codebooks), hasta distintas gramáticas morfosintácticas y semánticas, incorporando estrategias de obtención de N soluciones a la salida del reconocedor.
En el este capítulo hemos abordado el problema del reconocimiento de habla continua desde la perspectiva de la Programación Dinámica y los Modelos Ocultos de Markov. Se ha estudiado el diseño y la implementación de una arquitectura modular que permite incorporar gramáticas estocásticas, del tipo N-gramas, de cualquier valor de N, guiando al proceso de decodificación acústica (algoritmo de Un Paso). A pesar de la flexibilidad obtenida con la arquitectura diseñada de cara a la incorporación de conocimiento gramatical y también léxico (diccionarios lineales) hemos mantenido constantemente la preocupación por la eficiencia del sistema. Para ello se ha incorporado en el Módulo Acústico un mecanismo de poda conocido como “Búqueda en Haz” (“Beam Search”). Esta técnica es conocida y utilizada en multitud de sistemas, y consiste en determinar y aplicar un umbral de poda o recorte que elimine del espacio de búsqueda aquellos estados que no aportarán información relevante en la búsqueda de la solución (camino) óptima por parte del algoritmo de programación dinámica. La determinación del umbral es experimental y parece, a primera vista, no responder a ningún criterio de búsqueda del umbral salvo la tasa de acierto de palabra de los sistemas a los que se aplica. En esta tesis se ha analizado, en profundidad, la naturaleza de esta técnica, habiendo encontrado un método para determinar el umbral de recorte en base a un criterio concreto, fácil de controlar: la distribución del espacio de búsqueda formado por todos aquellos estados que pertenecerán al camino óptimo frente al resto de estados del espacio de búsqueda global. Esa distribución demuestra que, la mayor parte de los estados de los caminos óptimos de las frases del corpus se encuentran concentrados en torno a los estados más probables en cada instante de tiempo. Por tanto, si analizamos la distribución de los estados de los caminos óptimos para los datos de entrenamiento, y evaluamos la degradación que sufre la Tasa de Acierto de Palabra para esos mismos datos cuando aplicamos distintos umbrales, podremos determinar el umbral de recorte que consideremos más adecuado en cada caso, sabiendo la repercusión que tendrá sobre cualquier conjunto de datos de evaluación que utilicemos, y lo que es más importante, sobre el funcionamiento en condiciones reales del sistema. Se han desarrollado herramientas para el cálculo de los umbrales en función del recorte que sufre el espacio de estados óptimo y se han preparado los sistemas de reconocimiento para calcular histogramas que muestren la distribución de los distintos espacios de búsqueda. Además, la incorporación de una técnica de poda de caminos y el análisis del comportamiento de la misma nos ofrece la posibilidad de plantearse el proceso del espacio de búsqueda de forma dinámica, realizando los cálculos necesarios en cada trama, basándonos en un estadístico calculado en la trama anterior y reduciendo el número de recorridos que el proceso debe hacer sobre el espacio de búsqueda global, aumentando enormemente la eficiencia del sistema y permitiendo abordar el problema de la implementación en tiempo real. El cálculo del umbral para cada trama utilizando información de la trama anterior había sido propuesto anteriormente pero nunca había sido analizado y evaluado en profundidad. De los experimentos realizados en esta tesis, incluidos en este capítulo, se puede deducir que el incremento del cálculo (debido a la necesidad de aplicar umbrales mayores que obligan a procesar más estados de los necesarios) al utilizar un umbral basado en la trama anterior es pequeño frente a la reducción del cálculo inherente al propio proceso de “Búsqueda en Haz” (Beam-Search). Hemos estudiado diferentes tipos de gramáticas, morfo-sintácticas generales del castellano y semánticas, adaptadas al dominio de aplicación, analizando cobertura y perplejidad y sobre todo, la repercusión en la tasa de acierto de palabras del sistema. Parece que las gramáticas morfo-sintácticas producen un incremento de la tasa de acierto de palabras muy significativa aunque también un aumento del incremento de cálculo en el sistema. Se ha comprobado cómo el uso de Modelos de Markov de mayor calidad incrementa el porcentaje de acierto de palabras del sistema y además, permite ajustar mejor los umbrales de recorte o poda aplicados sobre el sistema, debido fundamentalmente a que entre los estados del camino óptimo y el resto de los estados las diferencias en probabilidad para cada trama se hacen mayores, es decir, los estados del camino óptimo se encuentran más alejados del resto de los estados del espacio de búsqueda. La incorporación de conocimiento fonológico en el Módulo Léxico (diccionario) del sistema aumenta significativamente la tasa de acierto de palabras del sistema aunque parece no ser relevante el modelar los nombre propios compuestos como una sola palabra. Este es otro modo de incorporar conocimiento gramatical en el sistema de reconocimiento de habla continua. Se han analizado estrategias de generación de N hipótesis de salida en el reconocedor, con el fin de estudiar el valor de N necesario para este tipo de aplicaciones con el que se obtiene una tasa de acierto de palabras final suficiente para un Módulo de Comprensión de Habla que reciba las frases reconocidas como entrada de lenguaje natural con algunos errores. Hemos comprobado que valores pequeños de N pueden suponer incrementos razonables de la tasa de acierto de palabras. |
Anterior I Siguiente I Índice capítulo 5 I Índice General
| ISSN: 1139-8736 Depósito Legal: B-8714-2001 |